Introduction
In today's business world, understanding client relationships between companies can provide valuable insights for market research, sales prospecting, and competitive analysis. This article will guide you through building a powerful application that automatically discovers and visualizes client relationships by intelligently scraping company websites using Firecrawl, organizing the data into a hierarchical tree structure, and presenting it through an interactive visualization powered by Streamlit and PyVis. Whether you're a business analyst looking to map industry connections or a developer interested in creating insightful data visualizations, this project combines web scraping, data processing, and interactive visualization techniques into a practical, real-world application.
Throughout this tutorial, we'll walk through each component of the system step by step, from setting up the semantic web scraping with Firecrawl to recursively building client relationship trees and creating an intuitive user interface with Streamlit. You'll learn how to extract structured client data from unstructured web content, implement efficient tree traversal algorithms, transform hierarchical data into interactive network graphs, and package everything into a polished web application that users can easily interact with. By the end of this article, you'll have a complete, deployable application that can generate comprehensive client relationship visualizations for any company with just a few clicks.
High-level Overview of the Application

Now that we've outlined what we'll be building, let's explore how the different pieces of our application work together. Our client relationship tree application combines several powerful technologies to create a seamless, end-to-end solution.
At the core of our architecture is Python, which serves as the foundation for all our components. The application consists of four main parts: a web scraper powered by Firecrawl, a tree builder for organizing client relationships, a visualization engine using PyVis and NetworkX, and a user interface built with Streamlit.
Firecrawl is an AI-powered web scraping API that understands website content beyond just the HTML structure. Unlike traditional web scrapers that need custom rules and code for each website, Firecrawl can identify client information across different website layouts because it understands the meaning of the content. This capability allows our application to work consistently across various company websites without requiring custom configuration for each one.
The components work together in a pipeline that transforms raw website data into an interactive visualization. When a user enters a company URL in the Streamlit interface, this triggers the ClientScraper to fetch data using Firecrawl. The results are passed to the ClientTreeBuilder, which recursively builds the relationship tree to the specified depth.
Once the scraper collects client data, the tree builder component organizes it into a hierarchical structure, with each company linking to its clients. This tree is then converted into a network graph using NetworkX and PyVis, which allows for interactive visualization with features like zooming, dragging, and highlighting connections.
Finally, Streamlit provides an intuitive web interface where users can input company URLs, adjust settings, and view the resulting relationship graphs without needing to understand the underlying code.
All these operations happen behind the scenes, with Streamlit managing the state of the application and displaying appropriate loading indicators while processing occurs. This architecture balances performance with user experience, allowing complex data processing to happen while keeping the interface responsive and easy to use.
Running the Application Locally
To run the Client Relationship Tree Visualization application on your local machine, follow these step-by-step instructions. This guide assumes you have Python 3.10+ installed on your system.
1. Clone the Repository
First, clone the repository from GitHub using the following commands:
git clone https://github.com/firecrawl/firecrawl-app-examples.git
cd firecrawl-app-examples/logo-tree-builder2. Set Up Poetry
This project uses Poetry for dependency management. If you don't have Poetry installed, you can install it by following the instructions on the official Poetry website.
Once Poetry is installed, set up the project environment:
# Create virtual environment and install dependencies
poetry installThis command will create a virtual environment and install all the dependencies defined in the pyproject.toml file, including Streamlit, Firecrawl, PyVis, and NetworkX.
3. Configure the Application
Before running the application, you'll need a Firecrawl API key. If you don't have one yet, you can sign up at firecrawl.dev to obtain your API key.
You can configure the API key in two ways:
- Enter it directly in the Streamlit interface when you run the application
- Create a
.streamlit/secrets.tomlfile in the project directory with the following content:
[firecrawl]
api_key = "your_firecrawl_api_key_here"4. Run the Application
Now you're ready to run the application using Poetry:
poetry run streamlit run streamlit_app.pyThis command will start the Streamlit server, and you should see output similar to:
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.x.x:8501Open the provided local URL in your web browser to access the application. You can now:
- Enter a company website URL
- Set the desired crawl depth and maximum clients per company
- Click "Build client tree" to generate an interactive visualization of the client relationships
5. Troubleshooting
If you encounter any issues:
- Ensure your Firecrawl API key is valid and has sufficient credits
- Check your internet connection as the application needs to make API calls
- For deep crawls, be patient as it may take some time to process multiple levels of relationships
- If you see memory errors, try reducing the maximum depth or clients per company settings
The application creates a temporary directory for visualization files, which are automatically cleaned up when the application restarts.
Implementing a Client Scraper
At the core of our application is the ClientScraper class located in src/scraper/client_scraper.py. This component handles the extraction of client information from company websites, serving as the foundation for our relationship mapping. The scraper is responsible for converting unstructured website content into structured data about company clients, which can then be used to build our relationship tree.
The ClientScraper uses Firecrawl, an AI-powered web scraping API, to understand and extract semantic information from websites. Unlike traditional web scrapers that rely on rigid HTML selectors or XPath expressions, Firecrawl can identify client information across different website layouts through its understanding of content meaning. This capability is implemented through a schema-based extraction approach:
class CompanySchema(BaseModel):
"""Schema for a company with its website URL."""
name: str = Field(description="The name of the company")
website_url: str = Field(description="The website URL of the company")
class ClientsSchema(BaseModel):
"""Schema for a list of clients of a company."""
clients: list[CompanySchema] = Field(description="A list of clients of the company")
firecrawl_app.scrape_url("https://firecrawl.dev", params={
"formats": ["extract"]
"extract": {"schema": ClientsSchema.model_json_schema()}
})Learn how to get started with Firecrawl in our crawling endpoint guide.
The scraper incorporates several efficiency features to optimize performance. It maintains a cache of previously scraped URLs to prevent redundant requests, normalizes URLs to handle variations (such as with/without www prefixes), and implements batch processing for multiple websites. These optimizations are crucial when building deeper relationship trees that could potentially involve hundreds of company websites.
Within our application architecture, the ClientScraper serves as the data acquisition layer, feeding into the ClientTreeBuilder (located in src/scraper/tree_builder.py), which recursively constructs the relationship hierarchy. This separation of concerns allows the tree builder to focus on the recursive traversal logic while delegating the actual data retrieval to the specialized scraper component. The clean interface between these components enables efficient tree construction even when dealing with complex, multi-level client relationships.
Building a Tree of Relationships
Having established our data acquisition layer with the ClientScraper, we now need a mechanism to recursively build a comprehensive tree structure that captures the hierarchical relationships between companies and their clients. This is where the ClientTreeBuilder class (located in src/scraper/tree_builder.py) comes into play, serving as the structural backbone of our application by transforming flat client data into a meaningful relationship hierarchy.
The ClientTreeBuilder orchestrates the complex process of recursively traversing client relationships to the specified depth while implementing several optimization strategies. At its core, the builder maintains a set of processed URLs to prevent cycles in the relationship graph, which is crucial when mapping real-world business relationships where companies might refer to each other as clients. This cycle detection ensures our application doesn't enter infinite recursion loops while building the tree. The tree builder also implements a configurable limit on the number of clients per company, which prevents exponential growth of the tree structure and keeps processing times manageable even for popular companies with numerous clients.
The heart of the tree builder is the _build_tree_recursive method, which implements a breadth-first traversal strategy at each level of the relationship hierarchy. For each company, it first fetches its immediate clients using the ClientScraper, then recursively processes each client's relationships up to the specified maximum depth. One of the key optimizations in this implementation is batch processing - instead of making individual requests for each client at a given level, the builder collects all client URLs at that level and processes them in a single batch operation using Firecrawl's batch_scrape_urls method, significantly reducing the number of API calls and improving performance.
Within our application's architecture, the ClientTreeBuilder bridges the gap between raw data acquisition and visualization, creating a well-structured tree of Company objects (defined in src/models/company.py) that can be easily traversed and converted into a network graph for visualization. This separation of concerns allows each component to focus on its specific responsibility: the scraper extracts client data, the tree builder creates the hierarchical structure, and the visualization components (which we'll explore next) transform this structure into an interactive graph. This modular design enhances maintainability and allows each component to be refined independently as the application evolves.
Converting the Relationship Tree into a Graph

With our hierarchical tree structure in place, the next step is to transform this data into an interactive, visually appealing network graph. This transformation is handled by the ClientGraphRenderer class (located in src/visualization/graph_renderer.py), which serves as the visualization engine of our application. The renderer takes the Company tree built by the ClientTreeBuilder and converts it into a network graph representation that users can interact with.
The graph renderer uses two powerful Python libraries: NetworkX for graph data manipulation and PyVis for interactive visualization rendering. This combination allows us to first construct a mathematical representation of the client relationships as a directed graph, then render it as an interactive HTML visualization with features like zoom, pan, and node selection. The renderer uses a recursive approach to traverse the company tree, adding each company as a node and each client relationship as a directed edge in the graph, preserving the hierarchical structure while allowing for a more flexible visual representation.
Visualization customization is a key focus of the renderer, offering features like color-coding to distinguish between different types of relationships, sizing nodes based on their importance in the network, and providing informative tooltips that display additional company details on hover. These visual cues help users quickly understand complex relationship patterns that might be difficult to discern from raw data alone. The renderer also implements physics-based layout algorithms that automatically position nodes to minimize edge crossings and highlight natural clusters in the relationship network.
The output of the graph renderer is an interactive HTML file that can be embedded directly in the Streamlit interface, creating a seamless user experience where relationships can be explored dynamically. This interactive visualization serves as the primary output of our application, presenting the results of our semantic web scraping and relationship analysis in an intuitive format that business users can easily navigate and extract insights from. By handling the complex transformation from hierarchical data to visual network, the graph renderer completes the data processing pipeline and prepares the results for presentation in the user interface.
Building the Streamlit UI
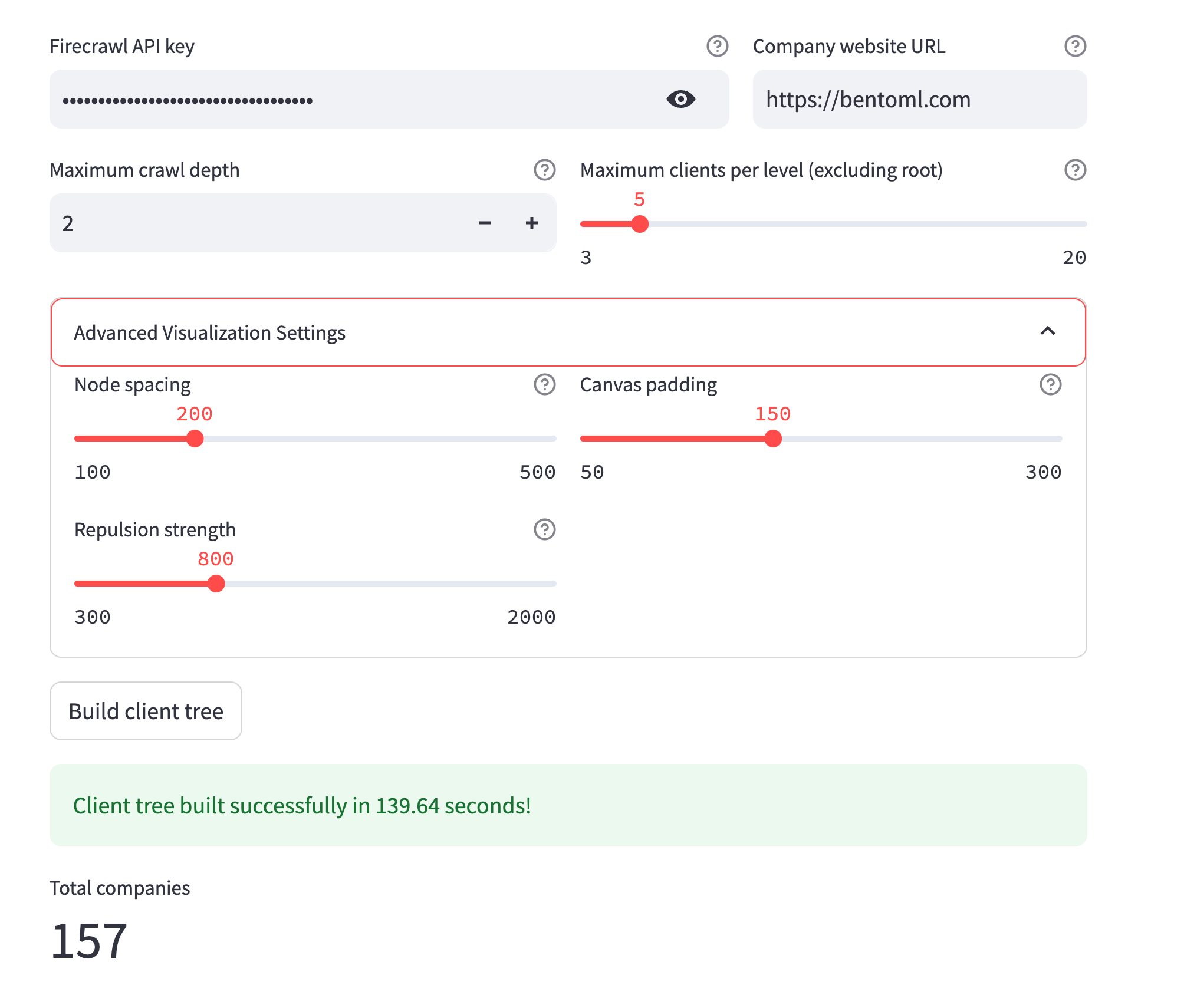
With our data acquisition, processing, and visualization components in place, we need a user-friendly interface to bring everything together. This is where Streamlit comes into play, allowing us to create an interactive web application without requiring extensive frontend development. The interface is implemented in the ClientTreeApp class (located in src/ui/app.py), which orchestrates the interaction between the user and our underlying components.
The Streamlit interface provides several key functionalities that make our application accessible to non-technical users. First, it offers a simple form for inputting the root company URL and configuring critical parameters like crawl depth and maximum clients per company. These parameters directly affect the tree building process, allowing users to balance between comprehensive analysis and processing time based on their specific needs. The interface also includes authentication management for the Firecrawl API, securely handling API keys while providing clear instructions for new users.
One of the most important features of our Streamlit interface is its ability to handle asynchronous operations gracefully. Building client relationship trees can take significant time, especially at deeper levels, so the UI implements progress tracking and status updates that keep users informed throughout the process. This is accomplished through Streamlit's session state management, which maintains context between interactions and allows for persistent display of results across application refreshes.
The final piece of our application is the integration of the visualization output directly within the interface. When the tree building process completes, the HTML visualization generated by the ClientGraphRenderer is embedded directly in the Streamlit page using an iframe component, creating a seamless experience where users can interact with the relationship graph without leaving the application. The interface also provides options for downloading the visualization or raw data in various formats, enabling users to incorporate the results into their own workflows or presentations.
Deployment Considerations
Now that we've built a complete client relationship tree application, let's explore how to deploy it for real-world use. Deploying this application requires careful consideration of several factors to ensure optimal performance, security, and cost-effectiveness.
The simplest deployment option is Streamlit Cloud, which offers a straightforward path to making your application accessible online. By connecting your GitHub repository containing the application code to Streamlit Cloud, you can have the application running with minimal configuration. This approach works well for demonstrations and smaller-scale usage scenarios. For applications requiring more customization or handling sensitive data, alternatives like Heroku, AWS Elastic Beanstalk, or Google Cloud Run provide more control over the deployment environment.
API key management is a critical consideration when deploying this application. The Firecrawl API key should never be hardcoded in your application but instead managed through environment variables or a secrets management system. In Streamlit Cloud, you can set these as secrets in the dashboard. For other platforms, use their respective secrets or environment variables systems. This approach ensures that sensitive credentials aren't exposed in your code repository while remaining accessible to the application at runtime.
Performance optimization becomes increasingly important as the application scales. Consider implementing caching at multiple levels: within the application (as we've already done with the ClientScraper cache), at the server level using Redis or similar technology, and potentially through CDN caching for static assets. For applications that experience heavy usage, you might want to decouple the UI from the data processing by implementing a task queue (using Celery or similar) that handles client tree building asynchronously, allowing the application to remain responsive even during complex operations.
Resource scaling is another important consideration. The recursive nature of client relationship discovery can potentially consume significant CPU and memory resources, especially for deeper trees or popular companies with many clients. Configure your deployment environment to set appropriate memory limits and consider implementing more aggressive client count limitations for public-facing deployments. Additionally, implementing rate limiting for the API is advisable to prevent abuse and manage costs associated with the Firecrawl API, which typically charges based on usage volume.
By addressing these deployment considerations, you can successfully transition your client relationship tree application from a local development environment to a production-ready service that can reliably support real-world usage patterns while managing resources efficiently.
Conclusion
In this article, we've built a powerful application that discovers and visualizes client relationships between companies. Our tool combines several technologies to create something useful: Firecrawl for intelligent web scraping, Python for data processing, and Streamlit for an easy-to-use interface. Anyone can use this application to map out business connections, find sales opportunities, or understand market relationships without needing technical skills. By entering a company's website URL and a few settings, users can generate interactive visualizations that reveal hidden connections between businesses that might otherwise take days of manual research to discover.
Looking ahead, there are several ways this application could be improved. We could add features like saving relationship maps for later use, comparing multiple company networks side by side, or analyzing changes in client relationships over time. The visualization could be enhanced with additional data like company size, industry classification, or financial information to provide more context. We could also improve performance for very large networks by implementing more sophisticated caching or using database storage for persistent results. Whether you use this application as-is or extend it with your own features, it provides a solid foundation for exploring and understanding the complex web of business relationships in today's interconnected market.

data from the web