Introducing our most accurate /search yet
Firecrawl /search now returns the excerpts that best answer your query from each result. Agents using it achieve state-of-the-art accuracy on SimpleQA while using 10x fewer tokens than processing full pages.
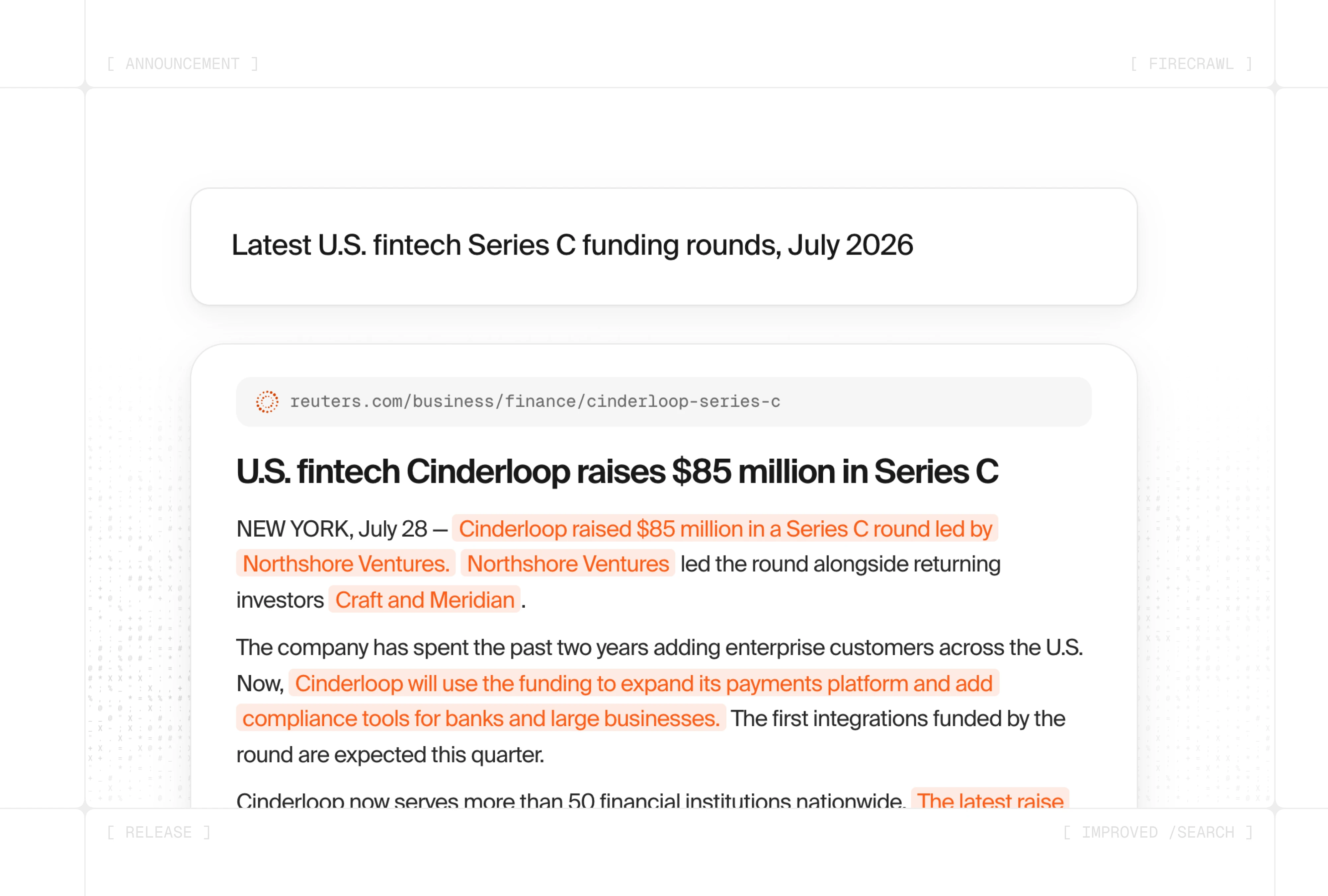
- Custom relevance model — A custom model scores every paragraph, list, and table against your query, returning the most relevant excerpts structured and ready for your agent to use.
- State-of-the-art accuracy on SimpleQA — Agents using Firecrawl
/searchscore 94.7% on SimpleQA, higher than any other provider. - 10x fewer tokens than full pages — The relevant excerpts returned by
/searchtake up far less of your agent's context window and are cheaper and faster to reason over. - Nothing to change in your code — The API shape is unchanged, so existing
/searchcalls get better results automatically.
Read the full announcement here.
Web-scale /monitor
Web-scale /monitor watches the entire web for you. Define search queries and a goal, and Firecrawl pings you or your agent the moment something new comes online.

- Always-on web search — Give
/monitorsearch queries and agoal, and it searches the entire web on your schedule, alerting you when something new matches. - Tune recall and precision —
queriescontrol what each search pulls in, whilegoaldecides which of those results actually alert. - Webhook or email delivery — Get pinged the moment something new matches, with a plain-English explanation of why it matters.
- One endpoint replaces the DIY stack — Define your query once. Firecrawl handles the search, deduplication, filtering, and alerts.
Read the full documentation here.
v2.11.0 is live
Firecrawl v2.11.0 ships the Firecrawl Research Index, keyless endpoint access, automatic PII redaction, a deterministicJson format, and video discovery on any page - plus much more.

- Firecrawl Research Index — Search across 3M+ arXiv papers and the GitHub code behind them (issues, merged PRs, and READMEs, refreshed daily), fetch a paper's details or related work, and check claims against full text. It has state-of-the-art recall on arXivQA, outperforming the next best provider by 18% at comparable cost.
- Keyless access for core endpoints — Use
/scrape,/search,/interact, and/parsewithout an API key from official MCP, CLI, and SDK clients. - Automatic PII redaction — A new
redactPIIoption strips personal and sensitive data like names, emails, phone numbers, addresses, and secrets out of scraped content before it's returned. deterministicJsonformat — Get structured JSON without running an LLM on every request. Firecrawl generates a reusable extractor for your schema and caches it per site, so repeat scrapes are cheaper and return consistent results.- Video discovery on any page — The
videoformat now finds videos on any page, not just supported providers like YouTube, returning each video's URL, title, thumbnail, duration, and more.
Read the full changelog here.
Firecrawl Research Index
Firecrawl Research Index is a specialized index for agents pushing the frontier of AI/ML research. It has state-of-the-art recall on arXivQA, outperforming the next best provider by 18% at comparable cost.
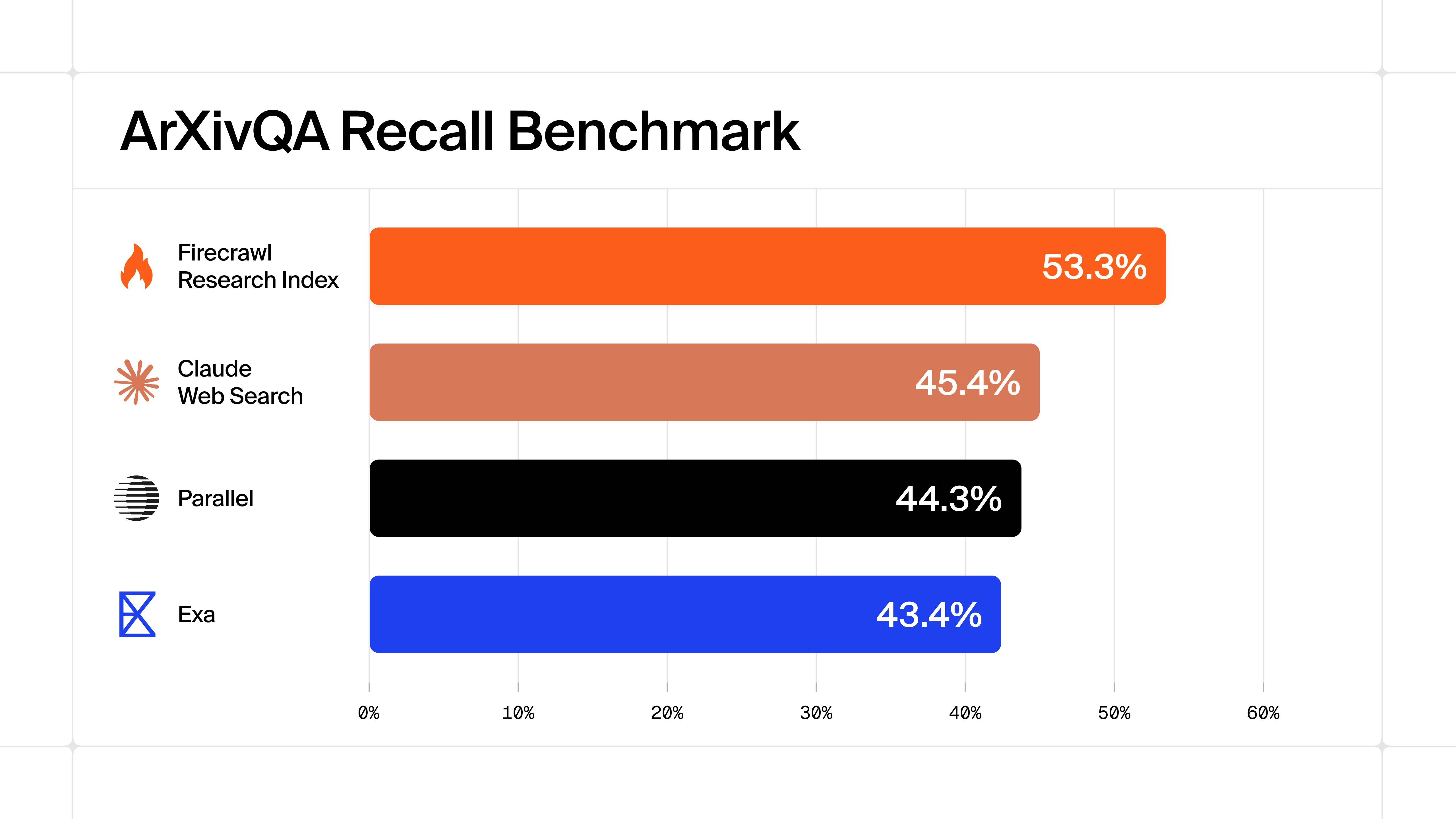
- Benchmark-leading performance — On arXivQA, the index hits 53.3% recall versus 45.4% for the next best provider. The index also scores 0.750 MRR, putting the right paper in the top one or two results.
- Search millions of papers alongside their code — The index includes 3M+ arXiv papers, plus GitHub artifacts from top research repos (issues, merged PRs, READMEs), refreshed daily.
- A complete toolset for research loops — Agents can retrieve papers, verify claims against full text, and pull code, going from literature to implementation with no manual review.
- Plugs into any agent harness — Works with Codex, Claude Code, Grok Build, and more.
Read the full documentation here.
Introducing /monitor
Enter a URL, describe what you want to track, and /monitor notifies your AI agent via webhook the moment pages or sites change. Use up to 90% fewer LLM tokens by only ingesting what actually changes.
- Set a goal in plain English — Describe what to watch, like "alert me when the Claude Code docs add new slash commands," and
/monitorconfigures the URLs, schema, and schedule for you. - Up to 90% fewer LLM tokens — Your agent only ingests what changes on a page, skipping unchanged content and noisy diffs.
- Any cadence, with cost upfront — 5 minutes, hourly, daily, or a custom cron schedule. The estimated monthly cost is shown before you turn a monitor on, so you know what you're committing to.
- Webhook or email delivery — Every change fires a signed webhook with custom headers and per-event subscriptions, or arrives by email with the diff in the body.
- Permalinks for every change — Diffs are first-class objects you can share with a teammate or hand straight to another agent.
Read the full documentation here.
v2.10 is live
Firecrawl v2.10 ships a new /parse endpoint, Lockdown Mode, Question and Highlights formats, and four new official SDKs (Go, Ruby, PHP, .NET) - plus a long list of reliability and security fixes.

/parseendpoint — Upload PDFs, Word docs, and spreadsheets up to 50 MB and get clean, LLM-ready Markdown, JSON, or summaries back. Powered by a new Rust-based engine that's up to 5x faster.- Lockdown Mode — Set
lockdown: trueon/scrapeto serve results exclusively from Firecrawl's index with no outbound requests and zero data retention by default. Available everywhere, including the CLI (--lockdown) and MCP. - Question Format — Pass a natural-language prompt to
/scrapeand get a grounded answer back, with up to 100x fewer tokens per call. - Highlights Format — Get back the exact sentences, code blocks, and table rows on a page that match your query, with original formatting preserved — also using up to 100x fewer tokens per call.
- Four New Official SDKs — Go, Ruby, PHP (with Laravel support), and .NET all joined the SDK family with v2 parity. The Rust SDK has been promoted to the official v2 SDK.
Read the full changelog here.
Highlights Format
Highlights is a new format for /scrape that returns the exact sentences, code blocks, and table rows on a page that match your query, all while using up to 100x fewer tokens.

- Citable, hallucination-free output — Nothing in the response is rewritten, translated, or hallucinated. Every sentence is provably from the source page, in the page's own words.
- Code blocks and tables preserved — Consecutive sentences from the same block re-join into paragraphs, consecutive code lines wrap in fenced blocks with their original language, and table rows rebuild into Markdown tables with headers auto-included.
- Up to 100x fewer tokens per call — Returning just the matching lines instead of the full page lowers inference costs, speeds up responses, and keeps your context window lean.
Read the full documentation here.
See the benchmark here.
Question Format
Question is a format for /scrape that returns high-quality, grounded answers from any web page using up to 100x fewer tokens.
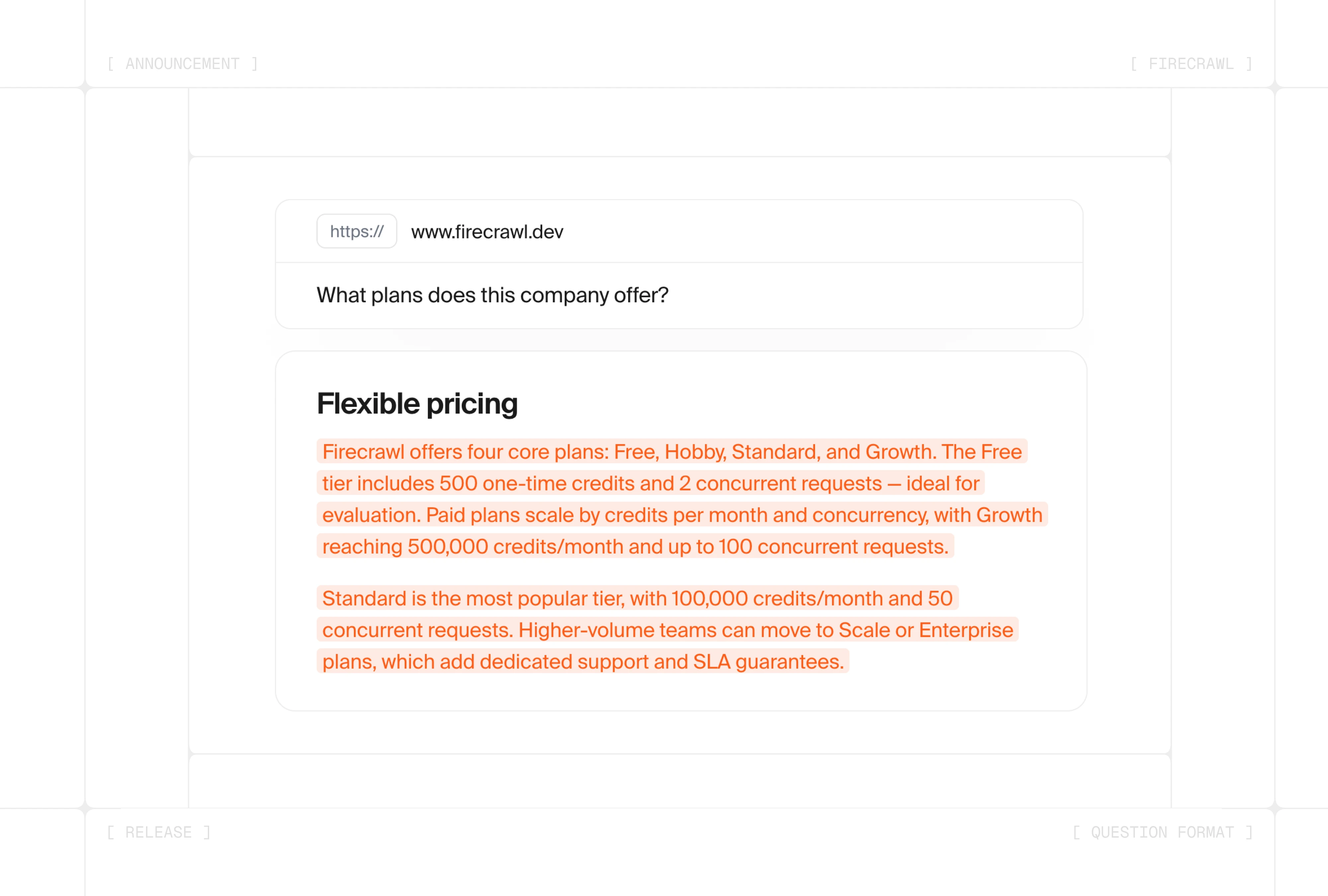
- High-quality, grounded answers —
questionpulls the page content most relevant to your prompt and answers strictly from it, with zero hallucinations. - Up to 100x fewer tokens per call —
questionreturns just the answer, not the page, giving you significantly lower inference costs, faster responses, and a leaner agent context window on every request. - Built for AI agents — Skip the scrape-parse-prompt pipeline. Drop precise, page-grounded answers straight into agent loops with a single call.
- Fully managed LLM stack —
questionruns on a managed model chain with automatic fallback and a production-tuned system prompt. Token usage and cost roll into the same billing surface as/scrape. - Hardened against prompt injection — Page content is isolated with XML tagging and zero-width-space escaping, and the model is instructed to ignore any instructions embedded in the page.
Read the full documentation here.
Lockdown Mode
Lockdown Mode is a cache-only option for /scrape that keeps security-sensitive requests inside Firecrawl. Set lockdown: true to serve results exclusively from Firecrawl's index, with zero data retention by default.
- No outbound request - Lockdown serves results from Firecrawl's index only and gates every outbound path, including HTTP and robots.txt.
- Zero data retention by default - URLs aren't persisted, response data isn't stored, and the scrape job is cleaned up after delivery.
- One flag, every surface -
lockdown: trueworks the same across the API, every SDK (Python, Node, Go, Rust, Java, .NET, Ruby, PHP, Elixir), the CLI (--lockdown), and MCP.
Read the full documentation here.
Introducing /parse
The /parse endpoint turns documents into clean, structured data for AI agents and RAG pipelines. Powered by a new Rust-based engine that's up to 5x faster, it works across PDFs, Word docs, spreadsheets, and more.

- Clean, LLM-ready output — Get back Markdown, JSON, or a summary, with tables and reading order preserved. No post-processing required.
- Rust-based engine — A high-performance Rust core delivers up to 5x faster parsing, cutting latency in document ingestion and embedding workflows.
- Zero Data Retention support — Enterprise plans with ZDR enabled ensure parsed output is never stored, so data from contracts, medical records, and internal reports stays secure.
- Upload files up to 50 MB — Supports PDF, DOCX, DOC, ODT, RTF, XLSX, XLS, and HTML.
View the full documentation here.
Introducing web-agent
Firecrawl web-agent is an open framework for building AI agents that search, scrape, and interact with the web. Powered by the same architecture behind our /agent endpoint.
- Bring any model — Anthropic, OpenAI, Google, or your own. You control the logic, tools, and infra.
- One command, full stack —
$ firecrawl create agentgives you/scrape,/search, and/interactin a plan-act loop, parallel sub-agents for concurrent research, and your choice of Streaming UI, API server, or library templates. - Teachable by design — Add Skill playbooks and your agent learns reusable routines. Paginate e-commerce sites, run multi-source research, and extract structured data your way.
Start building here.
Introducing Fire-PDF
Fire-PDF is a Rust-based parsing engine that converts any PDF - scanned, text-based, or mixed - into structured markdown, up to 5x faster.

- 5x Faster — Our open-source Rust library pdf-inspector classifies each page in milliseconds and picks the fastest extraction path. Pages are processed in under 400ms on average.
- Layout-Aware Accuracy — A neural document layout model detects tables, formulas, text blocks, and headers individually. Tables get full markdown output, formulas are preserved in LaTeX, and reading order is predicted neurally.
- Zero Configuration — Every PDF sent through Firecrawl's API now goes through Fire-PDF automatically.
Read the full blog here.
v2.9.0 is live
Firecrawl v2.9.0 includes browser interaction via /interact, new scrape formats, smarter PDF handling, two new SDKs, and a long list of reliability fixes.

- Browser Interaction via
/interact— Scrape a page, then call/interactto click buttons, fill forms, navigate, or extract dynamic content. Use natural language or write Playwright / Bash code for full control. Sessions persist across calls with live view URLs and reusable browser profiles. - Question Format — Pass a natural-language prompt to
/scrapeand get a direct answer back indata.answer. - Audio Format — Request audio output from any scrape, returned as a field on the document.
onlyCleanContentParameter — Strip navigation, ads, cookie banners, and other non-semantic content from markdown output in a single flag.- PDF Parsing Modes — Choose
fast,auto, orocrparsing with amaxPagesoption for fine-grained extraction control. - Java & Elixir SDKs — Official SDKs with full v2 API support, joining JS, Python, Go, and Rust.
Read the full changelog here.
Introducing /interact - Scrape and Automate Actions With Agents
Scrape any page, then let your agent dive deeper into what it finds. The new /interact endpoint turns any scrape into a live browser session where your agent can click, type, and navigate - all in natural language.
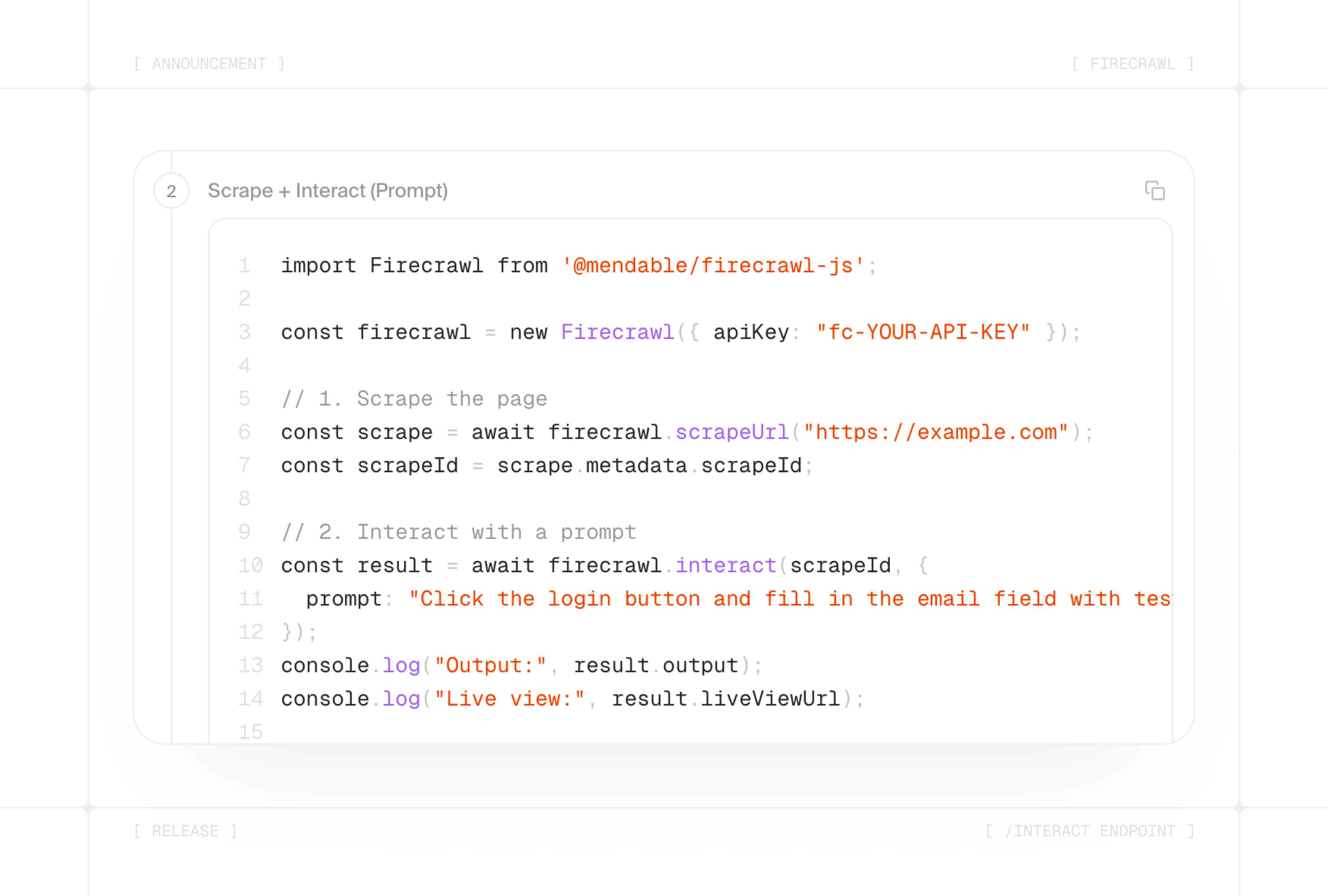
- Natural Language Control - Describe what you want in plain English. The agent clicks, types, scrolls, and extracts data automatically. No selectors, no scripts.
- Live Browser Sessions - Every session includes a live URL you can embed, share, or interact with in real time. Build browser-powered UIs, debug visually, or demo workflows.
- Persistent Profiles - Log in once and pick up wherever you left off. Cookies, localStorage, and session state carry across scrapes with named profiles - no re-authenticating, no lost state.
- Full Playwright Control - Need precision? Switch to code mode and run Playwright (Node.js or Python) or Bash with agent-browser in the same session.
- Session Reuse - Chain multiple interact calls on the same scrape. The browser stays open and maintains state between calls, so complex multi-step workflows just work.
View the full documentation here.
Firecrawl Java SDK
Full support for our core endpoints, including scrape, search, and crawl. Works with Maven, Gradle, Java 17+.

- Maven & Gradle Ready - Drop into any Java project via JitPack with standard dependency management.
- Java 17+ Support - Built for modern Java environments.
- Core Endpoint Coverage - Scrape, search, crawl, map, and agent all supported.
View the full documentation here.
Faster, Smarter PDF Parsing
Our new PDF parsing engine delivers 3x faster parsing and significantly improved reliability.
Rebuilt in Rust, it automatically adapts to any PDF - from clean text files to scanned reports and complex layouts - ensuring agents receive complete, accurate data every time.
- Rust-Based Parser - A new high-performance engine built in Rust delivers up to 3x faster parsing, dramatically reducing latency in data ingestion and embedding workflows.
- Three Parsing Modes - Choose the right balance of speed and completeness:
fast- text-only parsing with the Rust engine for maximum performance.auto- the new default; starts in fast mode and automatically falls back to OCR when needed. Auto intelligently detects when PDFs require OCR even if they appear text-based, handling edge cases like embedded images, graphs, multi-column layouts, and unusual text encodings.ocr- forces OCR parsing for fully image-based or scanned documents.
- Built for Production Reliability - Extensively tested across thousands of real-world PDFs to ensure consistent, accurate extraction in production environments.
Read the full blog here.
Introducing Browser Sandbox
Browser Sandbox gives your agents a secure, fully managed browser environment for interactive web automation. No local setup, no Chromium installs, no driver compatibility issues. Each session runs in an isolated, disposable sandbox that scales without managing infrastructure.
- Browser Sandbox - Launch secure, isolated browser sessions with Python, JavaScript, and bash execution. Pre-installed with agent-browser CLI and Playwright.
- Multi-Language Support - Execute Python, JavaScript, or bash code remotely. Send commands via API, CLI, or SDK and get results instantly.
- agent-browser Integration - Pre-installed CLI with 40+ commands. AI agents write simple bash commands instead of complex Playwright code.
- Live View & CDP Access - Watch sessions in real time via embeddable stream URL or connect your own Playwright instance over WebSocket.
- Session Management - Configurable TTL controls, parallel sessions (up to 20 concurrent), and automatic cleanup. 2 credits per browser minute with 5 minutes free.
Read the full documentation here.
Improved Logo Extraction for Branding Format v2

We significantly improved logo extraction accuracy for Branding Format v2, our endpoint for extracting brand identities from websites.
- Significantly improved logo detection: Logo extraction is now far more reliable, with fewer false positives and better handling of edge cases like logos embedded in background images.
- Works with modern site builders: Branding Format now properly detects logos built with Wix, Framer, and other drag-and-drop platforms that generate complex or non-semantic HTML.
- Built for AI agents and developers: Branding Format goes beyond logos - capturing colors, typography, spacing, and UI components in a structured format to power AI agents and apps.
Read the full blog here.
v2.8.0 is live
Firecrawl v2.8.0 brings major improvements to agent workflows, developer tooling, and self-hosted deployments across the API and SDKs.
- Parallel Agents - Execute thousands of
/agentqueries simultaneously with automatic failure handling and intelligent waterfall execution. Powered by Spark 1 Fast for instant retrieval, automatically upgrading to Spark 1 Mini for complex queries requiring deeper research. - Firecrawl Skill - Enables agents to use Firecrawl for web scraping and data extraction, install via
npx -y firecrawl-cli@latest init --all --browser. - Firecrawl CLI - Command-line interface with full scrape, search, crawl & map support, install via
npm install -g firecrawl-cli. - Spark Model Family - Three new models powering /agent: Spark 1 Fast for instant retrieval (currently only available in Playground), Spark 1 Mini for complex research queries, and Spark 1 Pro for advanced extraction tasks.
- Agent Enhancements - Webhook support, model selection, and new MCP Server tools for autonomous web data gathering.
Read the full changelog here.
Parallel Agents: Extract Web Data at Scale
We're bringing parallel processing to /agent, letting you batch hundreds or even thousands of queries simultaneously. What took hours of sequential agent queries now completes in minutes with automatic failure handling and parallel execution.
Try it in the Agent Playground - the playground automatically determines when your use case is a good fit for Parallel Agents.

- Parallel Batch Processing: Run thousands of /agent queries simultaneously to enrich companies, research competitors, or build product datasets at scale.
- Intelligent Waterfall: Tries instant retrieval first, then automatically upgrades specific cells to full agent research (Spark One Mini) only when needed.
- Real-Time Spreadsheet Interface: Work in familiar CSV format with instant visual feedback as cells populate in real-time.
- Zero Configuration: Input your data schema, write one prompt, hit run. No workflow building required.
- Predictable Pricing: 10 credits per cell with Spark-1 Fast.
Read the full blog here.
Introducing the Firecrawl Skill & CLI
 We're introducing the Firecrawl Skill and CLI, a new way for AI agents to reliably access real-time web data on their own. With a single install, agents like Claude Code, Antigravity, and OpenCode can access all of your favorite Firecrawl endpoints - including scrape, search, crawl, and map for any use case you need.
We're introducing the Firecrawl Skill and CLI, a new way for AI agents to reliably access real-time web data on their own. With a single install, agents like Claude Code, Antigravity, and OpenCode can access all of your favorite Firecrawl endpoints - including scrape, search, crawl, and map for any use case you need.
Install with $ npx -y firecrawl-cli@latest init --all --browser and learn more in our docs.
- One-Command Install: Install the skill with a single command and teach agents how to install, authenticate, and use all of Firecrawl's powerful end-to-end.
- Real-Time Web Data at Runtime: Agents can pull fresh, full-page content from docs, product pages, pricing, and articles exactly when they need it.
- Context-Efficient for Agents: Uses a file-based approach for context management and bash methods for efficient search and retrieval.
- Works Across Complex & Dynamic Sites: Powered by Firecrawl's custom browser stack to reliably extract complete data from large, JavaScript-heavy sites.
- Proven, Best-in-Class Coverage: Backed by benchmark results showing >80% coverage across real-world evaluations.
Read the full blog here.
v2.7.0 is here!
- ZDR Search Support - Enterprise customers can now search with Zero Data Retention enabled end to end. If you're interested, contact alex@firecrawl.dev to enable for your team.
- Partner Integrations API - Available in closed beta for native integrations. Get in touch with us at partnerships@firecrawl.dev if you are intested in offering Firecrawl as a native integration in your product.
- Improved Branding Format - Better detection and support across all platforms.
- Faster Screenshots - Enhanced viewport and full page screenshots with improved speed and accuracy.
- Self-hosted Improvements - Significant enhancements for deployments and infrastructure.
- Performance Enhancements - Platform-wide improvements for better user experience.
Read the full changelog here
v2.6.0 available now
- Unified Billing Model - Credits and tokens merged into single system. Extract now uses credits (15 tokens = 1 credit), existing tokens work everywhere.
- Enhanced Branding Format - Full support across Playground, MCP, JS and Python SDKs.
- Reliability and Speed Improvements - All endpoints significantly faster with improved reliability.
- Instant Credit Purchases - Buy credit packs directly from dashboard without waiting for auto-recharge.
- Improved Markdown Parsing - Enhanced markdown conversion and main content extraction accuracy.
- Change Tracking - Faster and more reliable detection of web page content updates.
- Core Stability Fixes - Fixed tons of core stability issues, PDF timeouts, and improved error handling.
Read the full changelog here
v2.5.0 - The World's Best Web Data API

Today, we're excited to announce Firecrawl v2.5, which delivers the highest quality and most comprehensive web data API available. This release represents a significant leap forward in web data extraction, powered by two major infrastructure improvements: our new Semantic Index and a completely custom browser stack.
See the benchmarks below:
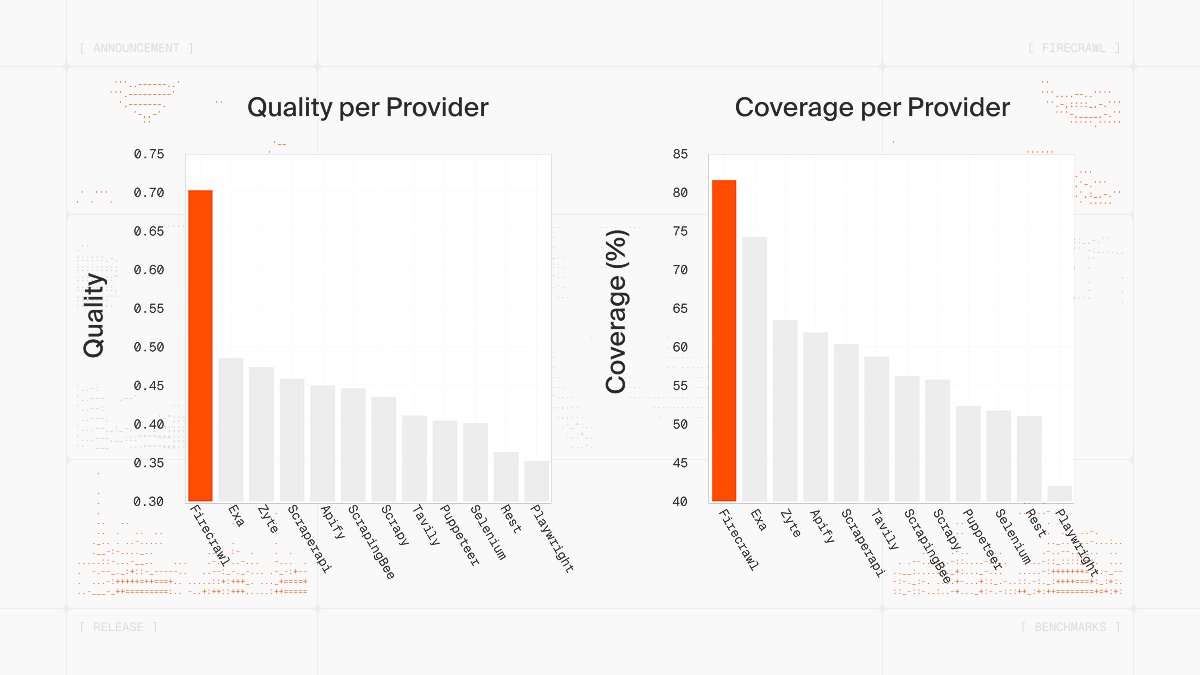
We've open-sourced these benchmarks! Check out scrape-evals, our reproducible framework for testing web scraping engines on 1,000 real URLs.
-
Open-Source Scrape-Evals Benchmark
We've released scrape-evals, an open-source benchmark testing 13 web scraping engines on 1,000 real URLs for coverage and quality. -
Full-Page, High-Quality Extraction
Improved browser stack ensures complete and consistent data from any type of website. -
Semantic Index for Faster Results
Retrieve either fresh data or a previously indexed snapshot with faster speeds and increased coverage. -
5x Cheaper Search & New Credit Packs
Search is now 5x cheaper and now every plan has an auto-recharge credit pack sized to match your scale. -
Smarter Concurrency & Crawl Architecture
New crawling system improves throughput, reliability, and queue fairness across large workloads. -
Excel (.xlsx) Scraping Support
Extract clean data directly from spreadsheets or csv files.
Firecrawl v2.5 is available now for all users - no code changes required. You can start experiencing the improved quality and coverage today:
- Experiment in our interactive playground
- Review the complete documentation
- Sign up to integrate Firecrawl into your applications
We're excited to see what you build with the world's most reliable web data API.
Read more about it in our blog post here and view the full changelog here
v2.4.0 is live now
- New PDF Search Category - Search specifically for PDF documents using our v2/search endpoint with the new 'pdf' category filter
- 10x Better Semantic Crawling - Improved accuracy and relevance when crawling with a prompt
- New x402 Search Endpoint - Our search API available via Coinbase x402 integration
- Fire-enrich v2 Example - AI-powered data enrichment tool that transforms emails into rich datasets. See repo
- Enhanced Crawl Status & Warnings - Real-time status updates with clear feedback for robots.txt limitations and low-result scenarios
- 20+ Self-Host Improvements - Major stability and functionality upgrades for self-hosted deployments
Read the full changelog here
Firecrawl v2.3.0 is here
- YouTube transcript support
- Added odt & rtf parsing support
- Docx parsing is ~50x faster
- Enterprise Auto-Recharge
- Playground UX improvements
- Self hosting improvements
Read the full changelog here
Firecrawl v2.2.0 is here
- MCP version 3 is live. Stable support for cloud mcp with HTTP Transport and SSE modes. Compatible with v2 and v1 from.
- Webhooks: Now we support signatures + extract support + event failures
- Map is now 15x faster + supports more urls
- Search reliability improvements
- Usage is now tracked by API Key
- Support for additional locations (CA, CZ, IL, IN, IT, PL, and PT)
- Queue status endpoint
- Added
maxPagesparameter to v2 scrape API for pdf parsing
Read the full changelog here
Firecrawl v2.1.0 is here
- Search Categories: Filter search results by specific categories using the
categoriesparameter:github: Search within GitHub repositories, code, issues, and documentationresearch: Search academic and research websites (arXiv, Nature, IEEE, PubMed, etc.)- More coming soon
- Image Extraction: Added image extraction support to the v2 scrape endpoint.
- Data Attribute Scraping: Now supports extraction of
data-*attributes. - Hash-Based Routing: Crawl endpoints now handle hash-based routes.
- Improved Google Drive Scraping: Added ability to scrape TXT, PDF, and Sheets from Google Drive.
- PDF Enhancements: Extracts PDF titles and shows them in metadata.
- Map endpoint supports up to 100k results.
Read the full changelog here
Introducing Firecrawl v2
-
Faster by default: Requests are cached with maxAge defaulting to 2 days, and sensible defaults like blockAds, skipTlsVerification, and removeBase64Images are enabled.
-
New summary format: You can now specify "summary" as a format to directly receive a concise summary of the page content.
-
Updated JSON extraction: JSON extraction and change tracking now use an object format. The old "extract" format has been renamed to "json".
-
Enhanced screenshot options: Use the object form.
-
New search sources: Search across "news" and "images" in addition to web results by setting the sources parameter.
-
Smart crawling with prompts: Pass a natural-language prompt to crawl and the system derives paths/limits automatically. Use the new crawl-params-preview endpoint to inspect the derived options before starting a job.
Read the full changelog here
Firecrawl v1.15.0 is here
We're excited to announce the release of Firecrawl v1.15.0, packed with tons of improvements, bug fixes and enterprise features.

- SSO for enterprise
- Improved scraping reliability
- Search params added to activity logs
- FireGEO example (Open Source FireGEO). See repo
- And over 50 PRs merged for bug & improvements 🔥
Read the full changelog here
Firecrawl v1.14.0 is here
We're excited to announce the release of Firecrawl v1.14.0, packed with cool updates.

- Authenticated scraping (Join the waitlist here)
- Zero data retention for enterprise (Email us at help@firecrawl.com to enable it)
- Improved p75 speeds
- New MCP version w/ maxAge + better tool calling
- Open Researcher Example (Open Source Researcher). See repo
- And so much more. Check out here for all the details 🔥
Firecrawl v1.13.0 is here
We're excited to announce the release of Firecrawl v1.13.0, packed with awesome features.

- Added AU, FR, DE to Enhanced Mode
- Crawl subdomains with allowSubdomains
- Google slides scraping
- Generate a PDF of the current page. See docs
- Higher res screenshots with quality param
- Weekly view for usage on the dashboard
- Fireplexity Example (Open Source Perplexity). See repo
- And more!
Firecrawl v1.12.0 is here
We're excited to announce the release of Firecrawl v1.12.0, packed with new features.

- New Concurrency System - Specify max concurrency by request in crawl and batch scrape for better control. See docs.
- Crawl Entire Domain Param - Follow internal links to sibling or parent URLs, not just child paths (prev. allowBackwardLinks). See docs.
- Google Docs Scraping - We now officially support scraping Google Docs files
- Improved Activity Logs - Better support for FIRE-1 requests. See your logs here.
- /search Playground Enhanced - Location Params added. Check out the playground.
- Firestarter Example - Open Source Chatbot building platform. Repo here.
- Plus tons of performance improvements and bug fixes.
Firecrawl v1.11.0 is here
We're excited to announce the release of Firecrawl v1.11.0, packed with major performance improvements and new features.

Major Updates:
- Firecrawl Index: 500% faster scraping speeds when opted in. See docs for more details.
- Enhanced Activity Logs:
- View webhook events
- See and manage active crawls
- Fire Enrich Example: New open-source Clay integration. Open Source repository here.
- Community Java SDK: Expanding our SDK support. View repository.
- And many more improvements!
Introducing Search
We're excited to announce the launch of our new Search API endpoint that combines web search with Firecrawl's powerful scraping capabilities.

Key Features:
- Search the web and get full content from results in one API call
- Choose specific output formats (markdown, HTML, links, screenshots)
- Customize search parameters (language, country, time range, number of results)
- Full SDK support for Python and Node.js
Firecrawl v1.9.0 Release
Self-Host Improvements
- Supabase client error fixes
- Fixed support for LLM Providers
- Crawl is much faster now
- Global adoption of cacheable lookup system
- Easier setup for self-host
MCP Improvements (v1.11.0)
- Tons of improvements to it (prompts, examples, and how to use params properly)
SDK & API Enhancements
- Added change tracking to SDK 2.0
- Crawl delay support with per-crawl concurrency limiting
- New Qwen3 crawler example via OpenRouter
- Cancel batch scrape endpoint
Performance & Limits
- Global adoption of cacheable lookup system
- Increased map endpoint limit from 5,000 to 30,000 links
- Search schema limit increased from 50 to 100
Fixes & Stability
- Better error handling for SSL failures
- Optional chaining bug fixes
- WaitAction field validation in firecrawl-py
- Concurrency queue reworked to prioritize by time, not priority
Dashboard (Cloud version)
- New activity logs
GitHub Changelog: https://github.com/firecrawl/firecrawl/compare/v1.8.0...v1.9.0
-
What is Enhanced Mode: Enhanced Mode is a specialized proxy feature for scraping websites with advanced anti-bot protection, providing better success rates when extracting data from challenging sites.
-
Pricing Change: Starting May 8th, 2025, Enhanced Mode proxy requests will cost 5 credits per request (previously included in standard credit pricing).
-
Quality Improvements: The price adjustment reflects significant quality improvements to Enhanced Mode, ensuring higher success rates and more reliable data extraction from complex and difficult-to-scrape sites.
-
Usage Optimization: For optimal credit usage, consider using Enhanced Mode as a retry mechanism only when encountering specific error status codes (401, 403, or 500).
Firecrawl Launch Week III – Summary
Day 7 – Integration Day
- 20+ new/updated integrations: Discord Bot, Make, n8n, Langflow, LlamaIndex, Dify, and more.
Day 6 – Firecrawl MCP
- MCP now supports FIRE-1 agent for interaction-aware scraping.
- Added SSE streaming for real-time data.
Day 5 – Developer Day
- Python SDK v2.0: async, named params, typed responses.
- Rust SDK: batch scraping, cancel jobs,
llms.txt, smarter search. - Up to 20 seats on every plan.
- New Firecrawl Dark Theme for VS Code & compatible editors.
Day 4 – LLMstxt.new
- Prefix any URL with
llmstxt.new/→ clean.txtoutput. - Two outputs:
llms.txt(summary) &llms-full.txt(full content). - API-ready for LLM training/inference.
Day 3 – /extract v2
- FIRE-1 powered extraction with pagination & dynamic flows.
- Extract without a URL via built-in search.
- Faster, more accurate models.
Day 2 – FIRE-1 Agent
- AI agent for smart navigation and interaction.
- Handles pagination, buttons, and JS-rendered elements.
Day 1 – Change Tracking
- Detect & diff webpage changes via SDK.
- Structured
changeTrackingformat with timestamps.
Day 0 – Firecrawl Editor Theme
- Official theme for VS Code, Cursor, Windsurf, etc.
- Deep Research Open Alpha: Structured outputs + customizability.
- Concurrent Browsers: Improved rate limits for all users.
- Compare Beta: Figure what has changed in the website directly in /scrape and /crawl endpoints. Currently in closed beta.
- /extract: URLs are now optional.
- /scrape: Warns if concurrency-limited.
- New Firecrawl Examples: Featuring models like Claude 3.7, Gemini 2.5, Deepseek V3, Mistral 3.1, and more.
- Crawl:
maxDiscoveryDepthoption added.
- Fixed circular JSON error in search.
- Reworked new tally system.
- Fixed sitemaps poisoning crawler with unrelated links.
- Crawler status retries added on failure (up to 3 times).
- Credit check now snaps to remaining credits if exceeded.
- Fixed path filtering bug in Map.
- Removed unsupported schema in
llmExtract.
We're excited to introduce concurrent browsers in our pricing!
We also 5x'd the rate limits, now displayed as concurrent browsers. This change provides more visibility and allows users to upgrade for faster speeds. Enjoy the awesome increase in rate limits across all plans!
See the new rate limits here.
The /llmstxt endpoint allows you to transform any website into clean, LLM-ready text files. Simply provide a URL, and Firecrawl will crawl the site and generate both llms.txt and llms-full.txt files that can be used for training or analysis with any LLM.
Docs here: https://docs.firecrawl.dev/features/alpha/llmstxt
The /deep-research endpoint enables AI-powered deep research and analysis on any topic. Simply provide a research query, and Firecrawl will autonomously explore the web, gather relevant information, and synthesize findings into comprehensive insights.
Join the waitlist here: https://www.firecrawl.dev/deep-research
Introducing the Firecrawl MCP Server. Give Cursor, Windsurf, Claude enhanced web extraction capabilities. Big thanks to @vrknetha, @cawstudios for the initial implementation!
See here: https://github.com/firecrawl/firecrawl-mcp-server
- Improved charset detection and re-decoding.
- Fixed extract token limit issues.
- Addressed issues with includes/excludes handling.
- Fixed AI SDK handling of JSON responses.
- AI-SDK Migration – transitioned to AI-SDK.
- Auto-Recharge Emails – notify users about upgrades.
- Fire-Index Added – introduced a new indexing system.
- Self-Hosting Enhancements – OpenAI-compatible API & Ollama env support.
- Batch Billing – streamlined billing processes.
- Supabase Read Replica Routing – improved database performance.
- Implemented Claude 3.7 and GPT-4.5 web crawlers.
- Added Groq Web Crawler example.
- Updated crawl-status behavior for better error handling.
- Improved cross-origin redirect handling.
- Updated Dockerfile.
- Fixed missing "required" field in docs.
- Reworked Guide: The
SELF_HOST.mdanddocker-compose.yamlhave been updated for clarity and compatibility - Kubernetes Imporvements: Updated self-hosted Kubernetes deployment examples for compatibility and consistency (#1177)
- Self-Host Fixes: Numerous fixes aimed at improving self-host performance and stability (#1207)
- Proxy Support: Added proxy support tailored for self-hosted environments (#1212)
- Playwright Integration: Added fixes and continuous integration for the Playwright microservice (#1210)
- Search Endpoint Upgrade: Added SearXNG support for the
/searchendpoint (#1193)
- Crawl Status Fixes: Fixed various race conditions in the crawl status endpoint (#1184)
- Timeout Enforcement: Added timeout for scrapeURL engines to prevent hanging requests (#1183)
- Query Parameter Retention: Map function now preserves query parameters in results (#1191)
- Screenshot Action Order: Ensured screenshots execute after specified actions (#1192)
- PDF Scraping: Improved handling for PDFs on complex websites (#1198)
- Map/scrapeURL Abort Control: Integrated AbortController to stop scraping when the request times out (#1205)
- SDK Timeout Enforcement: Enforced request timeouts in the SDK (#1204)
- Proxy Options: Introduced proxy configuration options for infrastructure management (#1196)
- Deep Research (Alpha): Launched an alpha implementation of deep research (#1202)
- LLM Text Generator: Added a new endpoint for llms.txt generation (#1201)
- Production Ready Docker Image: A streamlined, production ready Docker image is now available to simplify self-hosted deployments.
- Scrape API: Added action & wait time validation (#1146)
- Extraction Improvements:
- Environment Setup: Added Serper & Search API env vars to docker-compose (#1147)
- Credit System Update: Now displays "tokens" instead of "credits" when out of tokens (#1178)
- Gemini 2.0 Crawler: Implemented new crawling example (#1161)
- Gemini TrendFinder: https://github.com/firecrawl/gemini-trendfinder
- Normal Search to Open Deep Research: https://github.com/nickscamara/open-deep-research
- Open Deep Research: An open source version of OpenAI Deep Research. See here: https://github.com/nickscamara/open-deep-research
- R1 Web Extractor Feature: New extraction capability added.
- O3-Mini Web Crawler: Introduces a lightweight crawler for specific use cases.
- Updated Model Parameters: Enhancements to o3-mini_company_researcher.
- URL Deduplication: Fixes handling of URLs ending with /, index.html, index.php, etc.
- Improved URL Blocking: Uses tldts parsing for better blocklist management.
- Valid JSON via rawHtml in Scrape: Ensures valid JSON extraction.
- Product Reviews Summarizer: Implements summarization using o3-mini.
- Scrape Options for Extract: Adds more configuration options for extracting data.
- O3-Mini Job Resource Extractor: Extracts job-related resources using o3-mini.
- Cached Scrapes for Extract evals: Improves performance by using cached data for extractions evals.
We're excited to announce several new features and improvements:
- Added web search capabilities to the extract endpoint via the
enableWebSearchparameter - Introduced source tracking with
__experimental_showSourcesparameter - Added configurable webhook events for crawl and batch operations
- New
timeoutparameter for map endpoint - Optional ad blocking with
blockAdsparameter (enabled by default)
- Enhanced proxy selection and infrastructure reliability
- Added domain checker tool to cloud platform
- Redesigned LLMs.txt generator interface for better usability
We've significantly enhanced our data extraction capabilities with several key updates:
- Extract now returns a lot more data
- Improved infrastructure reliability
- Migrated from Cheerio to a high-performance Rust-based parser for faster and more memory-efficient parsing
- Enhanced crawl cancellation functionality for better control over running jobs
We have updated the /extract endpoint to now be asynchronous. When you make a request to /extract, it will return an ID that you can use to check the status of your extract job. If you are using our SDKs, there are no changes required to your code, but please make sure to update the SDKs to the latest versions as soon as possible.
For those using the API directly, we have made it backwards compatible. However, you have 10 days to update your implementation to the new asynchronous model.
For more details about the parameters, refer to the docs sent to you.
The search endpoint combines web search with Firecrawl’s scraping capabilities to return full page content for any query.
Include scrapeOptions with formats: ["markdown"] to get complete markdown content for each search result otherwise it defaults to getting SERP results (url, title, description).
More info here: v1/search docs
- Fixed LLM not following the schema in the python SDK for
/extract - Fixed schema json not being able to be sent to the
/extractendpoint through the Node SDK - Prompt is now optional for the
/extractendpoint - Our fork of MinerU is now default for PDF Parsing
Feature Enhancements
- New Features:
- Geolocation, mobile scraping, 4x faster parsing, better webhooks,
- Credit packs, auto-recharges and batch scraping support.
- Iframe support and query parameter differentiation for URLs.
- Similar URL deduplication.
- Enhanced map ranking and sitemap fetching.
Performance Improvements
- Faster crawl status filtering and improved map ranking algorithm.
- Optimized Kubernetes setup and simplified build processes.
- Sitemap discoverability and performance improved
Bug Fixes
- Resolved issues:
- Badly formatted JSON, scrolling actions, and encoding errors.
- Crawl limits, relative URLs, and missing error handlers.
- Fixed self-hosted crawling inconsistencies and schema errors.
SDK Updates
- Added dynamic WebSocket imports with fallback support.
- Optional API keys for self-hosted instances.
- Improved error handling across SDKs.
Documentation Updates
- Improved API docs and examples.
- Updated self-hosting URLs and added Kubernetes optimizations.
- Added articles: mastering
/scrapeand/crawl.
Miscellaneous
- Added new Firecrawl examples
- Enhanced metadata handling for webhooks and improved sitemap fetching.
- Updated blocklist and streamlined error messages.

You can now scrape multiple URLs simultaneously with our new Batch Scrape endpoint.
- Read more about the Batch Scrape endpoint here.
- Python SDK (1.4.x) and Node SDK (1.7.x) updated with batch scrape support.
- Added crawl cancellation support for the Python SDK (1.3.x) and Node SDK (1.6.x)
- OpenAI Voice + Firecrawl example added to the repo
- CRM lead enrichment example added to the repo
- Improved our Docker images
- Limit and timeout fixes for the self hosted playwright scraper
- Improved speed of all scrapes
- Fixed 500 errors that would happen often in some crawled websites and when servers were at capacity
- Fixed an issue where v1 crawl status wouldn't properly return pages over 10mb
- Fixed an issue where
screenshotwould return undefined - Push improvements that reduce speed times when a scraper fails

Interact with pages before extracting data, unlocking more data from every site!
Firecrawl now allows you to perform various actions on a web page before scraping its content. This is particularly useful for interacting with dynamic content, navigating through pages, or accessing content that requires user interaction.
- Version 1.5.x of the Node SDK now supports type-safe Actions.
- Actions are now available in the REST API and Python SDK (no version bumps required!).
Here is a python example of how to use actions to navigate to google.com, search for Firecrawl, click on the first result, and take a screenshot.
from firecrawl import Firecrawl
app = Firecrawl(api_key="fc-YOUR_API_KEY")
# Scrape a website:
scrape_result = app.scrape_url('firecrawl.dev',
params={
'formats': ['markdown', 'html'],
'actions': [
{"type": "wait", "milliseconds": 2000},
{"type": "click", "selector": "textarea[title=\"Search\"]"},
{"type": "wait", "milliseconds": 2000},
{"type": "write", "text": "firecrawl"},
{"type": "wait", "milliseconds": 2000},
{"type": "press", "key": "ENTER"},
{"type": "wait", "milliseconds": 3000},
{"type": "click", "selector": "h3"},
{"type": "wait", "milliseconds": 3000},
{"type": "screenshot"}
]
}
)
print(scrape_result)For more examples, check out our API Reference.
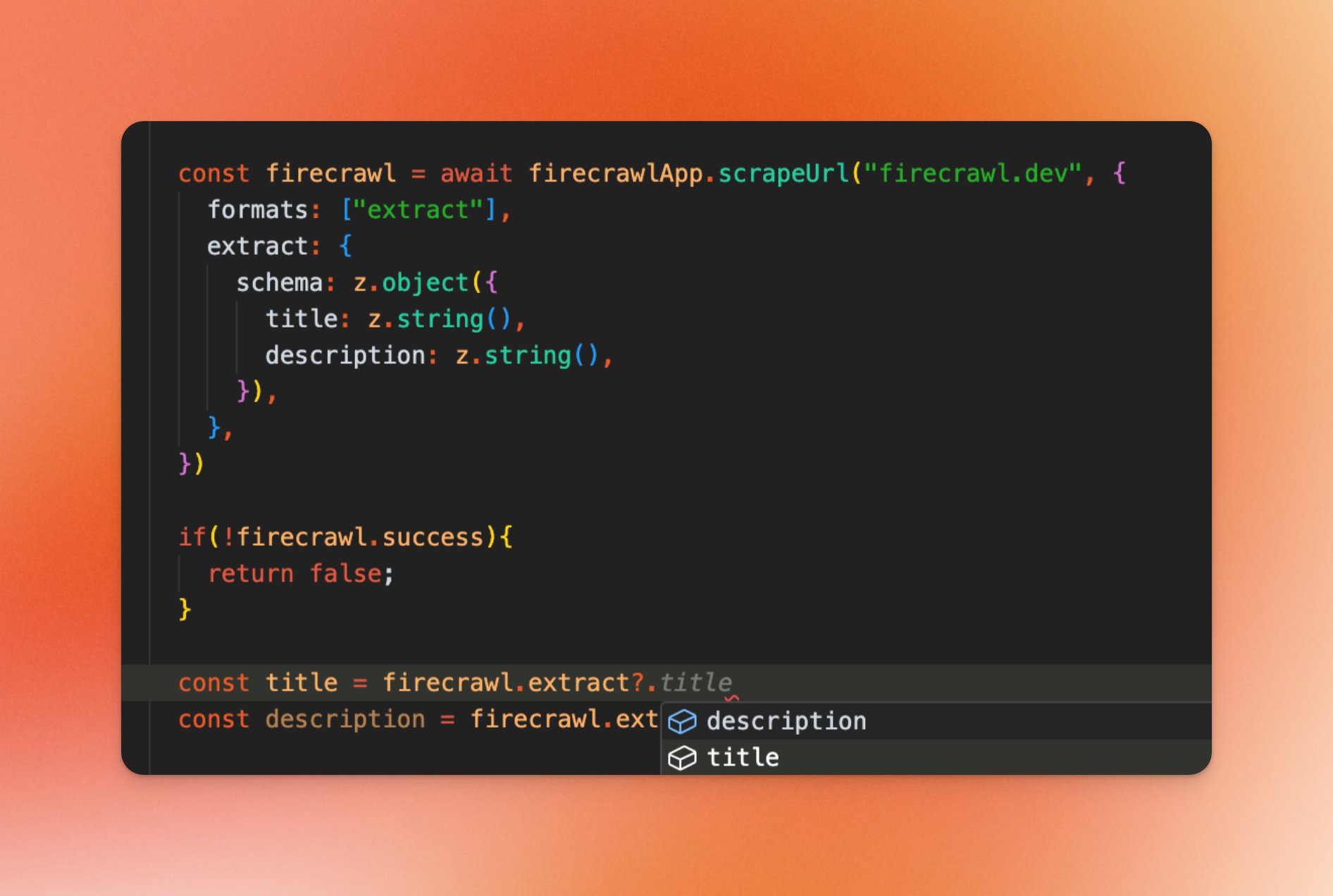
- E2E Type Safety for LLM Extract in Node SDK version 1.5.x.
- 10x cheaper in the cloud version. From 50 to 5 credits per extract.
- Improved speed and reliability.
- Rust SDK v1 is finally here! Check it out here.
- Map smart results limits increased from 100 to 1000.
- Scrape speed improved by 200ms-600ms depending on the website.
- For now on, for every new release, we will be creating a changelog entry here.
- Lots of improvements pushed to the infra and API. For all Mid-September changes, refer to the commits here.

- Output Formats for /scrape: Choose what formats you want your output in.
- New /map endpoint: Get most of the URLs of a webpage.
- Developer friendly API for /crawl/id status.
- 2x Rate Limits for all plans.
- Go SDK and Rust SDK.
- Teams support.
- API Key Management in the dashboard.
- onlyMainContent is now default to true.
- /crawl webhooks and websocket support.
Learn more about it here.
Start using v1 right away at https://firecrawl.dev