Building an Intelligent Code Documentation RAG Assistant with DeepSeek and Firecrawl

Building an Intelligent Code Documentation Assistant: RAG-Powered DeepSeek Implementation
Introduction
DeepSeek R1's release made waves in the AI community, with countless demos highlighting its impressive capabilities. However, most examples only scratch the surface with basic prompts rather than showing practical real-world implementations.
In this tutorial, we'll explore how to harness this powerful open-source model to create a documentation assistant powered by RAG (Retrieval Augmented Generation). Our application will be able to intelligently answer questions about any documentation website by combining DeepSeek's language capabilities with efficient information retrieval.
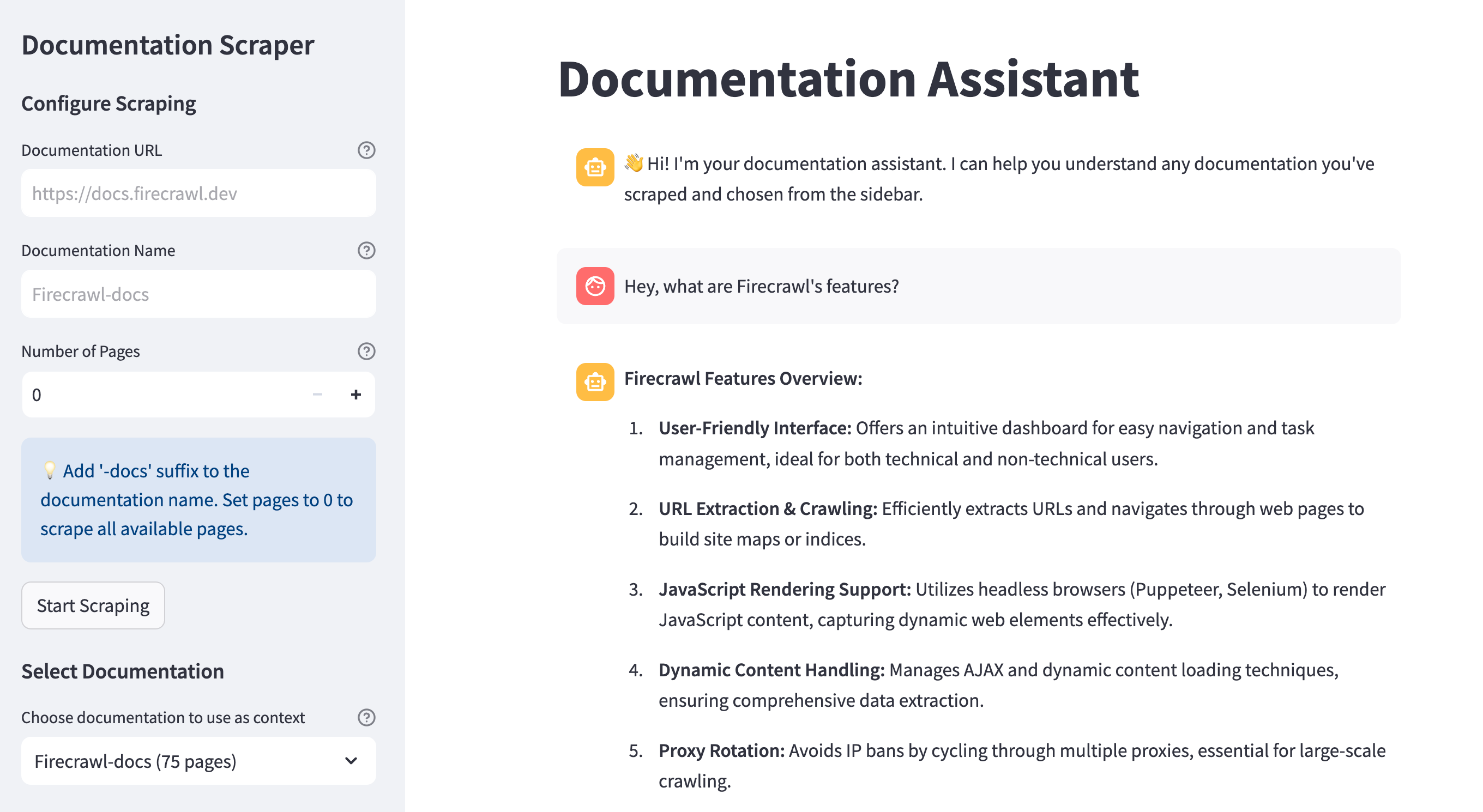
For those eager to try it out, you can find installation and usage instructions in the GitHub repository. If you're interested in understanding how the application works and learning to customize it for your needs, continue reading this detailed walkthrough.
What Is DeepSeek R1?

DeepSeek R1 represents a notable advancement in artificial intelligence, combining reinforcement learning and supervised fine-tuning in a novel and most importantly, open-source approach. The model comes in two variants: DeepSeek-R1-Zero, trained purely through reinforcement learning, and DeepSeek-R1, which undergoes additional training steps. Its architecture manages 671 billion total parameters, though it operates efficiently with 37 billion active parameters and handles context lengths up to 128,000 tokens.
The development journey progressed through carefully planned stages. Beginning with supervised fine-tuning for core capabilities, the model then underwent two phases of reinforcement learning. These RL stages shaped its reasoning patterns and aligned its behavior with human thought processes. This methodical approach produced a system capable of generating responses, performing self-verification, engaging in reflection, and constructing detailed reasoning across mathematics, programming, and general problem-solving.
When it comes to performance, DeepSeek R1 demonstrates compelling results that rival OpenAI's offerings. It achieves 97.3% accuracy on MATH-500, reaches the 96.3 percentile on Codeforces programming challenges, and scores 90.8% on the MMLU general knowledge assessment. The technology has also been distilled into smaller versions ranging from 1.5B to 70B parameters, built on established frameworks like Qwen and Llama. These adaptations make the technology more accessible for practical use while preserving its core strengths.
In this tutorial, we will use its 14B version but your hardware may support up to 70B parameters. It is important to choose a higher capacity model as this number is the biggest contributor to performance.
Prerequisite: Revisiting RAG concepts
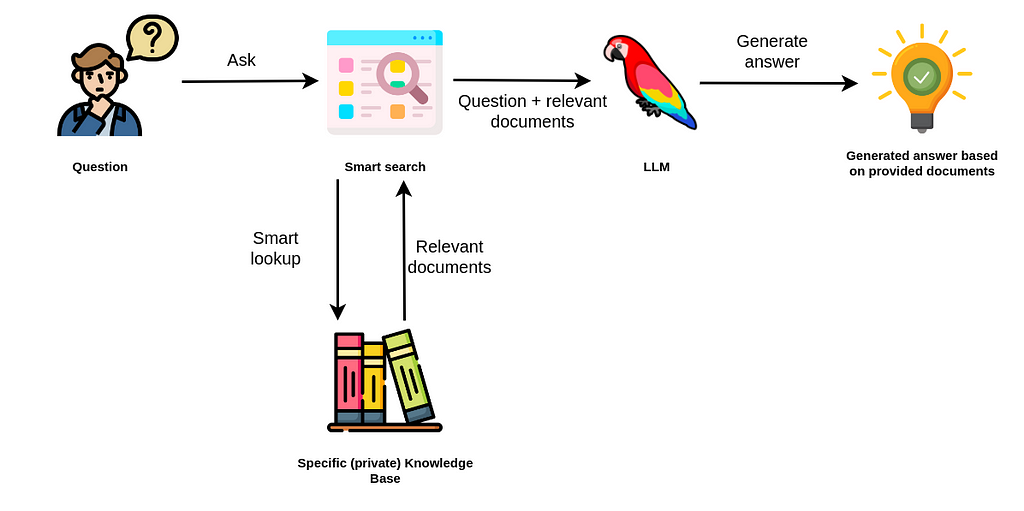
Retrieval Augmented Generation (RAG) represents a significant advancement in how Large Language Models (LLMs) interact with information. Unlike traditional LLMs that rely solely on their training data, RAG combines the power of language models with the ability to retrieve and reference external information in real-time. This approach effectively creates a bridge between the model's inherent knowledge and up-to-date, specific information stored in external databases or documents.
The RAG architecture consists of two main components: the retriever and the generator. The retriever is responsible for searching through a knowledge base to find relevant information based on the user's query. This process typically involves converting both the query and stored documents into vector embeddings, allowing for semantic similarity searches that go beyond simple keyword matching. The generator, usually an LLM, then takes both the original query and the retrieved information to produce a comprehensive, contextually relevant response.
One of RAG's key advantages is its ability to provide more accurate and verifiable responses. By grounding the model's outputs in specific, retrievable sources, RAG helps reduce hallucinations – instances where LLMs generate plausible-sounding but incorrect information. This is particularly valuable in professional contexts where accuracy and accountability are crucial, such as technical documentation, customer support, or legal applications. Additionally, RAG systems can be updated with new information without requiring retraining of the underlying language model, making them more flexible and maintainable.
The implementation of RAG typically involves several technical components working in harmony. First, documents are processed and converted into embeddings using models like BERT or Sentence Transformers. These embeddings are then stored in vector databases such as Pinecone, Weaviate, or FAISS for efficient retrieval. When a query arrives, it goes through the same embedding process, and similarity search algorithms find the most relevant documents. Finally, these documents, along with the original query, are formatted into a prompt that the LLM uses to generate its response. This structured approach ensures that the final output is both relevant and grounded in reliable source material.
Now that we've refreshed our memory on basic RAG concepts, let's dive in to the app's implementation.
Overview of the App
Before diving into the technical details, let's walk through a typical user journey to understand how the documentation assistant works.
The process starts with the user providing documentation URLs to scrape. The app is designed to work with any documentation website, but here are some examples of typical documentation pages:
https://docs.firecrawl.devhttps://docs.langchain.comhttps://docs.streamlit.io
The app's interface is divided into two main sections: a sidebar for documentation management and a main chat interface. In the sidebar, users can:
- Enter a documentation URL to scrape
- Specify a name for the documentation (must end with "-docs")
- Optionally limit the number of pages to scrape
- View and select from previously scraped documentation sets
When a user initiates scraping, the app uses Firecrawl to ingest the documentation site for RAG, converting HTML content into clean markdown files. These files are stored locally in a directory named after the documentation (e.g., "Firecrawl-docs"). The app shows real-time progress during scraping and notifies the user when complete.
After scraping, the documentation is processed into a vector database using the Nomic embeddings model. This enables semantic search capabilities, allowing the assistant to find relevant documentation sections based on user questions. The processing happens automatically when a user selects a documentation set from the sidebar.
The main chat interface provides an intuitive way to interact with the documentation:
- Users can ask questions in natural language about the selected documentation
- The app uses RAG (Retrieval-Augmented Generation) to find relevant documentation sections
- DeepSeek R1 generates accurate, contextual responses based on the retrieved content
- Each response includes an expandable "View reasoning" section showing the chain of thought
Users can switch between different documentation sets at any time, and the app will automatically reprocess the vectors as needed.
This approach combines the power of modern AI with traditional documentation search, creating a more interactive and intelligent way to explore technical documentation. Whether you're learning a new framework or trying to solve a specific problem, the assistant helps you find and understand relevant documentation more efficiently than traditional search methods.
The Tech Stack Used in the App
Building an effective documentation assistant requires tools that can handle complex tasks like web scraping, text processing, and natural language understanding while remaining maintainable and efficient. Let's explore the core technologies that power our application and why each was chosen:
1. Firecrawl for AI-powered documentation scraping
At the heart of our documentation collection system is Firecrawl, the context API to search, scrape, and interact with the web at scale. Unlike traditional scraping libraries that rely on brittle HTML selectors, Firecrawl uses natural language understanding to identify and extract content. This makes it ideal for our use case because:
- It can handle diverse documentation layouts without custom code
- Maintains reliability even when documentation structure changes
- Automatically extracts clean markdown content
- Handles JavaScript-rendered documentation sites
- Provides metadata like titles and URLs automatically
- Follows documentation links intelligently
2. DeepSeek R1 for question answering
For the critical task of answering documentation questions, we use the DeepSeek R1 14B model through Ollama. This AI model excels at understanding technical documentation and providing accurate responses. We chose DeepSeek R1 because:
- Runs locally for better privacy and lower latency
- Specifically trained on technical content
- Provides detailed explanations with chain-of-thought reasoning
- More cost-effective than cloud-based models
- Integrates well with LangChain for RAG workflows
3. Nomic Embeddings for semantic search
To enable semantic search across documentation, we use Nomic's text embedding model through Ollama. This component is crucial for finding relevant documentation sections. We chose Nomic because:
- Optimized for technical documentation
- Runs locally alongside DeepSeek through Ollama
- Produces high-quality embeddings for RAG
- Fast inference speed
- Compact model size
4. ChromaDB for vector storage
To store and query document embeddings efficiently, we use ChromaDB as our vector database. This modern vector store offers:
- Lightweight and easy to set up
- Persistent storage of embeddings
- Fast similarity search
- Seamless integration with LangChain
- No external dependencies
5. Streamlit for user interface
The web interface is built with Streamlit, a Python framework for data applications. We chose Streamlit because:
- It enables rapid development of chat interfaces
- Provides built-in components for file handling
- Handles async operations smoothly
- Maintains chat history during sessions
- Requires minimal frontend code
- Makes deployment straightforward
6. LangChain for RAG orchestration
To coordinate the various components into a cohesive RAG system, we use LangChain. This framework provides:
- Standard interfaces for embeddings and LLMs
- Document loading and text splitting utilities
- Vector store integration
- Prompt management
- Structured output parsing
This carefully selected stack provides a robust foundation while keeping the system entirely local and self-contained. The combination of AI-powered tools (Firecrawl and DeepSeek) with modern infrastructure (ChromaDB, LangChain, and Ollama) creates a reliable and efficient documentation assistant that can handle diverse technical documentation.
Most importantly, this stack minimizes both latency and privacy concerns by running all AI components locally. The infrastructure is lightweight and portable, letting you focus on using the documentation rather than managing complex dependencies or cloud services.
Breaking Down the App Components
When you look at the GitHub repository of the app, you will see the following file structure:
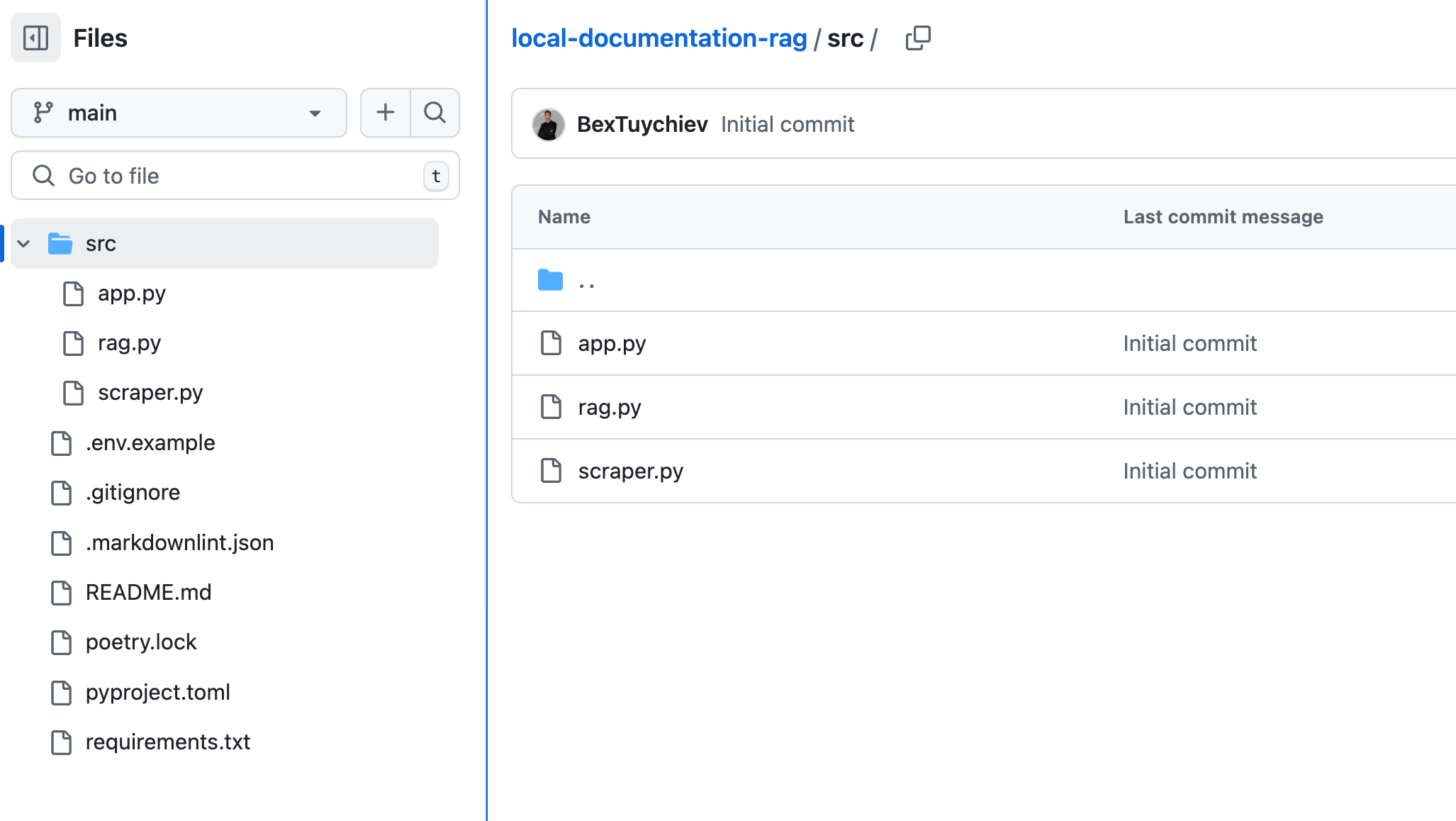
Several files in the repository serve common purposes that most developers will recognize:
.gitignore: Specifies which files Git should ignore when tracking changesREADME.md: Documentation explaining what the project does and how to use itrequirements.txt: Lists all Python package dependencies needed to run the project
Let's examine the remaining Python scripts and understand how they work together to power the application. The explanations will be in a logical order building from foundational elements to higher-level functionality.
1. Scraping Documentation with Firecrawl - src/scraper.py
The documentation scraper component handles fetching and processing documentation pages using Firecrawl's AI capabilities. Let's examine how each part works:
First, we make the necessary imports and setup:
import logging
import os
import re
from pathlib import Path
from typing import List
from dotenv import load_dotenv
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
# Get logger for the scraper module
logger = logging.getLogger(__name__)Then, we define the core data structure for documentation pages:
class DocPage(BaseModel):
title: str = Field(description="Page title")
content: str = Field(description="Main content of the page")
url: str = Field(description="Page URL")The DocPage model represents a single documentation page with three essential fields:
title: The page's heading or titlecontent: The main markdown content of the pageurl: Direct link to the original page
This model is used by both the scraper to structure extracted content and the RAG system to process documentation for the vector store.
The main scraper class handles all documentation collection:
class DocumentationScraper:
def init(self):
self.app = FirecrawlApp()The DocumentationScraper initializes a connection to Firecrawl and provides three main methods for documentation collection:
get_documentation_links: Discovers all documentation pages from a base URL:
def get_documentation_links(self, base_url: str) -> list[str]:
"""Get all documentation page links from a given base URL."""
logger.info(f"Getting documentation links from {base_url}")
initial_crawl = self.app.crawl_url(
base_url,
params={
"scrapeOptions": {"formats": ["links"]},
},
)
all_links = []
for item in initial_crawl["data"]:
all_links.extend(item["links"])
filtered_links = set(
[link.split("#")[0] for link in all_links if link.startswith(base_url)]
)
logger.info(f"Found {len(filtered_links)} unique documentation links")
return list(filtered_links)This method:
- Uses Firecrawl's link extraction mode to find all URLs
- Filters for links within the same documentation domain
- Removes duplicate URLs and anchor fragments
- Returns a clean list of documentation page URLs
scrape_documentation: Processes all documentation pages into structured content:
def scrape_documentation(self, base_url: str, limit: int = None):
"""Scrape documentation pages from a given base URL."""
logger.info(f"Scraping doc pages from {base_url}")
filtered_links = self.get_documentation_links(base_url)
if limit:
filtered_links = filtered_links[:limit]
try:
logger.info(f"Scraping {len(filtered_links)} documentation pages")
crawl_results = self.app.batch_scrape_urls(filtered_links)
except Exception as e:
logger.error(f"Error scraping documentation pages: {str(e)}")
return []
doc_pages = []
for result in crawl_results["data"]:
if result.get("markdown"):
doc_pages.append(
DocPage(
title=result.get("metadata", {}).get("title", "Untitled"),
content=result["markdown"],
url=result.get("metadata", {}).get("url", ""),
)
)
else:
logger.warning(
f"Failed to scrape {result.get('metadata', {}).get('url', 'unknown URL')}"
)
logger.info(f"Successfully scraped {len(doc_pages)} pages out of {len(filtered_links)} URLs")
return doc_pagesThis method:
- Gets all documentation links using the previous method
- Optionally limits the number of pages to scrape
- Uses Firecrawl's batch scraping to efficiently process multiple pages
- Converts raw scraping results into structured
DocPageobjects - Handles errors and provides detailed logging
save_documentation_pages: Stores scraped content as markdown files:
def save_documentation_pages(self, doc_pages: List[DocPage], docs_dir: str):
"""Save scraped documentation pages to markdown files."""
Path(docs_dir).mkdir(parents=True, exist_ok=True)
for page in doc_pages:
url_path = page.url.replace("https://docs.firecrawl.dev", "")
safe_filename = url_path.strip("/").replace("/", "-")
filepath = os.path.join(docs_dir, f"{safe_filename}.md")
with open(filepath, "w", encoding="utf-8") as f:
f.write("---\n")
f.write(f"title: {page.title}\n")
f.write(f"url: {page.url}\n")
f.write("---\n\n")
f.write(page.content)
logger.info(f"Saved {len(doc_pages)} pages to {docs_dir}")This method:
- Creates a documentation directory if needed
- Converts URLs to safe filenames
- Saves each page as a markdown file with YAML frontmatter
- Preserves original titles and URLs for reference
Finally, the class provides a convenience method to handle the entire scraping workflow:
def pull_docs(self, base_url: str, docs_dir: str, n_pages: int = None):
doc_pages = self.scrape_documentation(base_url, n_pages)
self.save_documentation_pages(doc_pages, docs_dir)This scraper component is used by:
- The Streamlit interface (
app.py) for initial documentation collection - The RAG system (
rag.py) for processing documentation into the vector store - The command-line interface for testing and manual scraping
The use of Firecrawl's AI capabilities allows the scraper to handle diverse documentation layouts without custom selectors, while the structured output ensures consistency for downstream processing.
2. Implementing RAG with Ollama - src/rag.py
The RAG (Retrieval Augmented Generation) component is the core of our documentation assistant, handling document processing, embedding generation, and question answering. Let's examine each part in detail:
First, we import the necessary LangChain components:
from langchain_chroma import Chroma
from langchain_community.document_loaders import DirectoryLoader
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama, OllamaEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitterThese imports provide:
Chroma: Vector database for storing embeddingsDirectoryLoader: Utility for loading markdown files from a directoryChatPromptTemplate: Template system for LLM promptsChatOllamaandOllamaEmbeddings: Local LLM and embedding modelsRecursiveCharacterTextSplitter: Text chunking utility
The main RAG class initializes all necessary components:
class DocumentationRAG:
def __init__(self):
# Initialize embeddings and vector store
self.embeddings = OllamaEmbeddings(model="nomic-embed-text")
self.vector_store = Chroma(
embedding_function=self.embeddings, persist_directory="./chroma_db"
)
# Initialize LLM
self.llm = ChatOllama(model="deepseek-r1:14b")
# Text splitter for chunking
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)The initialization:
- Creates an embedding model using Nomic's text embeddings
- Sets up a Chroma vector store with persistent storage
- Initializes the DeepSeek R1 14B model for question answering
- Configures a text splitter with 1000-character chunks and 200-character overlap
The prompt template defines how the LLM should process questions:
# RAG prompt template
self.prompt = ChatPromptTemplate.from_template(
"""
You are an expert documentation assistant. Use the following documentation context
to answer the question. If you don't know the answer, just say that you don't
have enough information. Keep the answer concise and clear.
Context: {context}
Question: {question}
Answer:"""
)This template:
- Sets the assistant's role and behavior
- Provides placeholders for context and questions
- Encourages concise and clear responses
The document loading method handles reading markdown files:
def load_docs_from_directory(self, docs_dir: str):
"""Load all markdown documents from a directory"""
markdown_docs = DirectoryLoader(docs_dir, glob="*.md").load()
return markdown_docsThis method:
- Uses
DirectoryLoaderto find all markdown files - Automatically handles file reading and basic preprocessing
- Returns a list of Document objects
The document processing method prepares content for the vector store:
def process_documents(self, docs_dir: str):
"""Process documents and add to vector store"""
# Clear existing documents
self.vector_store = Chroma(
embedding_function=self.embeddings, persist_directory="./chroma_db"
)
# Load and process new documents
documents = self.load_docs_from_directory(docs_dir)
chunks = self.text_splitter.split_documents(documents)
self.vector_store.add_documents(chunks)This method:
- Reinitializes the vector store to clear existing documents
- Loads new documents from the specified directory
- Splits documents into manageable chunks
- Generates and stores embeddings in the vector database
Finally, the query method handles question answering:
def query(self, question: str) -> tuple[str, str]:
"""Query the documentation"""
# Get relevant documents
docs = self.vector_store.similarity_search(question, k=3)
# Combine context
context = "\n\n".join([doc.page_content for doc in docs])
# Generate response
chain = self.prompt | self.llm
response = chain.invoke({"context": context, "question": question})
# Extract chain of thought between <think> and </think>
chain_of_thought = response.content.split("<think>")[1].split("</think>")[0]
# Extract response
response = response.content.split("</think>")[1].strip()
return response, chain_of_thoughtThe query process:
- Performs semantic search to find the 3 most relevant document chunks
- Combines the chunks into a single context string
- Creates a LangChain chain combining the prompt and LLM
- Generates a response with chain-of-thought reasoning
- Extracts and returns both the final answer and reasoning process
This RAG component is used by:
- The Streamlit interface (
app.py) for handling user questions - The command-line interface for testing and development
- Future extensions that need documentation Q&A capabilities
The implementation uses LangChain's abstractions to create a modular and maintainable system while keeping all AI components running locally through Ollama.
3. Building a clean UI with Streamlit - src/app.py
The Streamlit interface brings together the scraping and RAG components into a user-friendly web application. Let's break down each component:
First, we set up basic configuration and utilities:
import glob
import logging
from pathlib import Path
import streamlit as st
from dotenv import load_dotenv
from rag import DocumentationRAG
from scraper import DocumentationScraper
# Configure logging
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
handlers=[logging.StreamHandler()],
)
logger = logging.getLogger(__name__)These imports and configurations:
- Set up logging for debugging and monitoring
- Import our custom RAG and scraper components
- Load environment variables for configuration
Helper functions handle documentation management:
def get_existing_docs():
"""Get all documentation directories with -docs suffix"""
docs_dirs = glob.glob("*-docs")
return [Path(dir_path).name for dir_path in docs_dirs]
def get_doc_page_count(docs_dir: str) -> int:
"""Get number of markdown files in a documentation directory"""
return len(list(Path(docs_dir).glob("*.md")))These utilities:
- Find all documentation directories with "-docs" suffix
- Count pages in each documentation set
- Support the UI's documentation selection features
The scraping configuration section handles documentation collection:
def scraping_config_section():
"""Create the documentation scraping configuration section"""
st.markdown("### Configure Scraping")
base_url = st.text_input(
"Documentation URL",
placeholder="https://docs.firecrawl.dev",
help="The base URL of the documentation to scrape",
)
docs_name = st.text_input(
"Documentation Name",
placeholder="Firecrawl-docs",
help="Name of the directory to store documentation",
)
n_pages = st.number_input(
"Number of Pages",
min_value=0,
value=0,
help="Limit the number of pages to scrape (0 for all pages)",
)
st.info(
"💡 Add '-docs' suffix to the documentation name. "
"Set pages to 0 to scrape all available pages."
)
if st.button("Start Scraping"):
if not base_url or not docs_name:
st.error("Please provide both URL and documentation name")
elif not docs_name.endswith("-docs"):
st.error("Documentation name must end with '-docs'")
else:
with st.spinner("Scraping documentation..."):
try:
scraper = DocumentationScraper()
n_pages = None if n_pages == 0 else n_pages
scraper.pull_docs(base_url, docs_name, n_pages=n_pages)
st.success("Documentation scraped successfully!")
except Exception as e:
st.error(f"Error scraping documentation: {str(e)}")This section:
- Provides input fields for documentation URL and name
- Allows limiting the number of pages to scrape
- Handles validation and error reporting
- Shows progress during scraping
- Uses our
DocumentationScraperclass for content collection
The documentation selection interface manages switching between docs:
def documentation_select_section():
"""Create the documentation selection section"""
st.markdown("### Select Documentation")
existing_docs = get_existing_docs()
if not existing_docs:
st.caption("No documentation found yet")
return None
# Create options with page counts
doc_options = [f"{doc} ({get_doc_page_count(doc)} pages)" for doc in existing_docs]
selected_doc = st.selectbox(
"Choose documentation to use as context",
options=doc_options,
help="Select which documentation to use for answering questions",
)
if selected_doc:
# Extract the actual doc name without page count
st.session_state.current_doc = selected_doc.split(" (")[0]
return st.session_state.current_doc
return NoneThis component:
- Lists available documentation sets
- Shows page counts for each set
- Updates session state when selection changes
- Handles the case of no available documentation
The chat interface consists of two main functions that work together to create the interactive Q&A experience:
First, we initialize the necessary session state:
def initialize_chat_state():
"""Initialize session state for chat"""
if "messages" not in st.session_state:
st.session_state.messages = []
if "rag" not in st.session_state:
st.session_state.rag = DocumentationRAG()This initialization:
- Creates an empty message list if none exists
- Sets up the RAG system for document processing and querying
- Uses Streamlit's session state to persist data between reruns
The main chat interface starts with basic setup:
def chat_interface():
"""Create the chat interface"""
st.title("Documentation Assistant")
# Check if documentation is selected
if "current_doc" not in st.session_state:
st.info("Please select a documentation from the sidebar to start chatting.")
returnThis section:
- Sets the page title
- Ensures documentation is selected before proceeding
- Shows a helpful message if no documentation is chosen
Document processing is handled next:
# Process documentation if not already processed
if (
"docs_processed" not in st.session_state
or st.session_state.docs_processed != st.session_state.current_doc
):
with st.spinner("Processing documentation..."):
st.session_state.rag.process_documents(st.session_state.current_doc)
st.session_state.docs_processed = st.session_state.current_docThis block:
- Checks if the current documentation needs processing
- Shows a loading spinner during processing
- Updates the session state after processing
- Prevents unnecessary reprocessing of the same documentation
Message display is handled by iterating through the chat history:
# Display chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if "chain_of_thought" in message:
with st.expander("View reasoning"):
st.markdown(message["chain_of_thought"])This section:
- Shows each message with appropriate styling based on role
- Displays the main content using markdown
- Creates expandable sections for reasoning chains
- Maintains visual consistency in the chat
Finally, the input handling and response generation:
# Chat input
if prompt := st.chat_input("Ask a question about the documentation"):
# Add user message
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
# Generate and display response
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response, chain_of_thought = st.session_state.rag.query(prompt)
st.markdown(response)
with st.expander("View reasoning"):
st.markdown(chain_of_thought)
# Store assistant response
st.session_state.messages.append({
"role": "assistant",
"content": response,
"chain_of_thought": chain_of_thought,
})This section:
-
Captures user input:
- Uses Streamlit's chat input component
- Stores the message in session state
- Displays the message immediately
-
Generates response:
- Shows a "thinking" spinner during processing
- Queries the RAG system for an answer
- Displays the response with expandable reasoning
-
Updates chat history:
- Stores both response and reasoning
- Maintains the conversation flow
- Preserves the interaction for future reference
The entire chat interface creates a seamless experience by:
- Managing state effectively
- Providing immediate feedback
- Showing processing status
- Maintaining conversation context
- Exposing the AI's reasoning process
Finally, the main application structure:
def sidebar():
"""Create the sidebar UI components"""
with st.sidebar:
st.title("Documentation Scraper")
scraping_config_section()
documentation_select_section()
def main():
initialize_chat_state()
sidebar()
chat_interface()
if __name__ == "__main__":
main()This structure:
- Organizes UI components into sidebar and main area
- Initializes necessary state on startup
- Provides a clean entry point for the application
The Streamlit interface brings together all components into a cohesive application that:
- Makes documentation scraping accessible to non-technical users
- Provides immediate feedback during operations
- Maintains conversation history
- Shows the AI's reasoning process
- Handles errors gracefully
How to Increase System Performance
There are several ways to optimize the performance of this documentation assistant. The following sections explore key areas for potential improvements:
1. Optimize document chunking
In rag.py, we currently use a basic chunking strategy:
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
add_start_index=True
)We can improve this by:
- Using semantic chunking that respects document structure
- Adjusting chunk size based on content type (e.g., larger for API docs)
- Implementing custom splitting rules for documentation headers
- Adding metadata to chunks for better context preservation
Example improved configuration:
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1500, # Larger chunks for more context
chunk_overlap=300, # Increased overlap for better coherence
separators=["\n## ", "\n### ", "\n\n", "\n", " ", ""], # Respect markdown structure
add_start_index=True,
length_function=len,
is_separator_regex=False
)2. Enhance vector search
The current similarity search in rag.py is basic:
docs = self.vector_store.similarity_search(question, k=3)We can improve retrieval by:
- Increasing
k, i.e. the number of chunks returned - Implementing hybrid search (combining semantic and keyword matching)
- Using Maximum Marginal Relevance (MMR) for diverse results
- Adding metadata filtering based on document sections
- Implementing re-ranking of retrieved chunks
Example enhanced retrieval:
def query(self, question: str) -> tuple[str, str]:
# Get relevant documents with MMR
docs = self.vector_store.max_marginal_relevance_search(
question,
k=5, # Retrieve more candidates
fetch_k=20, # Consider larger initial set
lambda_mult=0.7 # Diversity factor
)
# Filter and re-rank results
filtered_docs = [
doc for doc in docs
if self._calculate_relevance_score(doc, question) > 0.7
]
# Use top 3 most relevant chunks
context = "\n\n".join([doc.page_content for doc in filtered_docs[:3]])3. Implement caching
The current implementation reprocesses documentation on every selection:
if (
"docs_processed" not in st.session_state
or st.session_state.docs_processed != st.session_state.current_doc
):
with st.spinner("Processing documentation..."):
st.session_state.rag.process_documents(st.session_state.current_doc)We can improve this by:
- Implementing persistent vector storage with versioning
- Caching processed embeddings
- Adding incremental updates for documentation changes
Example caching implementation:
from hashlib import md5
import pickle
class CachedDocumentationRAG(DocumentationRAG):
def process_documents(self, docs_dir: str):
cache_key = self._get_cache_key(docs_dir)
cache_path = f"cache/{cache_key}.pkl"
if os.path.exists(cache_path):
with open(cache_path, 'rb') as f:
self.vector_store = pickle.load(f)
else:
super().process_documents(docs_dir)
os.makedirs("cache", exist_ok=True)
with open(cache_path, 'wb') as f:
pickle.dump(self.vector_store, f)4. Optimize model loading
Currently, we initialize models in __init__:
def __init__(self):
self.embeddings = OllamaEmbeddings(model="nomic-embed-text")
self.llm = ChatOllama(model="deepseek-r1:14b")We can improve this by:
- Implementing lazy loading of models
- Using smaller models for initial responses
- Adding model quantization options
- Implementing model caching
Example optimized initialization:
class OptimizedDocumentationRAG:
def __init__(self, use_small_model=True):
self._embeddings = None
self._llm = None
self._use_small_model = use_small_model
@property
def llm(self):
if self._llm is None:
model_size = "7b" if self._use_small_model else "14b"
self._llm = ChatOllama(
model=f"deepseek-r1:{model_size}",
temperature=0.1, # Lower temperature for docs
num_ctx=2048 # Reduced context for faster inference
)
return self._llmThese optimizations can significantly improve:
- Response latency
- Memory usage
- Processing throughput
- User experience
Remember to benchmark performance before and after implementing these changes to measure their impact. Also, consider your specific use case - some optimizations might be more relevant depending on factors like user load, documentation size, and hardware constraints.
Conclusion
This local documentation assistant demonstrates how modern AI technologies can be combined to create powerful, practical tools for technical documentation. By using DeepSeek's language capabilities, Firecrawl's AI-powered scraping, and the RAG architecture, we've built a system that makes documentation more accessible and interactive. The application's modular design, with clear separation between scraping, RAG implementation, and user interface components, provides a solid foundation for future enhancements and adaptations to different documentation needs.
Most importantly, this implementation shows that sophisticated AI applications can be built entirely with local components, eliminating privacy concerns and reducing operational costs. The combination of Streamlit's intuitive interface, LangChain's flexible abstractions, and Ollama's local AI models creates a seamless experience that feels like a cloud service but runs entirely on your machine. Whether you're a developer learning a new framework, a technical writer maintaining documentation, or a team lead looking to improve documentation accessibility, this assistant provides a practical solution that can be customized and extended to meet your specific needs.
