
TL;DR
- Claude Code skills are markdown files that give Claude new capabilities and trigger automatically based on context
- This tutorial walks through building a complete web-access skill with Firecrawl, covering markdown extraction, screenshots, structured data, web search, and documentation crawling
- You'll learn the SKILL.md format, how to write descriptions that trigger reliably, and how to organize multi-feature skills
Skills are how you extend Claude Code. They're markdown files that teach it new capabilities, trigger automatically based on context, and work across every project once you set them up.
This tutorial covers how to build one from scratch. You'll learn the file structure, how to write descriptions that trigger reliably, and how to organize multi-feature skills. The example we'll build handles web access: markdown extraction, screenshots, structured data extraction, web search, and documentation crawling. Web access is a good teaching example because it involves external API calls, multiple use cases in a single skill, and addresses limitations in Claude Code's default capabilities.
By the end, you'll have a working skill and the knowledge to build others for whatever workflows you need.
What are Claude Code skills?
A skill is a folder containing a SKILL.md file that gives Claude Code new abilities. The file contains instructions that Claude follows when the skill activates.
Skills can call external APIs, run scripts, read files, and execute code. They're how you integrate third-party services into Claude Code in a controlled, repeatable way. You define the behavior once, and it works the same every time.
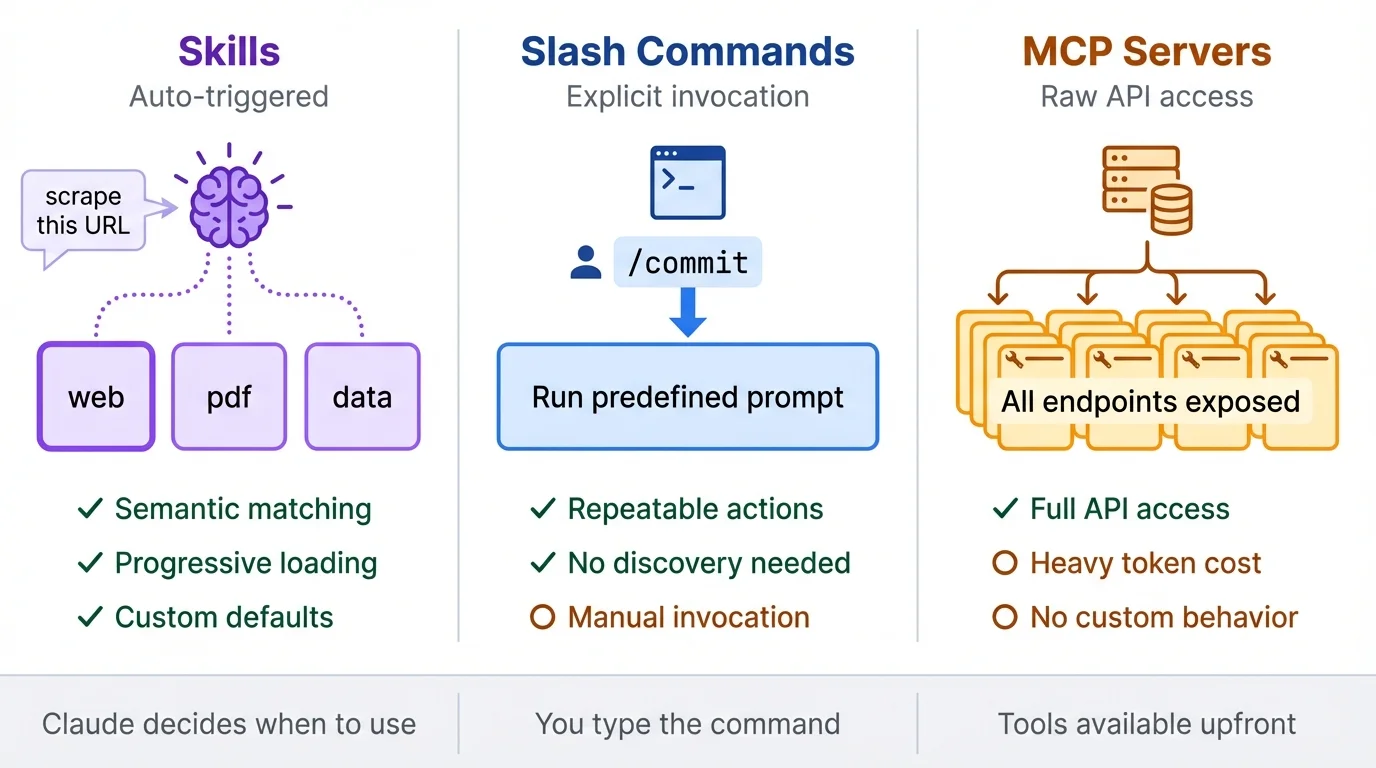
Claude Code also has slash commands, which you invoke explicitly by typing /command. Skills work differently. They trigger through semantic matching: Claude reads your request, compares it against all available skill descriptions, and activates the right one automatically. Ask "get me the markdown from this URL" and a web scraping skill activates. Ask "what's in this PDF" and a PDF skill activates. You don't memorize commands or check documentation.
MCP vs. skills
MCP servers are another extension mechanism in Claude Code. They connect Claude to external tools, databases, and APIs. The difference: MCP servers provide tools, skills teach Claude how to use them. An MCP server gives Claude raw access to an API with all its endpoints and parameters. A skill encodes your preferences: which endpoints to call, what defaults to use, how to format output, and how to handle errors. You get consistent behavior instead of Claude figuring out usage from scratch each time. The underlying reason this works so well: CLIs tend to outperform direct API integrations for agents. A model can discover behavior on demand rather than needing the full schema preloaded.
There's also a context window difference. MCP servers load all tool definitions upfront before any conversation starts. A typical multi-server setup can consume 50K+ tokens before you ask anything. Skills use progressive disclosure: only names and descriptions load at startup, full instructions load when activated, and reference files load on-demand. You can have dozens of skills with minimal overhead. Skills also aren't tied to Claude Code specifically. Any coding agent with filesystem access, including Codex CLI and Gemini CLI, can read the same SKILL.md files without modification. Write a skill once; it works wherever the model can read files and run commands. If you're evaluating MCP against newer agent communication standards, see our breakdown of MCP vs. A2A protocols.
| MCP servers | Skills | |
|---|---|---|
| What they provide | Raw tool access to an API | Encoded workflow with your defaults baked in |
| Context cost | 50K+ tokens loaded upfront | Name + description only; full content loads on activation |
| Setup | Server process, protocol, transports | Markdown file in a folder |
| Behavior | Claude figures out usage from scratch each time | Consistent, predictable output |
| Portability | Tied to a specific client | Works with any agent that has filesystem access |
| Best for | Maximum API flexibility | Repeatable, opinionated workflows |
Skills live in two places:
- User-level (
~/.claude/skills/): Available across all your projects. Good for personal tools you use everywhere. - Project-level (
.claude/skills/): Committed to git, shared with your team. Good for project-specific workflows.
This tutorial focuses on user-level skills since we're building something you'd want available everywhere, not tied to a single codebase.
Before building your own, it's worth knowing what's already available. Anthropic maintains an official skills repository with production-ready skills for document creation (PDF, DOCX, XLSX, PPTX), Slack GIF creation, and more. The Claude Skills Cookbook has patterns you can adapt. Community collections like Superpowers go further with structured workflow skills for brainstorming, planning, systematic debugging, and verification. These skills enforce process discipline so Claude doesn't skip planning and jump straight to code. You can install any of these with one command:
/plugin add marketplace https://github.com/anthropics/skillsFor a curated overview of what's worth installing, see the best Claude Code skills to try in 2026.
Claude Code also ships with a set of bundled skills out of the box. These are ready-made slash commands you can run without installing anything:
/simplify— rewrites selected code to be more concise and readable/batch— runs a task across multiple files or inputs in a single pass/debug— walks through debugging a problem step-by-step with structured reasoning/loop— iterates over a list of items and applies a task to each/claude-api— provides example code for calling the Anthropic API in various languages
Run /skills in any Claude Code session to see the full list of what's loaded, including both bundled and installed skills.
That said, building from scratch is the best way to understand how the system actually works. The rest of this tutorial does exactly that.
Now let's look at what goes inside that SKILL.md file.
How is a SKILL.md file structured?
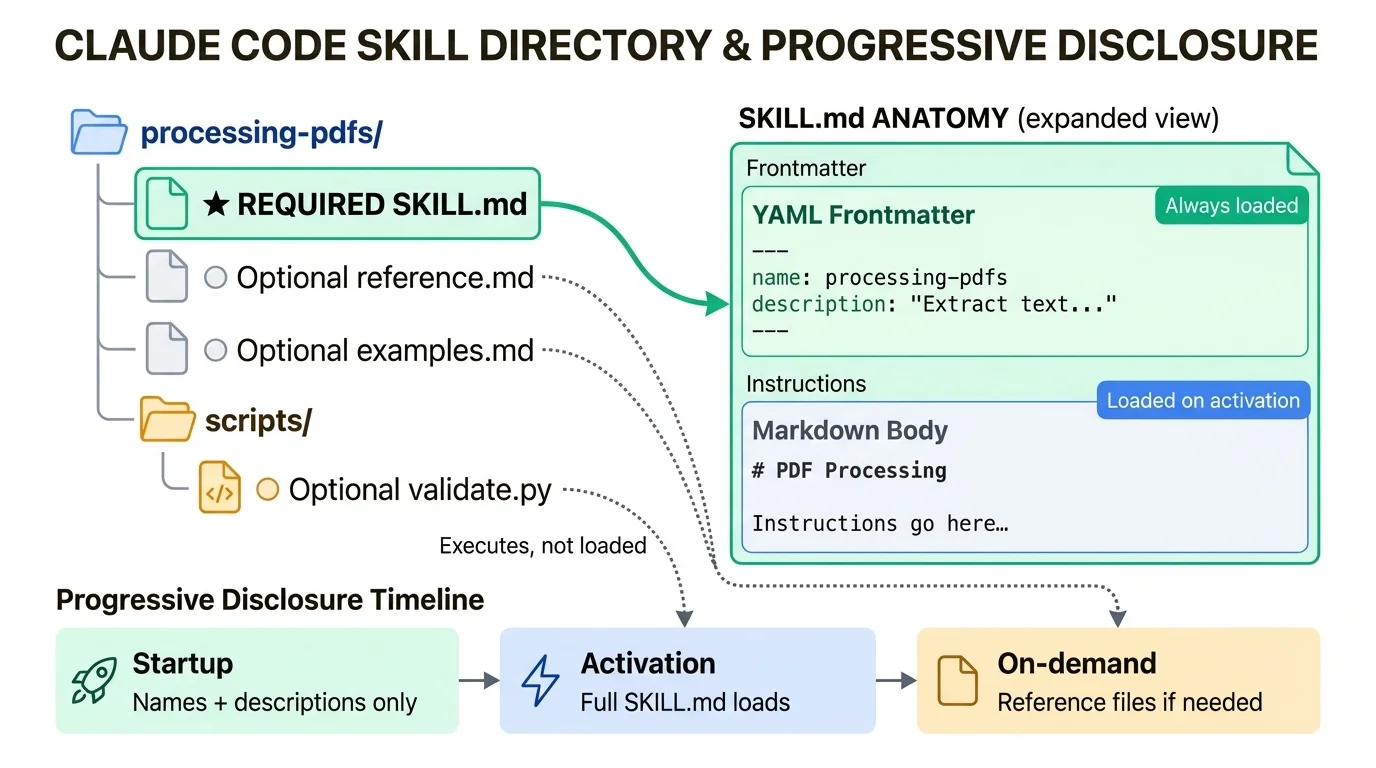
Every skill starts with a SKILL.md file. The structure is straightforward: YAML frontmatter at the top, markdown instructions below.
---
name: processing-pdfs
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
---
# PDF Processing
Instructions go here...The frontmatter has one required field and several optional ones:
description (required): Maximum 1024 characters. This field determines when your skill activates, so it matters more than anything else in the file. Write it in third person and answer two questions: what does this skill do, and when should Claude use it? Include specific terms users would say. "Extract text and tables" and "PDF files" will match requests better than "helps with documents."
name (optional): Lowercase letters, numbers, and hyphens only. Maximum 64 characters. If you omit this field, Claude Code uses the directory name automatically. Gerund forms work well (processing-pdfs, analyzing-data) but aren't required.
Optional fields give you more control:
allowed-tools: Restricts which tools Claude can use when the skill is active. Set allowed-tools: Read, Grep, Glob for a read-only skill. Set allowed-tools: Read, Bash(python:*) to allow only Python execution. You can scope Bash to specific commands using the Bash(command:*) syntax — for example, Bash(date:*) only allows running date, not arbitrary shell commands. Without this field, Claude can use any available tool.
model: Forces a specific model when the skill runs. Use model: claude-sonnet-4-20250514 for faster responses on simple tasks, or specify Opus for complex reasoning.
disable-model-invocation: Set to true to run the skill without making any LLM calls. Useful for deterministic scripts or shell commands where you don't want Claude reasoning over the output — just execute and return.
user-invocable: Set to false to hide the skill from the /skills list and prevent users from calling it by name. Useful for internal helper skills that other skills reference but that you don't want exposed directly.
argument-hint: A short string shown next to the skill name in /skills output. Use it to describe the expected input format, for example argument-hint: "<url> [--main-only]" so users know what to pass when invoking the skill explicitly.
context: Set to fork to run the skill in an isolated context that doesn't share conversation history with the main session. Good for self-contained tasks like code formatting or data transformation where you don't want the skill to see or modify your current conversation state.
The markdown body contains your actual instructions. Keep it under 500 lines. If you need more space, split content into separate files and link to them:
For API details, see [reference.md](reference.md)
For examples, see [examples.md](examples.md)Claude loads linked files only when needed. This progressive disclosure pattern lets you bundle detailed documentation without paying the token cost upfront. A skill with 2,000 lines of reference material loads the same as a 50-line skill until Claude actually needs that reference.
For multi-file skills, organize your directory like this:
skill-name/
├── SKILL.md # Required - main instructions
├── reference.md # Optional - API details
├── examples.md # Optional - usage examples
└── scripts/
└── validate.py # Optional - utility scriptsScripts execute without loading their contents into context. A 500-line Python validation script consumes zero tokens until it runs, and even then only the output counts.
String substitutions in SKILL.md
Claude Code supports a set of built-in substitutions you can use anywhere in the markdown body of your skill. These get replaced at runtime before Claude reads the content.
$ARGUMENTS — expands to everything the user typed after the skill invocation. If someone calls /firecrawl-web https://example.com --main-only, then $ARGUMENTS becomes https://example.com --main-only. Use this to pass user input directly to a script without Claude having to parse and re-format it.
$ARGUMENTS[N] / $N — expands to a single positional argument. $ARGUMENTS[0] (or $0) is the first word, $ARGUMENTS[1] (or $1) is the second, and so on. Useful when your skill expects a fixed number of inputs and you want to reference them individually.
${CLAUDE_SKILL_DIR} — expands to the absolute path of the folder containing the skill. This is particularly useful for referencing bundled scripts without hardcoding a path:
# Instead of:
python3 ~/.claude/skills/firecrawl-web/fc.py markdown $ARGUMENTS
# Use:
python3 ${CLAUDE_SKILL_DIR}/fc.py markdown $ARGUMENTSThis makes your skill portable — it works whether it's installed in ~/.claude/skills/ (user-level) or .claude/skills/ (project-level) without any changes.
${CLAUDE_SESSION_ID} — expands to a unique identifier for the current Claude Code session. Use this when your skill writes temporary files or logs and you want to avoid collisions across concurrent sessions.
You can also inject dynamic content using the ! backtick syntax. Any line starting with ! followed by a shell command runs that command at skill load time and injects its output into the skill body:
Current date: !`date +%Y-%m-%d`
Git branch: !`git branch --show-current`This is useful for context that changes frequently but is cheap to compute — like the current date, working directory, or active branch name.
Building a Claude Code skill using Firecrawl
Let's create a skill that uses Firecrawl, a web scraping API designed for LLM workflows. It handles JavaScript rendering, anti-bot detection, and outputs clean markdown instead of raw HTML. Firecrawl also has an official web scraping plugin for Claude Code if you'd rather have MCP-style access out of the box; building it as a skill gives you control over which endpoints to expose, what defaults to use, and how output is formatted.
We'll build incrementally, and each feature targets a specific limitation in Claude Code's default capabilities:
-
Blocked web requests: Claude Code can't directly access most websites due to network restrictions and anti-bot measures. Firecrawl bypasses these with dedicated scraping infrastructure.
-
Missing visual context: Claude can't see rendered webpages or JavaScript-loaded content. Firecrawl executes JavaScript and extracts the final rendered content.
-
Unstructured page content: Raw HTML is full of navigation, ads, and scripts that obscure the main content. Firecrawl returns clean markdown optimized for LLMs.
-
Outdated knowledge: Claude's training data has a cutoff date and can't answer questions about recent events. Firecrawl fetches current web content in real-time.
-
Unfamiliar frameworks: Claude needs up-to-date documentation for tools it wasn't trained on. Firecrawl scrapes API docs and technical resources on-demand.
Five problems, one skill. By the end, you'll have something that works and a pattern you can apply to other APIs.
P.S: On February 5, 2026, Anthropic released Claude Opus 4.6, a major upgrade to their smartest model. The major update was Agent teams (research preview) using which one can spin up multiple Claude Code agents that work in parallel. We wrote a detailed guide on Building Apps with Claude Opus 4.6 Agent Teams & Firecrawl Agent.
Creating the skill directory
To get started, let's set up the directory structure and configure Firecrawl authentication.
Want the complete skill? Clone it directly from GitHub and skip to Testing the Firecrawl skill.
First, create the skill folder:
mkdir -p ~/.claude/skills/firecrawl-webNext, get your Firecrawl API key. Go to firecrawl.dev, create an account, and navigate to the API Keys section in your dashboard. The free tier includes 500 credits, enough to follow this tutorial and test your skill.
Store the key in a .env file in your home directory:
echo 'FIRECRAWL_API_KEY=fc-your-key-here' >> ~/.envOr export it directly in your shell profile (~/.zshrc or ~/.bashrc):
export FIRECRAWL_API_KEY=fc-your-key-hereNow create the two files your skill needs. First, the SKILL.md:
touch ~/.claude/skills/firecrawl-web/SKILL.mdAdd the frontmatter and initial content:
---
name: firecrawl-web
description: "Fetch web content, take screenshots, extract structured data, search the web, and crawl documentation sites. Use when the user needs current web information, asks to scrape a URL, wants a screenshot, needs to extract specific data from a page, or wants to learn about a framework or library."
allowed-tools: ["Bash", "Read", "Write"]
---Below the frontmatter, add:
# Firecrawl Web Skill
This skill provides web access through Firecrawl's API.
## Script Location
All commands use the bundled script:
~/.claude/skills/firecrawl-web/fc.pyThen create the Python script:
touch ~/.claude/skills/firecrawl-web/fc.pyAdd the base structure:
#!/usr/bin/env python3
"""Firecrawl web skill for Claude Code."""
import argparse
import json
import sys
import urllib.request
from pathlib import Path
from dotenv import load_dotenv
from firecrawl import Firecrawl
def main():
load_dotenv()
load_dotenv(Path.home() / ".env")
parser = argparse.ArgumentParser(description="Firecrawl web tools")
subparsers = parser.add_subparsers(dest="command", required=True)
# Subcommands added as we build each feature
args = parser.parse_args()
if __name__ == "__main__":
main()The script uses subcommands, so each feature becomes python fc.py markdown, python fc.py screenshot, etc. We'll add these one at a time.
Feature 1: Markdown extraction
Claude Code's built-in web fetch runs into 403 errors on many sites. Each request carries a clear signature of where it's coming from, and websites block it. Firecrawl's scrape endpoint routes requests through infrastructure designed to avoid these blocks and converts the response to clean markdown.
Adding the markdown scraping command
Add the following code to fc.py:
def scrape_markdown(url: str, only_main: bool = False) -> str:
"""Scrape a URL and return markdown content."""
app = Firecrawl()
result = app.scrape(
url,
formats=["markdown"],
only_main_content=only_main if only_main else None
)
return result.markdown
# Inside main(), add to subparsers:
md_parser = subparsers.add_parser("markdown", help="Get page as markdown")
md_parser.add_argument("url", help="URL to scrape")
md_parser.add_argument("--main-only", action="store_true", help="Exclude nav/footer")
# And handle the command:
if args.command == "markdown":
content = scrape_markdown(args.url, args.main_only)
print(content)Then add a "Getting Page Content" section to SKILL.md with these usage examples:
# Fetch any webpage as clean markdown
python3 ~/.claude/skills/firecrawl-web/fc.py markdown "https://example.com"
# Cleaner output without navigation and footers
python3 ~/.claude/skills/firecrawl-web/fc.py markdown "https://example.com" --main-onlyFeature 2: Taking screenshots
Screenshots are useful for automation. If you're a technical writer, you can capture homepage screenshots to include as visuals in articles (like this one!). If you're building reports, you can grab the current state of dashboards or landing pages. Markdown can't capture layout, branding, or visual hierarchy.
Firecrawl returns screenshots as temporary URLs hosted on cloud storage rather than inline base64 data. The code checks for this URL response first and downloads the image directly, with base64 handling as a fallback for compatibility.
Adding the screenshot command
Add the following code to fc.py:
import base64
def take_screenshot(url: str, output_path: str = None) -> str:
"""Take a screenshot of a URL."""
app = Firecrawl()
result = app.scrape(url, formats=["screenshot"])
screenshot_data = result.screenshot
# Handle URL response (Firecrawl returns a GCS URL)
if screenshot_data.startswith("http://") or screenshot_data.startswith("https://"):
if output_path:
urllib.request.urlretrieve(screenshot_data, output_path)
return f"Screenshot saved to {output_path}"
return f"[Screenshot URL: {screenshot_data}]"
# Handle base64 data URI response (fallback)
if screenshot_data.startswith("data:image"):
screenshot_data = screenshot_data.split(",", 1)[1]
if output_path:
with open(output_path, "wb") as f:
f.write(base64.b64decode(screenshot_data))
return f"Screenshot saved to {output_path}"
return f"[Screenshot: {len(screenshot_data)} bytes base64]"
# Add subparser:
ss_parser = subparsers.add_parser("screenshot", help="Screenshot a webpage")
ss_parser.add_argument("url", help="URL to capture")
ss_parser.add_argument("--output", "-o", help="Save to file (PNG)")
# Handle command:
if args.command == "screenshot":
result = take_screenshot(args.url, args.output)
print(result)Add a "Taking Screenshots" section to SKILL.md:
# Capture a full-page screenshot
python3 ~/.claude/skills/firecrawl-web/fc.py screenshot "https://example.com" -o page.pngFeature 3: Structured data extraction
Markdown gives you everything on the page, but sometimes you only need specific fields, like a product price, an article title, or a list of features. Parsing that out with string manipulation is fragile and error-prone. A schema tells Firecrawl exactly what to return, and you get consistent JSON every time regardless of how the page layout changes.
Adding the structured data extraction command
Add the following code to fc.py:
def extract_data(url: str, schema: dict, prompt: str = None) -> dict:
"""Extract structured data from a URL using a schema."""
app = Firecrawl()
format_spec = {"type": "json", "schema": schema}
if prompt:
format_spec["prompt"] = prompt
result = app.scrape(url, formats=[format_spec])
return result.json
# Add subparser:
ex_parser = subparsers.add_parser("extract", help="Extract structured data")
ex_parser.add_argument("url", help="URL to extract from")
ex_parser.add_argument("--schema", required=True, help="Path to JSON schema file")
ex_parser.add_argument("--prompt", help="Extraction guidance")
# Handle command:
if args.command == "extract":
with open(args.schema) as f:
schema = json.load(f)
data = extract_data(args.url, schema, args.prompt)
print(json.dumps(data, indent=2))Add an "Extracting Structured Data" section to SKILL.md. First, provide an example schema file:
{
"type": "object",
"properties": {
"title": { "type": "string" },
"price": { "type": "number" },
"features": { "type": "array", "items": { "type": "string" } }
}
}Then the usage examples, which tells Claude where to find the method and schema files:
# Extract using a schema
python3 ~/.claude/skills/firecrawl-web/fc.py extract "https://example.com/product" --schema schema.json
# Add a prompt for better accuracy
python3 ~/.claude/skills/firecrawl-web/fc.py extract "https://example.com/product" --schema schema.json --prompt "Extract the main product details"Feature 4: Web search
Instead of scraping a URL you already know, Firecrawl searches the web and returns markdown content from the results. It's faster than scraping each result individually and offers flexibility through search parameters. We're only adding a results limit here, but the search endpoint docs cover other options like location filtering and content formats. For a deeper look at building search-powered applications, see our guide on combining web search and content extraction with Firecrawl.
This builds on the markdown extraction feature from earlier.
Adding the web search command
Add the following code to fc.py:
def search_web(query: str, limit: int = 5) -> list:
"""Search the web and return results with content."""
app = Firecrawl()
results = app.search(query, limit=limit)
return results.web or []
# Add subparser:
search_parser = subparsers.add_parser("search", help="Search the web")
search_parser.add_argument("query", help="Search query")
search_parser.add_argument("--limit", type=int, default=5, help="Number of results")
# Handle command:
if args.command == "search":
results = search_web(args.query, args.limit)
for r in results:
print(f"## {r.title}")
print(f"URL: {r.url}")
print(r.description or "No description")
print("\n---\n")Add a "Searching the Web" section to SKILL.md:
# Search for current information
python3 ~/.claude/skills/firecrawl-web/fc.py search "Python 3.13 new features"
# Limit results
python3 ~/.claude/skills/firecrawl-web/fc.py search "latest React documentation" --limit 3Feature 5: Documentation crawling
Anthropic models have a cutoff. When you're working with a framework released after that cutoff, or one that's updated frequently, Claude might not know the current API. Crawling the docs gives Claude accurate, up-to-date reference material. Ask it to learn a new library, and it actually can.
Firecrawl's crawl feature automatically discovers and scrapes all accessible pages from a starting URL, rather than just a single page. Point it at a documentation homepage, and it returns the full site content as clean markdown. This gives Claude accurate, up-to-date reference material. For advanced configuration (URL filtering, depth control, and LangChain integration), see our guide on web crawling with Firecrawl's crawl endpoint.
Add the documentation crawling command
Add the following code to fc.py:
def crawl_docs(url: str, limit: int = 50) -> list:
"""Crawl a documentation site."""
app = Firecrawl()
result = app.crawl(
url,
limit=limit,
scrape_options={"formats": ["markdown"], "onlyMainContent": True}
)
return result.data
# Add subparser:
crawl_parser = subparsers.add_parser("crawl", help="Crawl a docs site")
crawl_parser.add_argument("url", help="Starting URL")
crawl_parser.add_argument("--limit", type=int, default=50, help="Max pages")
crawl_parser.add_argument("--output", "-o", help="Save to directory")
# Handle command:
if args.command == "crawl":
pages = crawl_docs(args.url, args.limit)
if args.output:
Path(args.output).mkdir(parents=True, exist_ok=True)
for i, page in enumerate(pages):
filename = f"{args.output}/page_{i:03d}.md"
with open(filename, "w") as f:
f.write(page.markdown or "")
print(f"Saved {len(pages)} pages to {args.output}/")
else:
for page in pages:
title = page.metadata.title if page.metadata else "Untitled"
print(f"## {title}")
print(page.markdown[:1000] if page.markdown else "")
print("\n---\n")Add a "Crawling Documentation" section to SKILL.md:
# Crawl a documentation site
python3 ~/.claude/skills/firecrawl-web/fc.py crawl "https://docs.newframework.dev" --limit 30
# Save pages to a directory
python3 ~/.claude/skills/firecrawl-web/fc.py crawl "https://docs.example.com" --limit 50 --output ./docsEach page costs one credit. Set a reasonable limit to avoid burning through your quota.
Feature 6: Branding extraction
Firecrawl's Branding Format v2 extracts a site's visual identity in one call: logo, colors, typography, spacing, and UI component styles. It's built for AI agents that need to generate on-brand assets or UI without manually reverse-engineering a design system. The v2 update improves logo detection across tricky cases like background-image logos and modern site builders like Wix and Framer. Branding Format v2: Improved Logo Extraction
Add the branding extraction command
Add the following code to fc.py:
def extract_branding(url: str) -> dict:
"""Extract brand identity data from a URL."""
app = Firecrawl()
result = app.scrape(url, formats=["branding"])
return result.branding
# Add subparser:
brand_parser = subparsers.add_parser("branding", help="Extract brand identity data")
brand_parser.add_argument("url", help="URL to extract branding from")
# Handle command:
if args.command == "branding":
branding = extract_branding(args.url)
print(json.dumps(branding, indent=2))Add a "Branding Extraction" section to SKILL.md:
# Extract logo, colors, typography, and UI style tokens
python3 ~/.claude/skills/firecrawl-web/fc.py branding "https://example.com"How do you make your Claude Code skill trigger reliably?
Skills activate through LLM reasoning, not keyword matching or embeddings. Claude reads your request, compares it against all available skill descriptions, and picks the best match. The description field determines whether your skill activates.
A good description has two parts: what the skill does, and when Claude should use it. The first part lists capabilities. The second part lists triggers. Both matter. Capabilities alone tell Claude what's possible but not when to reach for it. Triggers alone might activate the skill for wrong reasons.
Here's the pattern in our Firecrawl skill:
description: "Fetch web content, take screenshots, extract structured data, search the web, and crawl documentation sites. Use when the user needs current web information, asks to scrape a URL, wants a screenshot, needs to extract specific data from a page, or wants to learn about a framework or library."Three rules for writing Claude Code skill descriptions
-
Use third person. First person ("I can help you...") and second person ("You can use this to...") clash with Claude's system prompt structure and cause discovery problems. Stick to declarative statements. For example, use "Scrapes websites and returns clean markdown content."
-
Use the words users actually say. "Scrape a URL" matches requests better than "retrieve web content." "Take a screenshot" beats "capture visual representation." Think about how you'd phrase the request, then put those phrases in.
-
Use the full 1024 characters. A description that's too short leaves Claude guessing. Be thorough. Include what the skill does, when to use it, and its outputs and limitations.
After installing your skill, test with varied phrasing. Ask Claude to "get the markdown from this page" and "fetch this URL as text" and "what does this website say." If some phrases don't trigger the skill, add those terms to your description.
The specificity matters more than you'd expect. Scott Spence tested 200+ prompts across different description styles and found that vague descriptions like "helps with documents" triggered around 20% of the time. Specific descriptions with explicit triggers hit 80-84%.
Pro tip: you don't have to always write skills from scratch. Hiba Fathim, Marketing Specialist at Firecrawl, says her go-to is to complete a new task in Claude Code for the first time — writing a blog post, running a research workflow, whatever it is — and then ask Claude to encapsulate that session into a skill. Every time she reuses the skill and makes tweaks, she asks Claude to update the skill based on what changed in that session. The skill improves automatically as you use it. Read more about her Claude Code workflow here.
Using a forced eval hook to improve skill activation
Even with a well-written description, skills can miss. Claude evaluates descriptions passively, and if the conversation has a lot of context in it, the skill check can get deprioritized. A forced eval hook solves this by explicitly prompting Claude to check its loaded skills before every response.
Add the following to .claude/settings.json (create the file if it doesn't exist):
{
"hooks": {
"UserPromptSubmit": [
{
"hooks": [
{
"type": "command",
"command": "echo 'IMPORTANT: Before responding, review all loaded skills (run /skills if unsure) and activate any that are relevant to this request.'"
}
]
}
]
}
}This UserPromptSubmit hook runs every time a prompt is submitted, injecting a reminder into the context that pushes Claude to actively check loaded skills rather than passively match them. In Scott Spence's testing, this hook implementation pushed activation rates from around 20% to 84% — a meaningful difference if you're building skills you rely on daily.
The tradeoff: the hook adds a small amount of overhead to every prompt. For most workflows this is negligible. If you only use skills occasionally, you might prefer to rely on good description writing alone and skip the hook.
Testing the Firecrawl skill
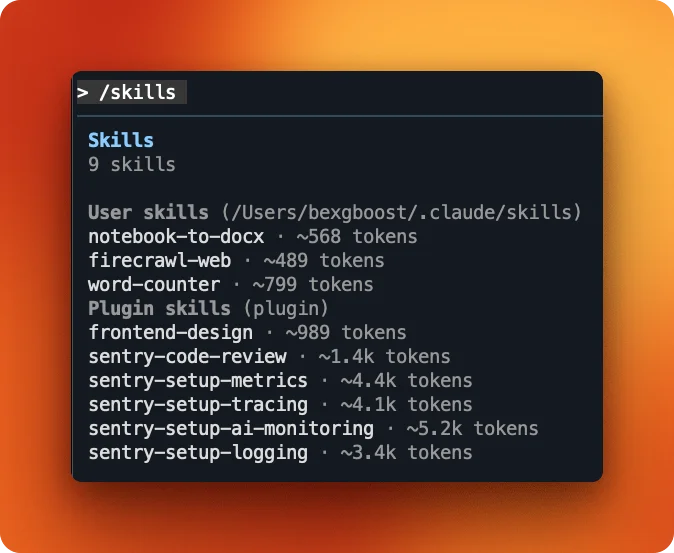
With everything in place, restart Claude Code to load the skill. Exit your current session and run claude again. Skills don't hot-reload; Claude Code reads the skills directory at startup.
Verify the skill loaded by running /skills. You should see firecrawl-web in the list:
Now test each feature. The results below come from an actual session, and they show how Claude adapts when one approach doesn't work. We explore each one below.
Web search
Claude Code has a built-in WebSearch tool. To use your Firecrawl skill's search instead, include "with Firecrawl" in your prompt. Otherwise, Claude defaults to its native tool.
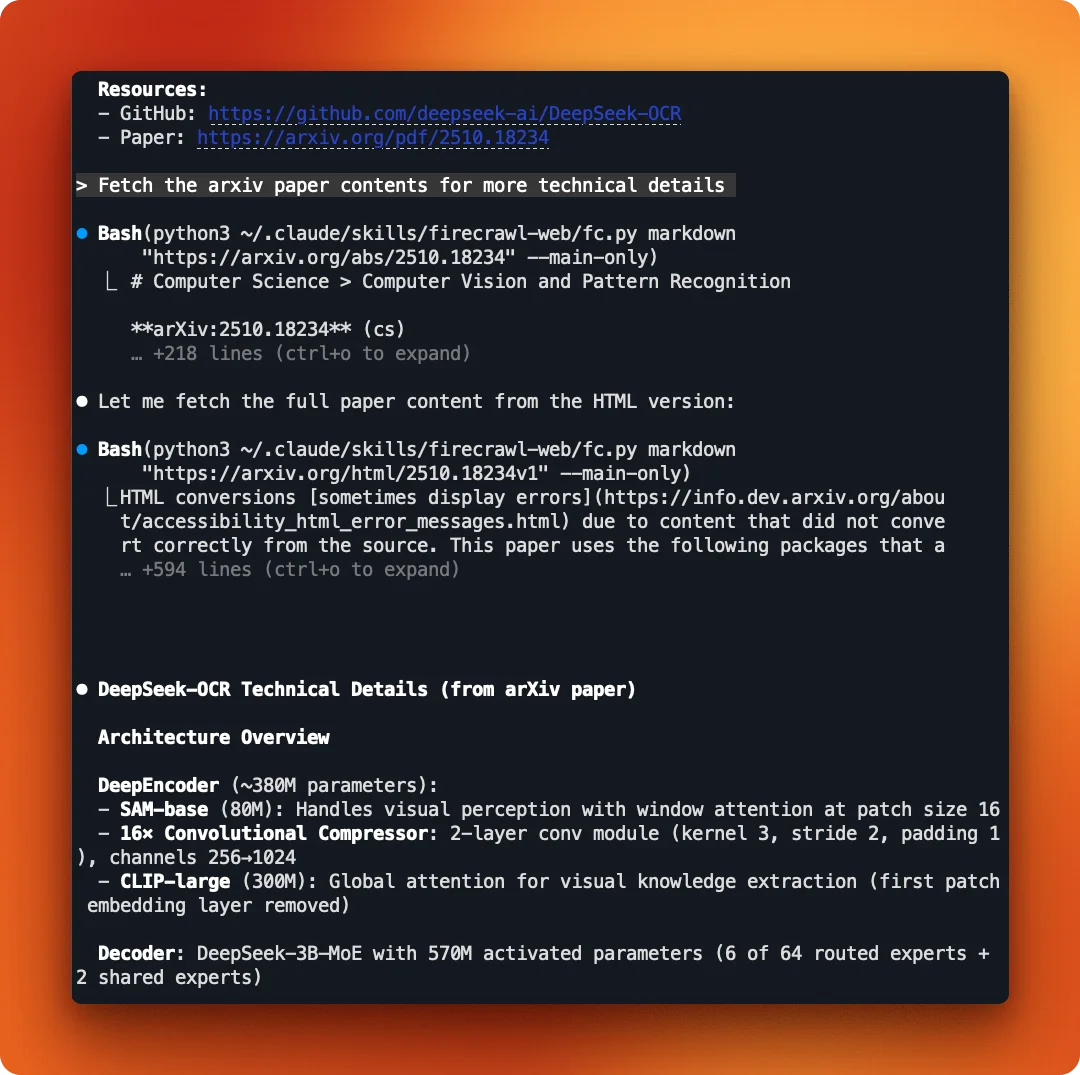
Try: "Search the web with Firecrawl for the latest on DeepSeek OCR"
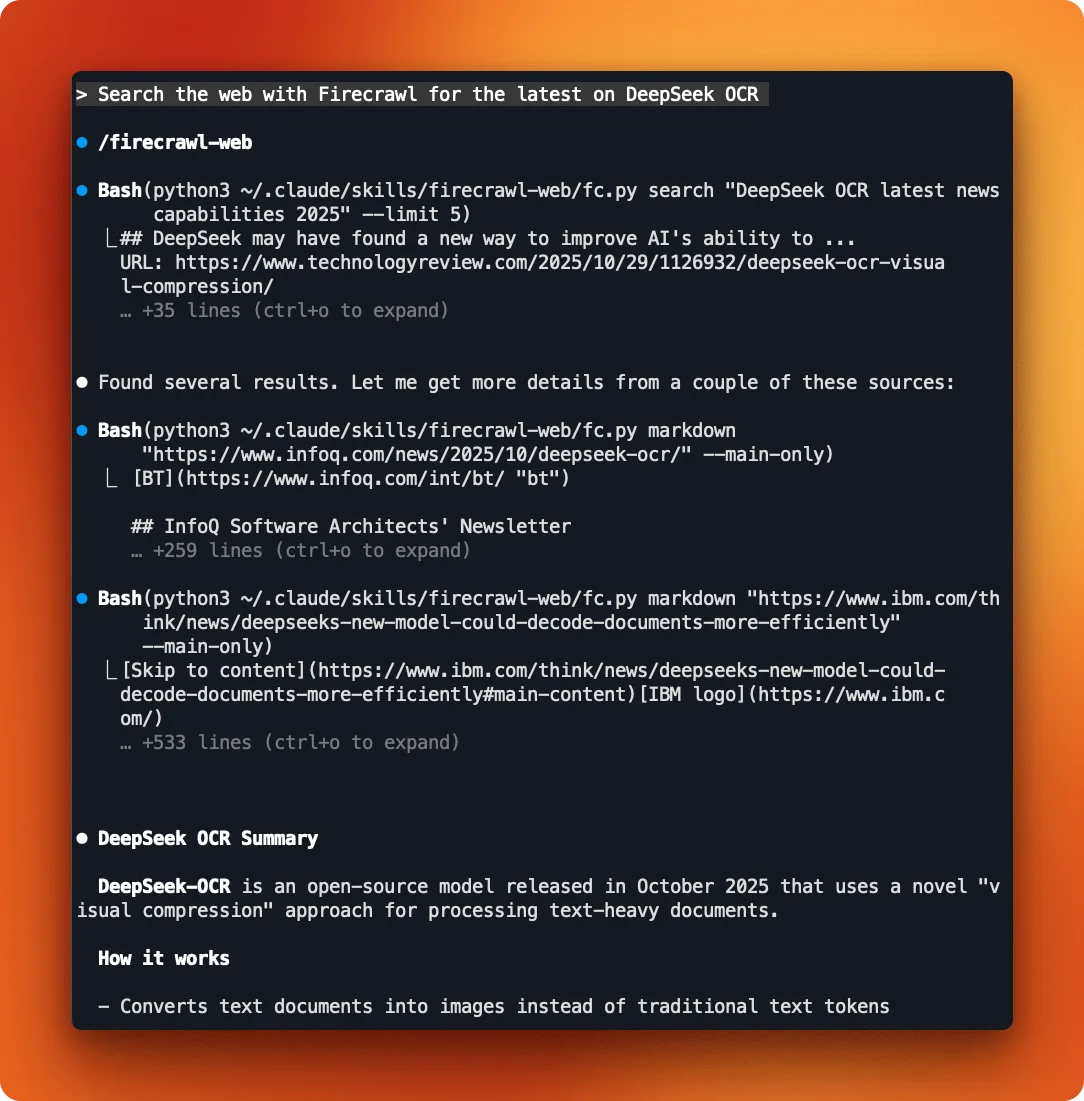
Claude finds several results and fetches the full content from each. It pulls the arXiv paper, extracts technical details, and summarizes the architecture:
Check out our guide on using Claude Code for Marketing.
Screenshots
Screenshots work with straightforward prompts. Ask Claude to capture a page and save it somewhere.
Try: "Take a screenshot of the DeepSeek OCR model card page on HuggingFace and save it to Downloads"
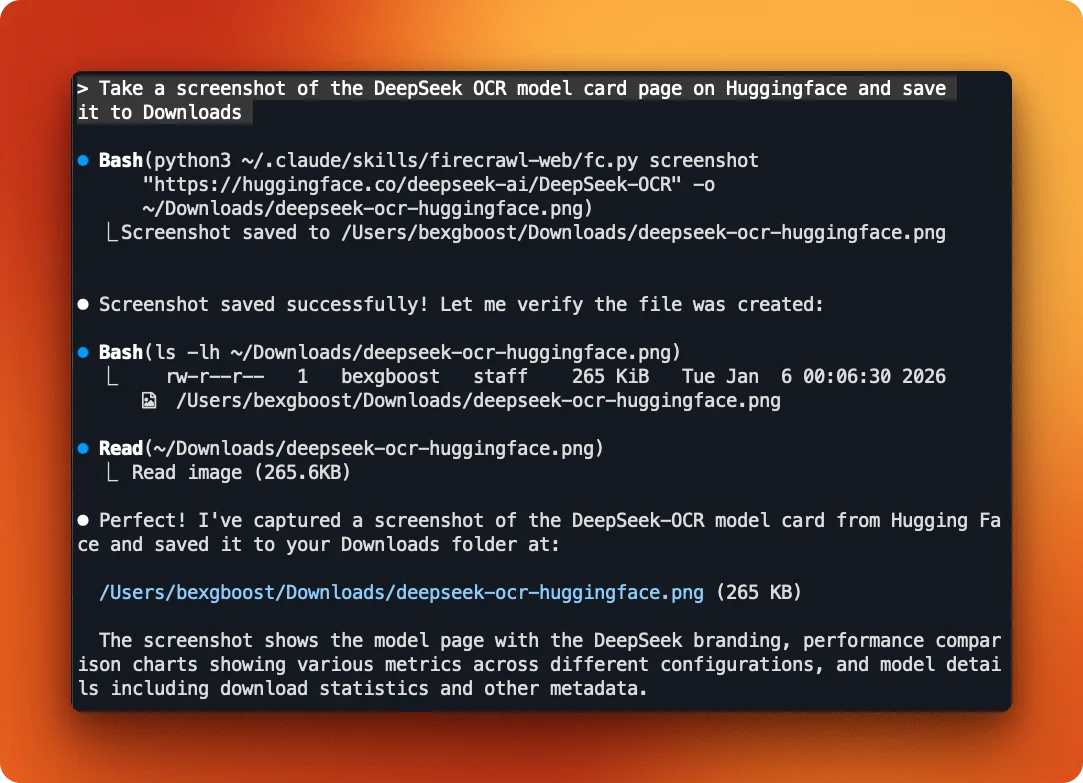
Claude runs the screenshot command and saves the image. The skill handles the URL-based response from Firecrawl and downloads the file locally. Here's the captured screenshot:
Documentation crawling
This one's interesting. Vague prompts like "grab the latest docs on OpenAI's Responses API" might trigger markdown extraction instead of a full crawl:
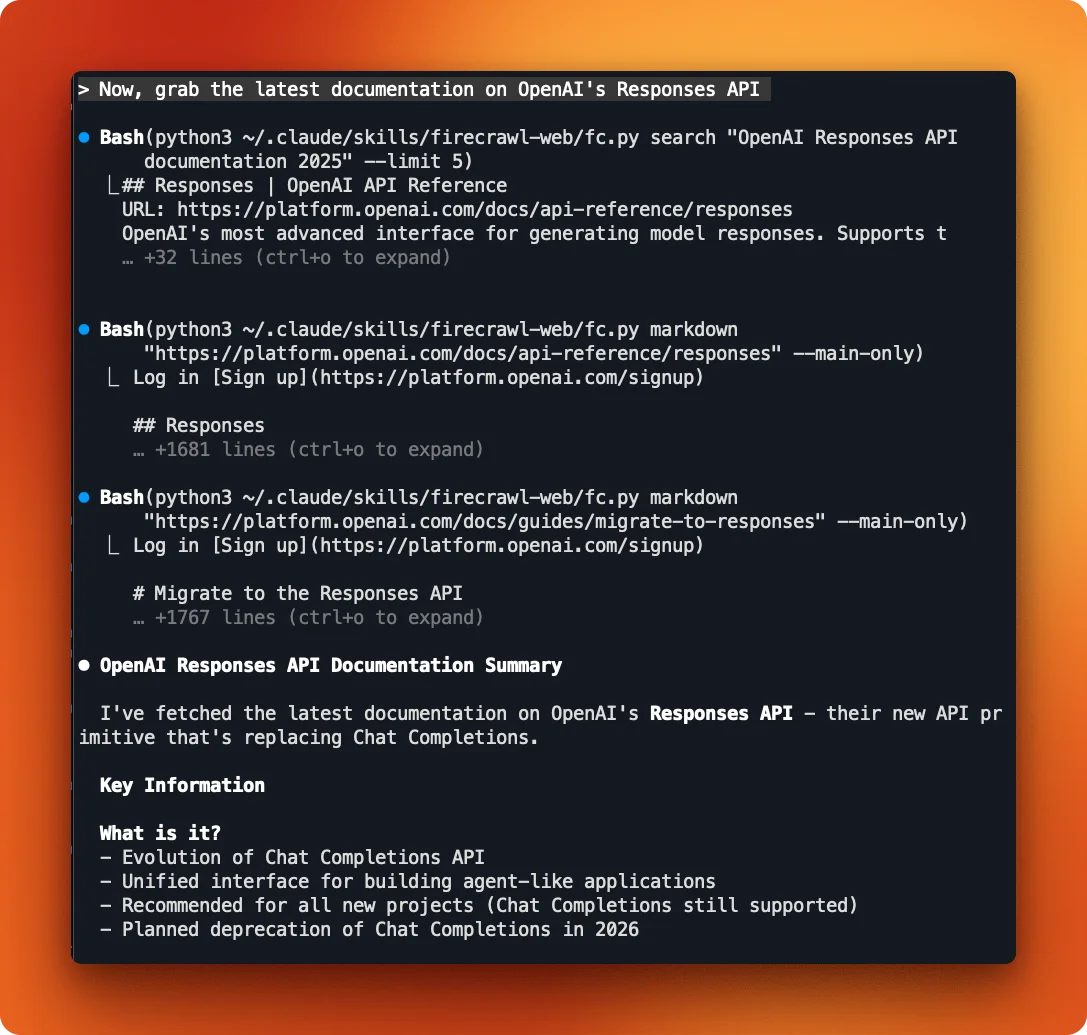
That works for a single page, but if you want multiple pages, use the word "crawl" explicitly.
Try: "Crawl and grab the latest documentation on Optuna"
Claude does something clever here. It doesn't know the Optuna docs URL, so it uses the search feature first to find it, then crawls with a 30-page limit:
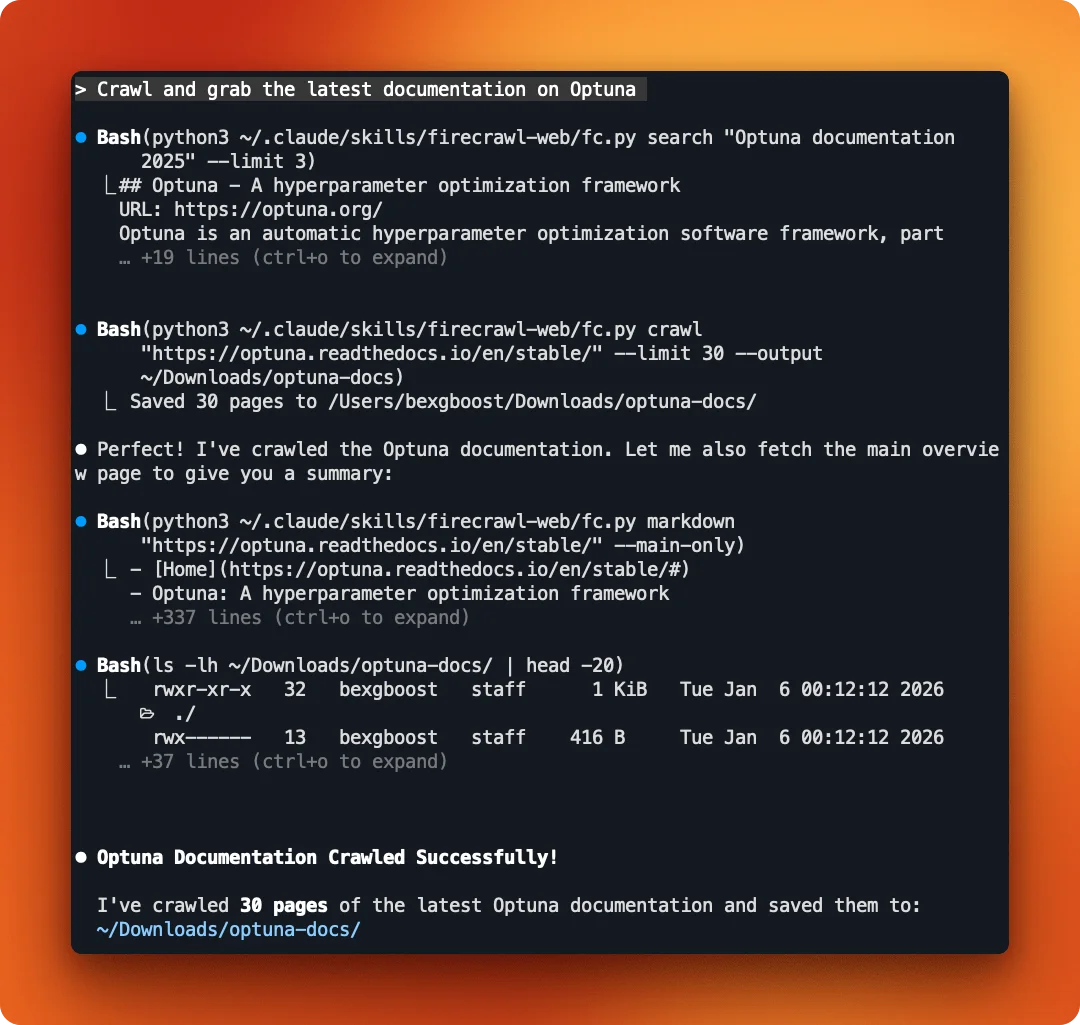
The skill saved 30 markdown files to ~/Downloads/optuna-docs/. Claude chained two features together without being told to.
Structured extraction
For the final test, ask Claude to extract structured data without specifying the source. This shows how Claude adapts when its first approach doesn't work.
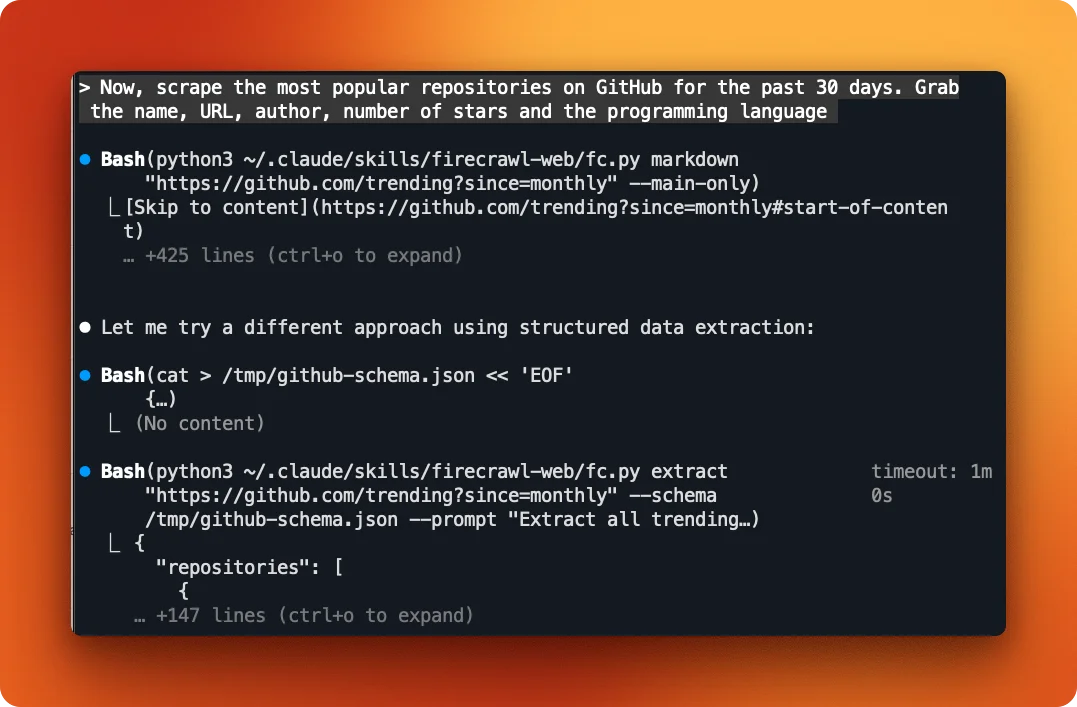
Try: "Scrape the most popular repositories on GitHub for the past 30 days. Grab the name, URL, author or org, stars, and the programming language."
Claude first tries markdown extraction on GitHub's trending page. When that doesn't return clean structured data, it switches to the schema-based extraction:
The result is a clean table of trending repositories with exactly the fields requested:
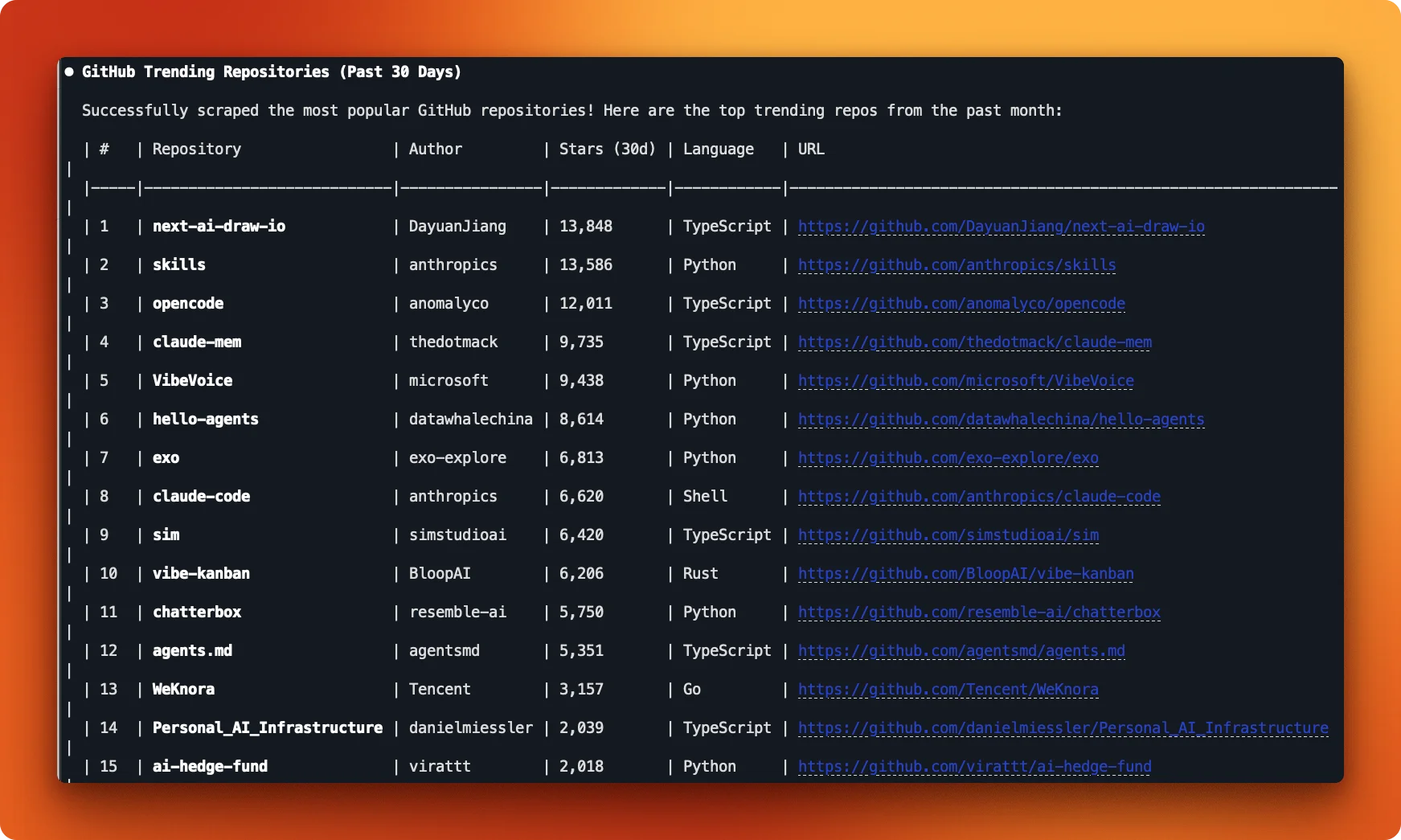
This adaptive behavior comes from how the skill description is written. Claude knows multiple approaches exist and picks the right one based on what works.
Skills vs. plugins
Skills and plugins both extend Claude Code, but they're different tools for different situations.
Skills live in a folder, trigger automatically based on context, and encode how Claude should use a specific tool or workflow, with your preferences baked in. They load progressively: only the description at startup, full content when activated. You create them or copy them from a repo, and they work instantly without installation steps or running server processes.
Plugins are packaged integrations installed through Claude Code's plugin system. They bundle MCP servers, tools, and sometimes skills into a single install, and are designed for sharing and distribution. Installing a plugin gives you capabilities someone else has built and maintains. Firecrawl is available as an official Claude Code plugin, a direct, zero-setup way to give Claude live web access without building anything yourself.
| Skills | Plugins | |
|---|---|---|
| What they are | Markdown files you create or copy | Packaged integrations you install |
| Activation | Automatic, based on context | Available after install |
| Loading | Progressive: description first, full content on demand | Bundled at install |
| Setup | Drop a folder, restart Claude Code | Install via plugin system |
| Who creates them | You, or from a public repo | Maintainers and third parties |
| Best for | Custom workflows, specific API preferences | Pre-built integrations, team distribution |
In practice: build a skill when you want precise control over defaults, output format, and triggering behavior for a specific workflow. Install a plugin when you want a maintained, pre-packaged integration without the setup overhead. For a curated list of the most useful options available today, see the best Claude Code plugins for AI development.
Conclusion
You now have a working skill that handles five types of web access: markdown extraction, screenshots, structured data, search, and documentation crawling. The pattern applies to any API you want to integrate. Pick the endpoints that matter, wrap them in a script, write a description with clear triggers, and Claude Code can use it across every project.
The skill directory at ~/.claude/skills/ is yours to expand. Add more Firecrawl features from the API documentation, or build entirely different skills for other services. Once you understand the SKILL.md structure and how descriptions drive activation, the rest is just implementation. Skills aren't exclusive to Claude Code either. The Firecrawl skill is also available through OpenClaw's ClawHub ecosystem for self-hosted personal agents.
Once you've mastered Claude Code Skills, you should explore Claude Code plugins, it has unlocked a new dimension in how developers build and streamline tasks.
P.S: Check out how we built a Claude Skills generator with Firecrawl's Agent endpoint.
Frequently Asked Questions
My Claude Code skill isn't triggering. What's wrong?
Check three things. First, restart Claude Code. Skills load at startup, so changes won't appear until you exit and run `claude` again. Second, run `/skills` to confirm your skill appears in the list. If it's missing, check that your `SKILL.md` file has valid YAML frontmatter with both `name` and `description` fields. Third, review your description. Vague descriptions like "helps with web stuff" rarely trigger. Add specific phrases users would actually say.
Do I need to restart Claude Code after every change?
Yes. Claude Code reads the skills directory once at startup. Any edits to `SKILL.md` or your scripts require a restart. Exit your session and run `claude` again to load the updated skill.
How do I keep my API key secure?
Store it in `~/.env` or export it in your shell profile. Never hardcode keys in your `SKILL.md` or Python scripts. The `python-dotenv` package loads environment variables automatically, and the key stays outside version control.
Do I need a paid Firecrawl plan to build a Claude Code skill?
No, the free tier includes 500 credits, which should cover creating your first Claude Code skill. Scraping one page costs one credit. Screenshots, markdown extraction, and structured extraction all cost one credit per URL. Search costs one credit per query. Crawling costs one credit per page crawled. For this tutorial, you'll use around 20-50 credits depending on how much you test.
Can I share this skill with my team?
Yes. Move the skill folder from `~/.claude/skills/` to `.claude/skills/` in your project repository and commit it. Anyone who clones the repo gets the skill automatically. Team members will need their own Firecrawl API keys stored in their local environment.
What's the difference between skills and MCP servers?
MCP servers give Claude raw access to an API's tools. Skills teach Claude how to use those tools with your preferences baked in. A Firecrawl MCP server exposes every endpoint with all parameters. This skill exposes five specific features with sensible defaults. Skills also load progressively, consuming fewer tokens than MCP servers that load everything upfront.
Can I use multiple Claude Code skills together?
Yes, Claude can activate different skills for different parts of a conversation. If you have a Firecrawl skill and a PDF skill, Claude will use Firecrawl for web requests and the PDF skill for document processing. Skills don't conflict as long as their descriptions target different use cases.
What's the difference between skills and slash commands?
Slash commands are explicit. You type `/command` and Claude runs a predefined prompt. Skills, on the other hand, are implicit. Claude reads your request, matches it against skill descriptions, and activates the right one automatically. Use slash commands for actions you repeat verbatim, like `/commit` or `/review`. Use skills for capabilities Claude should discover on its own based on context. A Firecrawl slash command would require you to remember and type it. A Firecrawl skill activates when you say "grab the markdown from this page" without thinking about which tool to invoke.
Can I install pre-built skills instead of building from scratch?
Yes. Anthropic maintains an official skills repository at github.com/anthropics/skills with production-ready skills for document creation (PDF, DOCX, XLSX, PPTX), Slack GIF creation, and more. Community collections like Superpowers add structured workflow skills for brainstorming, planning, systematic debugging, and verification. Install any of them with `/plugin add marketplace https://github.com/anthropics/skills`. Building from scratch is still useful if you need specific behavior, custom defaults, or integration with a private API.
Do Claude Code skills work with other AI coding tools besides Claude Code?
Yes. Skills rely on filesystem access and the ability to run commands, not on Claude Code specifically. Any coding agent with those capabilities, including Codex CLI and Gemini CLI, can read the same SKILL.md files without modification. You write a skill once and it works wherever the model can read files and execute scripts.
What's the difference between a skill and a plugin?
Skills are markdown files you create or copy into `~/.claude/skills/`. They trigger automatically based on context, load progressively, and encode specific workflows with your preferences baked in. No installation step required. Plugins are packaged integrations installed through Claude Code's plugin system. They bundle MCP servers, tools, and sometimes skills into a single install and are designed for distribution. Use a skill when you want control over a specific workflow. Use a plugin when you want a maintained, pre-packaged integration without the setup overhead.

data from the web