How to Build an Automated Competitor Price Monitoring System with Python

TL;DR
- Use Firecrawl's
scrape_urlwith a Pydantic schema to pull structured product data from any e-commerce URL - Store products and competitors in PostgreSQL via SQLAlchemy, with cascading deletes so removing a product cleans up its competitors automatically
- Build the Streamlit UI incrementally: sidebar form, database writes, live dashboard
- Automate price refreshes every 6 hours with a GitHub Actions cron job and repository secrets
Manually checking competitor prices doesn't scale. This tutorial shows how to build an automated system that tracks competitor prices across multiple websites and provides real-time comparisons.
Here is what we'll build:
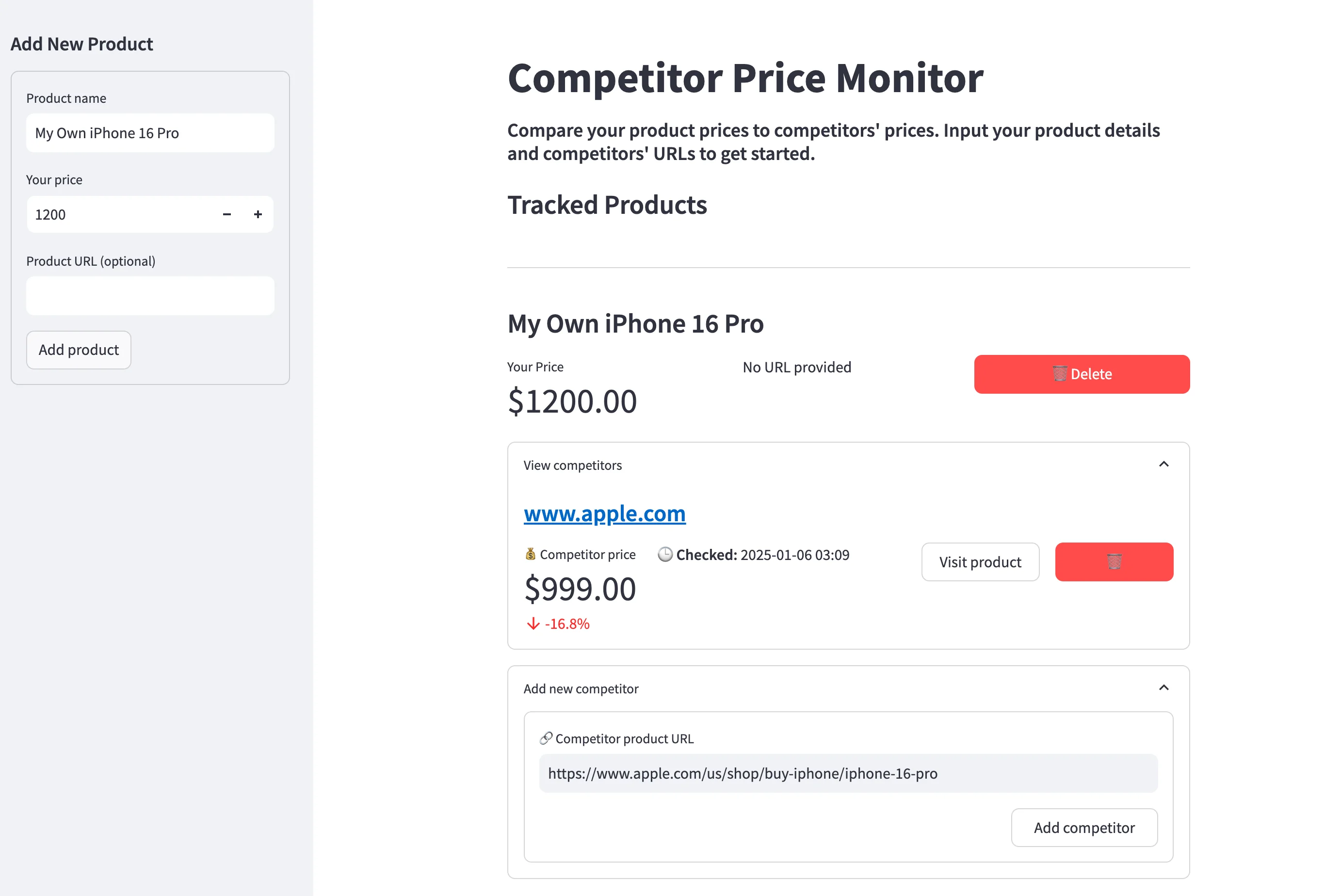
Key features:
- Track your products and their prices
- Monitor multiple competitor URLs per product
- AI-based scraping of competitor prices
- Automated price updates every six hours
- Clean, intuitive dashboard interface
- Price comparison metrics
- One-click competitor website access
To build this app, we will use Python and these key libraries:
- Streamlit for building the web interface
- Firecrawl for AI-powered web scraping
- SQLAlchemy for database management
For infrastructure, we will use:
- Supabase for PostgreSQL database hosting
- GitHub actions for automated price updates
Prerequisites:
- Python 3.8+ installed
- Understanding of Python programming
- GitHub account for hosting and automation
- Supabase account (free tier available)
- Text editor or IDE of your choice
- Basic understanding of web scraping concepts
- Familiarity with SQL and databases
The complete code for the project can be found in this GitHub repository.
Why automate competitor price monitoring?
Competitor price scraping is the process of automatically extracting pricing data from competitor websites and organizing it into a structured format for analysis. Businesses use it to make informed pricing decisions without spending hours manually checking dozens of product pages.
The case for automation comes down to how fast prices move. In e-commerce, prices can change multiple times per day — retailers raise prices during peak traffic hours and drop them during slow periods. Travel and finance sites are even more volatile. Checking prices once a day isn't enough to stay competitive, and doing it manually at any real scale isn't realistic.
There's also a customer behavior angle. Shoppers compare prices across multiple sites before buying, which means your prices are always visible relative to competitors. Understanding what competitors charge — and when they change — lets you make pricing decisions based on what the market is actually doing rather than guesswork.
Before you start scraping, it helps to categorize your competitors: primary (direct competitors selling the same products), secondary (overlapping but not identical), and tertiary (adjacent market players). Focusing your monitoring on primary competitors first gives you the most actionable data with the least noise.
Beyond price, useful data points to consider scraping alongside price include shipping costs, product availability, and promotional offers — all of which affect a customer's actual purchase decision. The system we'll build captures price as the core metric, but the schema is easy to extend.
Step-by-Step Implementation
Let's build this app step by step, starting with what users will see and use. We'll create the interface first and add features one at a time — this makes it easier to understand how everything fits together as we go.
Step 1: Project setup
First, let's set up our project environment. Create a new directory and initialize it with Poetry:
mkdir competitor-price-monitor
cd competitor-price-monitor
poetry initPoetry is a modern dependency management and packaging tool for Python that makes it easy to manage project dependencies, virtual environments, and package distribution. It provides a simpler and more intuitive way to handle Python project dependencies compared to pip and requirements.txt files. Read this Poetry starter guide if you are unfamiliar with the tool.
When you run the poetry init command, Poetry asks some questions to set up your project. When asked for the Python version, type ^3.10. When asked for specifying dependencies interactively, type "no". You can press ENTER for other questions.
Next, you should create this basic project structure:
competitor-price-monitor/
├── src/
│ ├── __init__.py
│ ├── app.py
│ ├── database.py
│ ├── scraper.py
│ └── check_prices.py
├── .env
├── .gitignore
├── pyproject.toml # Automatically created by poetry
└── README.mdHere are the commands:
mkdir -p src
touch src/{__init__.py,app.py,database.py,scraper.py,check_prices.py}
touch .env .gitignore README.md
# Create .gitignore content
cat << 'EOF' > .gitignore
__pycache__/
*.py[cod]
*.egg-info/
.env
.venv/
.idea/
.vscode/
*.db
*.log
.DS_Store
EOFNext, you should install the necessary dependencies with Poetry:
poetry add streamlit firecrawl-py sqlalchemy psycopg2-binary python-dotenv pandas plotlyThis command automatically resolves dependency versions and adds them to pyproject.toml file, which will be crucial later on.
Let's initialize Git and commit the changes:
git add .
git commit -m "Initial commit"Finally, start the Streamlit server to see app updates as you change the src/app.py file in the coming sections.
poetry run streamlit run src/app.pyStep 2: Add a sidebar to the UI for product input
Let's start building the UI inside src/app.py:
import streamlit as st
def main():
st.title("Competitor Price Monitor")
st.markdown(
"##### Compare your product prices to competitors' prices. Input your product details and competitors' URLs to get started."
)
st.markdown("### Tracked Products")
st.markdown("---")
# Sidebar for adding new products
with st.sidebar:
st.header("Add New Product")
add_product()
def add_product():
pass
if __name__ == "__main__":
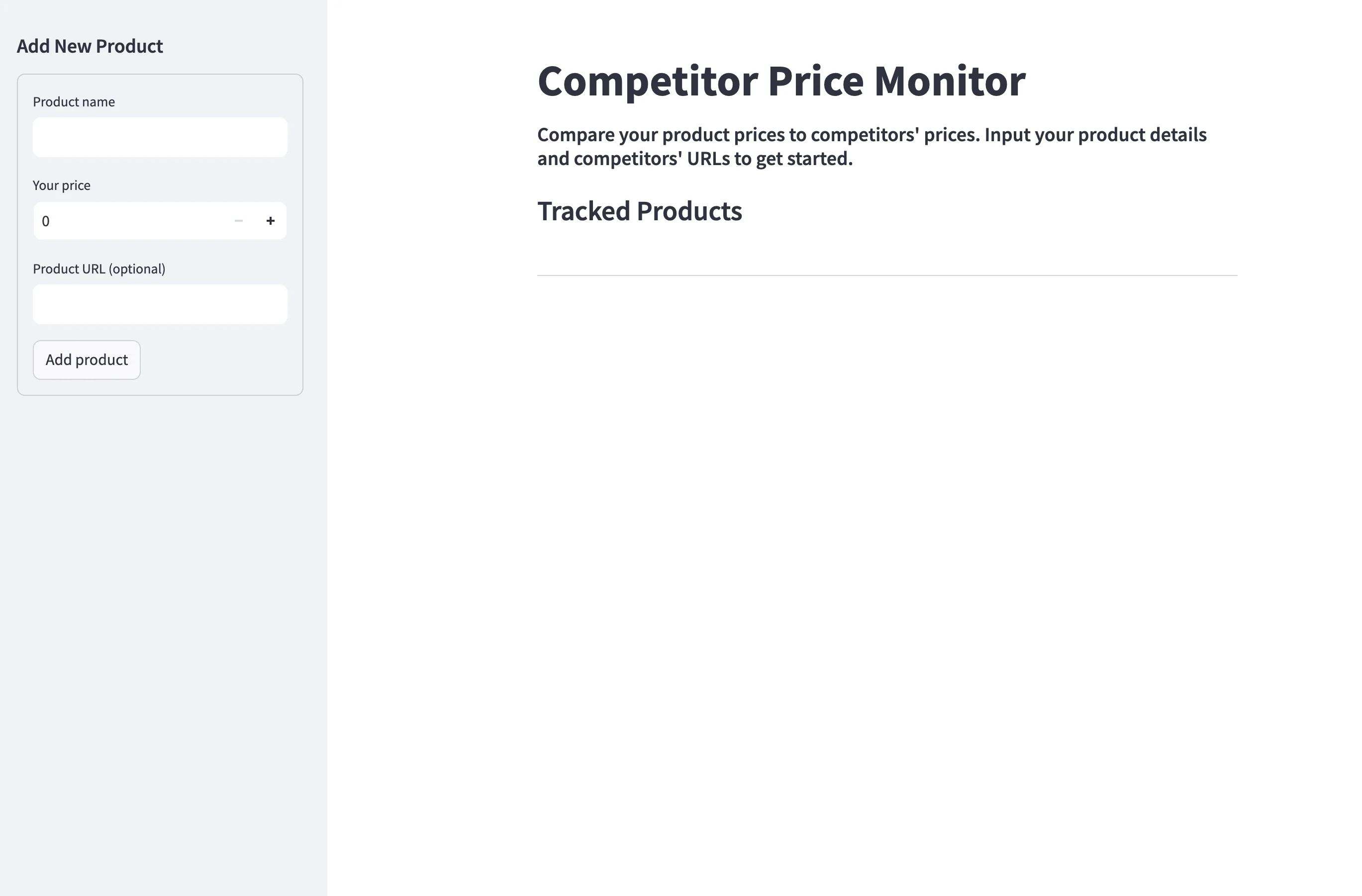
main()We begin by defining a main function that sets up the core UI components — a title, description, and section for tracked products in the main area, along with a sidebar containing a form to add new products using the add_product function. Let's define it next:
# src/app.py
...
def add_product():
"""Form to add a new product"""
with st.form("add_product"):
name = st.text_input("Product name")
price = st.number_input("Your price", min_value=0)
url = st.text_input("Product URL (optional)")
if st.form_submit_button("Add product"):
st.success(f"Added product: {name}")
return True
return False
The add_product function creates a form in the sidebar that allows users to input details for a new product they want to track. It collects the product name, price, and an optional URL. For now, when submitted, it displays a success message and returns True. In the next step, we will set up a database to store products added through this form.
For now, your app must be looking like this:
Let's commit the latest changes now:
git add .
git commit -m "Add a form to collect new products"Step 3: Store new products in PostgreSQL table
To capture products entered through the form, we need an online database. In this case, Postgres is the best option since it's reliable and scalable.
There are many platforms for hosting Postgres instances but the one I find the easiest and fastest to set up is Supabase. So, please head over to the Supabase website and create your free account. During the sign-up process, you will be given a password, which you should save somewhere safe on your machine.
Then, in a few minutes, your free Postgres instance comes online. To connect to this instance, click on Home in the left sidebar and then, "Connect":
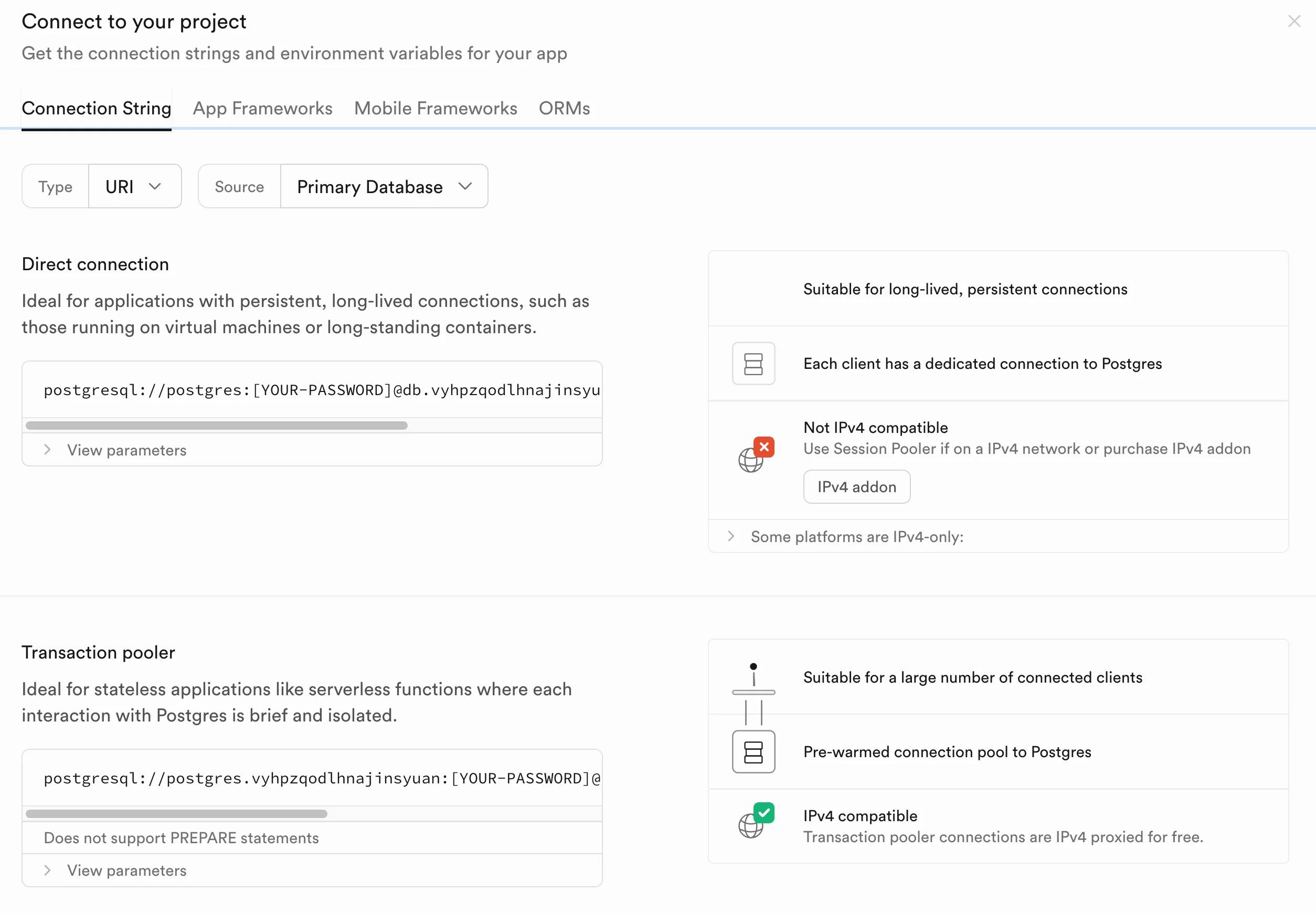
The menu displays different ways to connect to your database. We'll use the connection URI with transaction pooling enabled, as this provides the best balance of performance and reliability. So, copy the "Transaction pooler" URI and return to your working environment.
Open the .env file you created in the project setup step and paste the following variable:
POSTGRES_URL="THE-SUPABASE-URL-STRING-WITH-YOUR-PASSWORD-ADDED"The connection string contains a [YOUR-PASSWORD] placeholder which you should replace with the password you copied when creating your Supabase account and project (remove the brackets).
Then, open src/database.py and paste the following code:
# src/database.py
from sqlalchemy import create_engine, Column, String, Float, DateTime, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship, declarative_base
from datetime import datetime
import uuid
Base = declarative_base()
class Product(Base):
__tablename__ = "products"
id = Column(String, primary_key=True, default=lambda: str(uuid.uuid4()))
name = Column(String, nullable=False)
your_price = Column(Float, nullable=False)
url = Column(String)The code above defines a SQLAlchemy model for storing product information in a PostgreSQL database. SQLAlchemy is a Python SQL toolkit and Object-Relational Mapping (ORM) library that provides a high-level, Pythonic interface for interacting with databases.
Key benefits of SQLAlchemy include:
- Writing database operations using Python classes and methods instead of raw SQL
- Automatic handling of database connections and transactions
- Database-agnostic code that works across different SQL databases
- Built-in security features to prevent SQL injection
The Product model defines a table with the following columns:
id: A unique identifier generated using UUID4name: The product name (required)your_price: The product's price in your store (required)url: The product URL (optional)
The model uses SQLAlchemy's declarative base system which automatically maps Python classes to database tables. When we create the tables, SQLAlchemy will generate the appropriate SQL schema based on these class definitions.
Now, return src/app.py and make the following below.
- Change the imports:
import os
from database import Product, Base
from dotenv import load_dotenv
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
import streamlit as st- Load environment variables from
.envand set up the database:
# Load environment variables
load_dotenv()
# Database setup - creates the tables we specify
engine = create_engine(os.getenv("POSTGRES_URL"))
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)The code above sets up the core database infrastructure for our application. First, it loads environment variables from a .env file using python-dotenv, which allows us to securely store sensitive information like database credentials.
Then it initializes the SQLAlchemy engine by creating a connection to our PostgreSQL database using the POSTGRES_URL from our environment variables. The create_all() call creates any database tables that don't already exist, based on the models we defined (like the Product model).
Finally, it creates a Session factory using sessionmaker. Sessions handle database transactions and provide an interface for querying and modifying data. Each database operation will create a new Session instance to ensure thread safety.
- Update the
add_product()function:
def add_product():
"""Form to add a new product"""
with st.form("add_product"):
name = st.text_input("Product name")
price = st.number_input("Your price", min_value=0)
url = st.text_input("Product URL (optional)")
if st.form_submit_button("Add product"):
session = Session()
product = Product(name=name, your_price=price, url=url)
session.add(product)
session.commit()
session.close()
st.success(f"Added product: {name}")
return True
return FalseThis time, when the form is submitted, a new Product instance is created and saved to the database using SQLAlchemy's session management.
The rest of the script stays the same. Now, try adding a few products through the form - the functionality stays the same but the products are captured in the database.
Then, commit the latest changes to Git:
git add .
git commit -m "Connect the sidebar form to a database table"Step 4: Display products in the main dashboard
When the user opens our app, products existing in the database must be shown automatically like below:
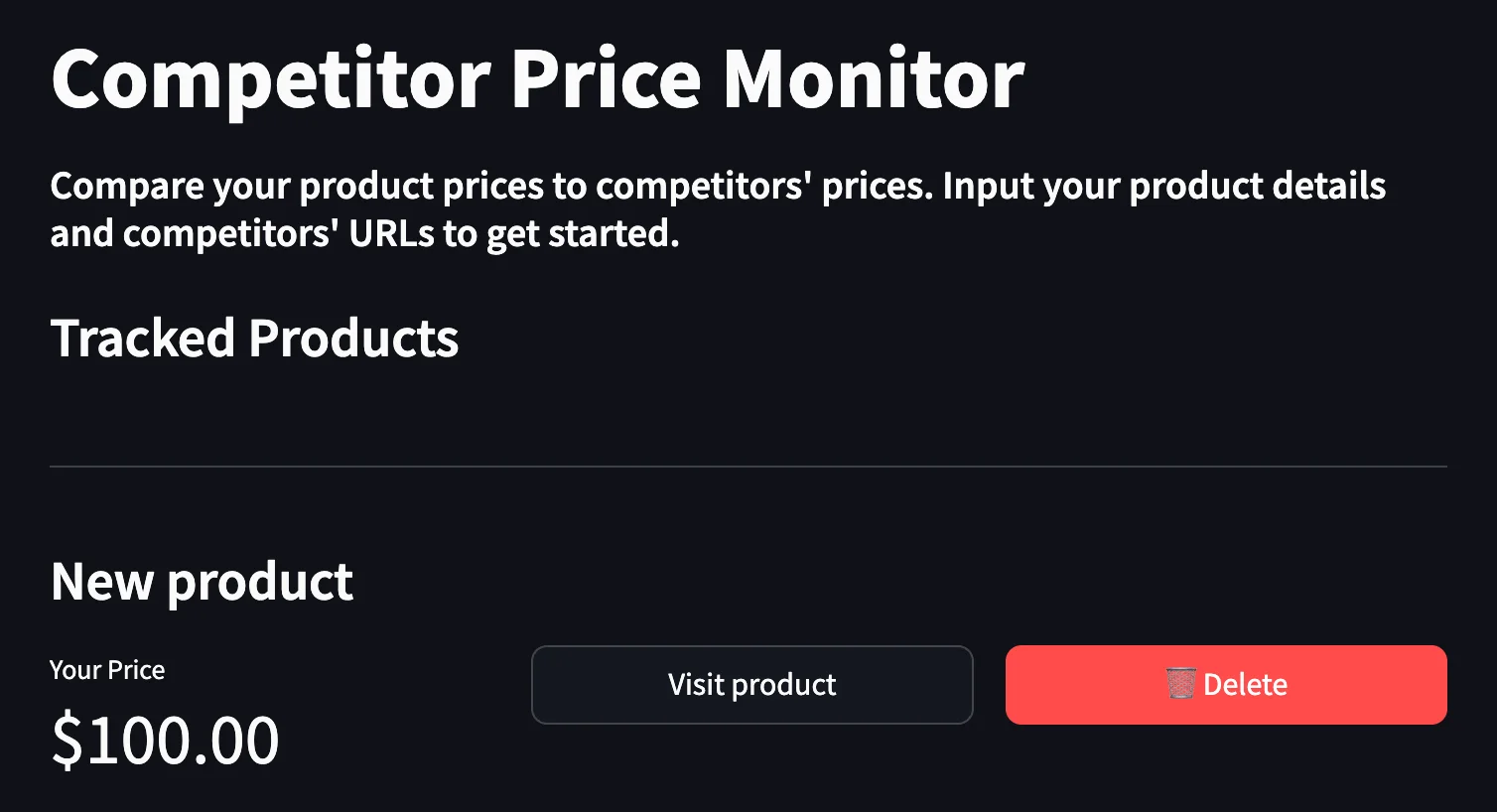
Right below the "Tracked Products" text, we want to display each product's name, its price, and two buttons for visiting and deleting the product. Let's implement these features in src/app.py.
- Import the
webbrowsermodule:
# src/app.py
... # the rest of the imports
import webbrowserThis module provides functions to open URLs in the default web browser, which we'll use for the "Visit product" button.
- Add a function to delete a product from the Products table:
def delete_product(product_id: str):
"""Delete a product and all its competitors"""
session = Session()
product = session.query(Product).filter_by(id=product_id).first()
if product:
session.delete(product)
session.commit()
session.close()The delete_product function takes a product ID as a string parameter and removes the corresponding product from the database. It first creates a new database session, then queries the Products table to find the product with the matching ID. If found, it deletes the product and commits the change to persist it. Finally, it closes the database session to free up resources. This function will be called when the user clicks the delete button for a specific product.
- Add a function to display existing products with Streamlit
containercomponents:
def display_product_details(product):
"""Display details for a single product"""
st.subheader(product.name)
cols = st.columns([1, 2])
with cols[0]:
st.metric(
label="Your Price",
value=f"${product.your_price:.2f}",
)
with cols[1]:
col1, col2 = st.columns(2)
with col1:
if product.url:
st.button(
"Visit product",
key=f"visit_btn_{product.id}",
use_container_width=True,
on_click=lambda: webbrowser.open_new_tab(product.url),
)
else:
st.text("No URL provided")
with col2:
st.button(
"🗑️ Delete",
key=f"delete_btn_{product.id}",
type="primary",
use_container_width=True,
on_click=lambda: delete_product(product.id),
)The display_product_details function takes a product object as input and creates a nicely formatted display layout using Streamlit components. It shows the product name as a subheader and splits the display into two main columns.
In the first column (1/3 width), it displays the product's price using Streamlit's metric component, which shows the price formatted with a dollar sign and 2 decimal places.
The second column (2/3 width) is further divided into two equal sub-columns that contain action buttons:
- A "Visit product" button that opens the product URL in a new browser tab (if a URL exists), otherwise displays "No URL provided".
- A "Delete" button with a trash can emoji that calls the
delete_productfunction to remove the product from the database.
The function uses Streamlit's column layout system to create a responsive grid layout, and the buttons are configured to use the full width of their containers. Each button is given a unique key based on the product ID to ensure proper rendering.
- Update the
mainfunction to use thedisplay_product_detailsfunction when the app is loaded:
def main():
st.title("Competitor Price Monitor")
st.markdown(
"##### Compare your product prices to competitors' prices. Input your product details and competitors' URLs to get started."
)
st.markdown("### Tracked Products")
st.markdown("---")
# Sidebar for adding new products
with st.sidebar:
st.header("Add New Product")
add_product()
# Main content area
session = Session()
products = session.query(Product).all()
if not products:
st.info("No products added yet. Use the sidebar to add your first product.")
else:
for product in products:
with st.container():
display_product_details(product)
session.close()The updated main function adds several key improvements:
The main content area now displays all tracked products in an organized way. It first queries the database to get all products, then handles two scenarios:
- If no products exist, it shows a helpful message guiding users to add their first product
- If products exist, it displays each one in its own container using the
display_product_detailsfunction, which creates a consistent and professional layout for each product
The function also properly manages database connections by creating a session at the start and ensuring it's closed when done, following best practices for database handling.
After this step, the fake products you added in the last step must be visible in the dashboard:
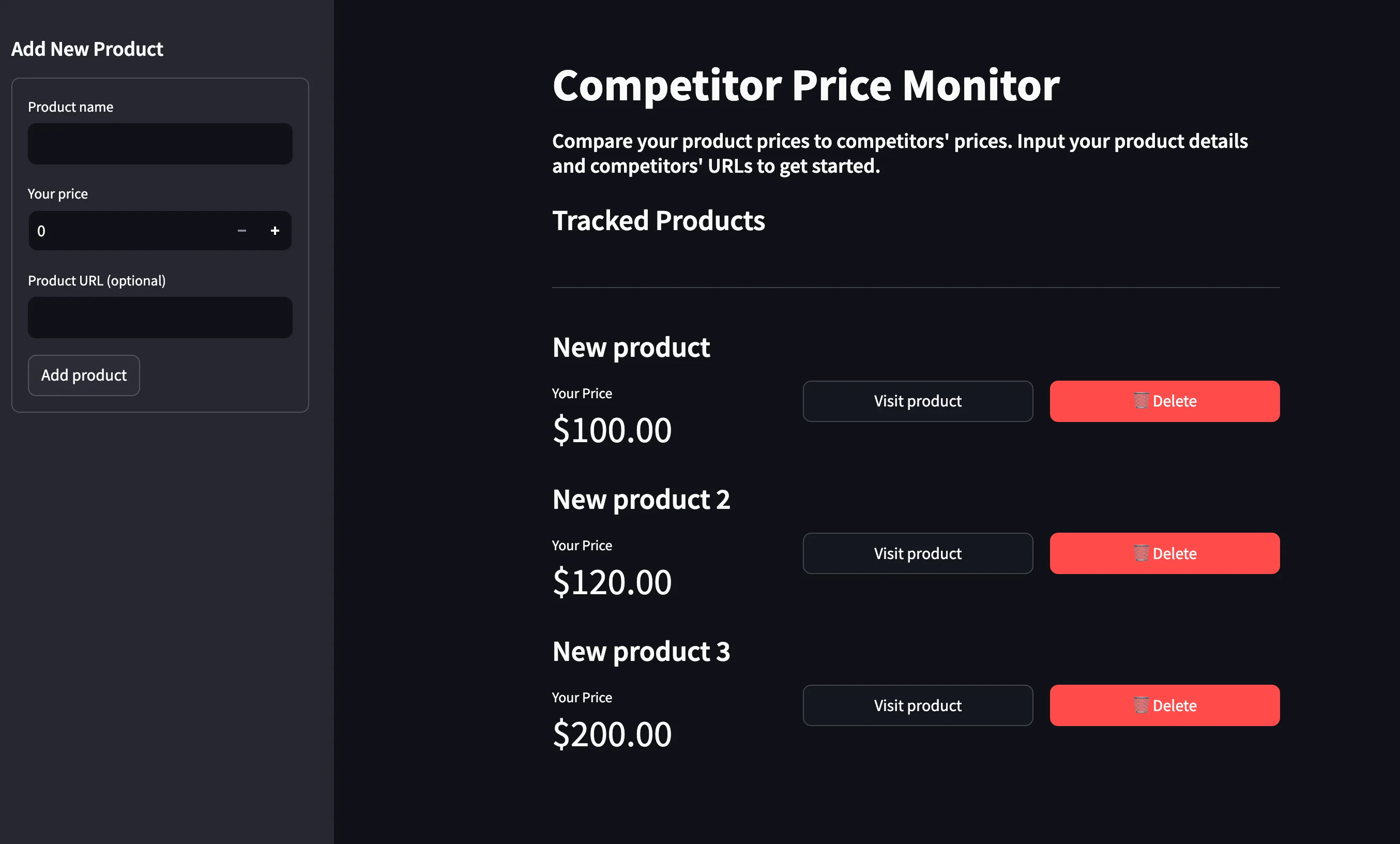
Check to see if the buttons work (which they should!), then remove all fake products to verify that the app correctly displays a message when there are no products in the database.
Then, commit the latest changes in your terminal:
git add .
git commit -m "Display existing products in the database"Step 5: Add a form to capture competing product URLs
Now, the app must allow users to add any number of competing products to each product. To enable this functionality, we will add a small form to capture competing product URLs in each product container.
Inside src/app.py, add this new function:
def add_competitor_form(product, session):
"""Form to add a new competitor"""
with st.expander("Add new competitor", expanded=False):
with st.form(f"add_competitor_{product.id}"):
competitor_url = st.text_input("🔗 Competitor product URL")
col1, col2 = st.columns([3, 1])
with col2:
submit = st.form_submit_button(
"Add competitor", use_container_width=True
)
if submit:
# TODO: Add competitor to the database
st.success("Competitor added successfully!")The add_competitor_form function creates a collapsible form for each product that allows users to add competitor URLs. It takes a product and database session as parameters.
Inside the form, it displays a text input field for the competitor's URL and a submit button in a two-column layout. When submitted, it currently just shows a success message since the database functionality is not yet implemented.
The form is hidden by default but can be expanded by clicking. Each form has a unique key based on the product ID to avoid conflicts when multiple products are displayed.
To add the form to the app, update the main function again:
def main():
... # The rest of the function
if not products:
st.info("No products added yet. Use the sidebar to add your first product.")
else:
for product in products:
with st.container():
display_product_details(product)
add_competitor_form(product, session)
session.close()Here, we are adding a single line of code that calls the add_competitor_form function. After this change, the app must be looking like this:
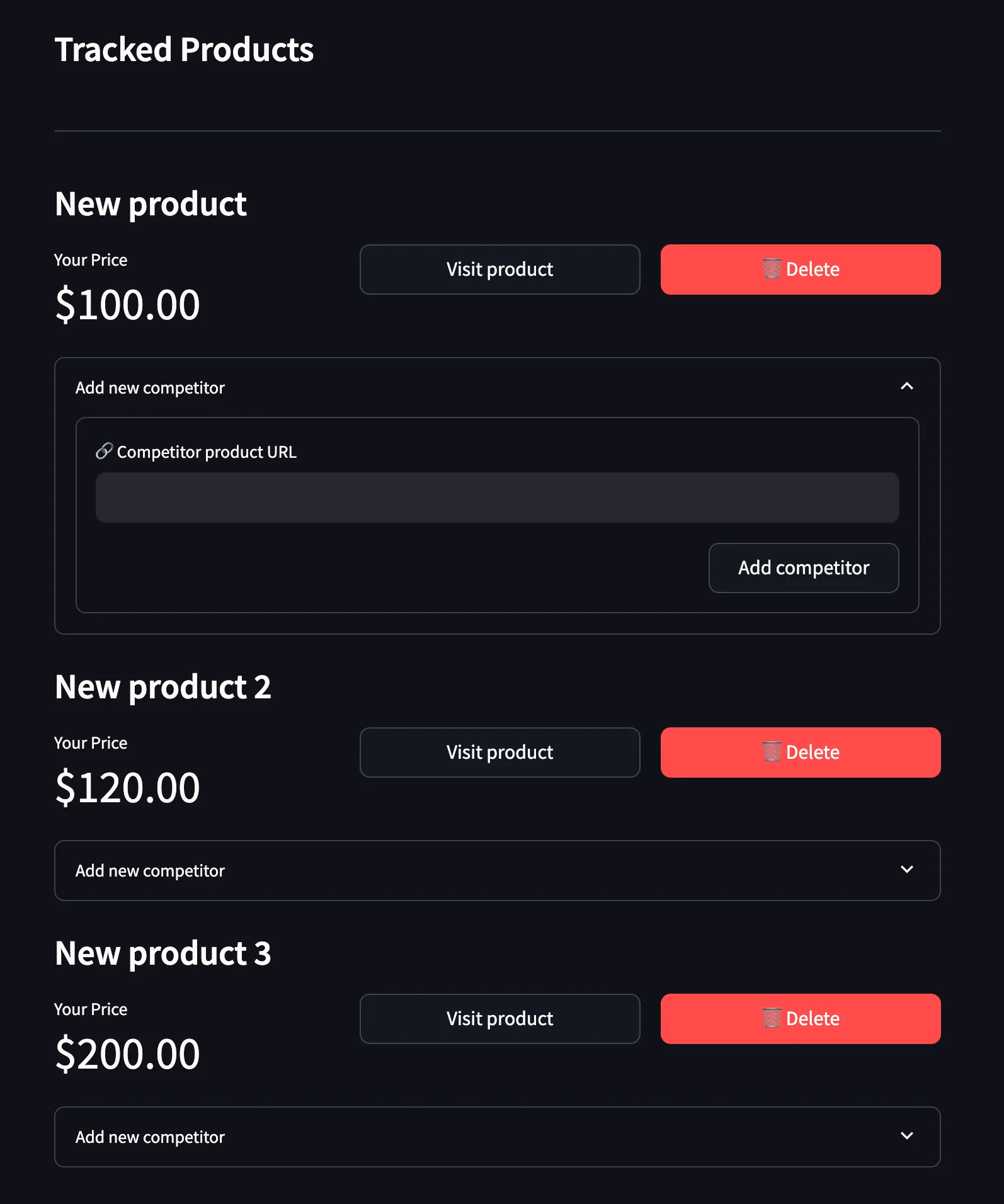
Capture the changes again with Git:
git add .
git commit -m "Add a form to capture competitor product URLs"Step 6: Scrape competitor product details
When a user enters a competing product URL, the app must automatically scrape that product's details like name, brand, and most importantly its price. Then, this information must be saved to a database, all under the hood. In this step, we will implement the scraping part using Firecrawl.
Firecrawl is an AI-powered scraping API that can automatically extract the information you need without relying on HTML and CSS selectors. So, you need to sign up for a free Firecrawl account for this step. After the sign up, you will be given an API key, which you should store as an environment variable in your .env file like below:
POSTGRES_URL="YOUR-POSTGRES-URL"
FIRECRAWL_API_KEY="fc-YOUR-FC-API-KEY"The next step is to add the following imports to src/scraper.py:
# src/scraper.py
import warnings
warnings.filterwarnings("ignore")
from datetime import datetime
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
from dotenv import load_dotenv
load_dotenv()
app = FirecrawlApp()The imports set up the scraping module: FirecrawlApp provides the AI-powered scraping capabilities, BaseModel and Field from Pydantic are used for data validation, and load_dotenv loads the API key from .env. A FirecrawlApp instance is initialized and ready to use.
Next, we create a new Pydantic model to specify the structure of scraped information about each competitor product:
# src/scraper.py
class CompetitorProduct(BaseModel):
"""Schema for extracting competitor product data"""
name: str = Field(description="The name/title of the product")
price: float = Field(description="The current price of the product")
image_url: str | None = Field(None, description="URL of the main product image")Pydantic models are data validation classes that help define the structure and types of data you want to extract. When used with Firecrawl, they act as a schema that tells the AI what information to look for and extract from web pages.
The CompetitorProduct model above defines three fields that we want to extract from competitor product pages:
name: A required string field for the product title/nameprice: A required float field for the product's priceimage_url: An optional string field for the product's main image URL
The Field descriptions provide hints to Firecrawl's AI about what each field represents, helping it accurately identify and extract the right information from diverse webpage layouts. This model will be used to automatically parse competitor product pages into a consistent format.
If you want to capture more than price, the schema is straightforward to extend. For example, adding shipping cost and availability looks like this:
class CompetitorProduct(BaseModel):
name: str = Field(description="The name/title of the product")
price: float = Field(description="The current price of the product")
image_url: str | None = Field(None, description="URL of the main product image")
shipping_cost: float | None = Field(None, description="Shipping cost, 0 if free shipping")
in_stock: bool | None = Field(None, description="Whether the product is currently in stock")These fields often affect a customer's actual purchase decision as much as the listed price — a competitor charging $5 less but with $10 shipping isn't actually cheaper. Add whichever fields are relevant to your use case and update the Competitor database model in src/database.py to match.
Next, we define a function that performs the scraping process with Firecrawl:
def scrape_competitor_product(url: str) -> dict:
"""
Scrape product information from a competitor's webpage
"""
extracted_data = app.scrape_url(
url,
params={
"formats": ["extract"],
"extract": {
"schema": CompetitorProduct.model_json_schema(),
},
},
)
# Add timestamp to the extracted data
data = extracted_data["extract"]
data["last_checked"] = datetime.utcnow()
return dataThe scrape_competitor_product function takes a URL as input and uses Firecrawl's AI-powered scraping capabilities to extract product information from competitor websites. Here's how it works:
- The function accepts a single parameter
urlwhich is the webpage to scrape - It calls Firecrawl's
scrape_urlmethod with two key parameters:formats: Specifies we want to use the "extract" format for structured data extractionextract: Provides thePydanticschema that defines what data to extract
- The
CompetitorProductschema is converted to JSON format and passed as the extraction template - After scraping, it pulls out just the extracted data from the response
- A timestamp is added to track when the price was checked
- Finally, it returns a dictionary containing the product name, price, image URL and timestamp
This function abstracts away the complexity of web scraping by using Firecrawl's AI to automatically locate and extract the relevant product details, regardless of the website's specific structure or layout.
In the next step, we will capture the information returned by scrape_competitor_product to a database table.
You can commit the changes now:
git add .
git commit -m "Create a function to scrape competitor product details"Step 7: Store competitor product details in the database
When a user clicks the "Add competitor" button, the app must pass the entered URL to the scrape_competitor_product function. The function will scrape the competitor's product details and passes them to a dedicated database table for competitor products. So, let's create that table in src/database.py:
# Update the `Product` table to add a link to the `competitors` table
class Product(Base):
__tablename__ = "products"
id = Column(String, primary_key=True, default=lambda: str(uuid.uuid4()))
name = Column(String, nullable=False)
your_price = Column(Float, nullable=False)
url = Column(String)
competitors = relationship(
"Competitor", back_populates="product", cascade="all, delete-orphan"
)
class Competitor(Base):
__tablename__ = "competitors"
id = Column(String, primary_key=True, default=lambda: str(uuid.uuid4()))
product_id = Column(String, ForeignKey("products.id"))
url = Column(String, nullable=False)
name = Column(String)
current_price = Column(Float)
last_checked = Column(DateTime, default=datetime.utcnow)
image_url = Column(String)
product = relationship("Product", back_populates="competitors")The above code snippet first adds a new competitors attribute to the Products table. This creates a one-to-many relationship between products and competitors. It also creates a new Competitor table to store details about competitor products, including their URL, name, current price, last checked timestamp, and image URL. The relationship is set up with cascading deletes, so when a product is removed through the delete button in the UI, all its competitor entries are automatically deleted as well.
Now, let's piece together the scrape_competitor_product function from the last step and the database table in the UI so that Add competitor button works as expected.
- Add the following imports to
src/app.py:
import time
from scraper import scrape_competitor_product
from database import Competitor- Replace the
add_competitor_formfunction with this new version:
def add_competitor_form(product, session):
"""Form to add a new competitor"""
with st.expander("Add new competitor", expanded=False):
with st.form(f"add_competitor_{product.id}"):
competitor_url = st.text_input("🔗 Competitor product URL")
col1, col2 = st.columns([3, 1])
with col2:
submit = st.form_submit_button(
"Add competitor", use_container_width=True
)
if submit:
try:
with st.spinner("Fetching competitor data..."):
data = scrape_competitor_product(competitor_url)
competitor = Competitor(
product_id=product.id,
url=competitor_url,
name=data["name"],
current_price=data["price"],
image_url=data.get("image_url"),
last_checked=data["last_checked"],
)
session.add(competitor)
session.commit()
st.success("✅ Competitor added successfully!")
# Refresh the page
time.sleep(1)
st.rerun()
except Exception as e:
st.error(f"❌ Error adding competitor: {str(e)}")This new version of the add_competitor_form function adds several key improvements:
- It adds error handling with
try/exceptto gracefully handle scraping failures - It shows a loading spinner while scraping the competitor URL
- It creates a proper Competitor database record linked to the product
- It displays success/error messages to give feedback to the user
- It automatically refreshes the page after adding a competitor using
st.rerun() - It properly commits the new competitor to the database session
The function now provides a much better user experience with visual feedback and proper error handling while integrating with both the scraper and database components.
After making these changes, try adding a few fake competitors through the app. Any product link from Amazon, eBay, BestBuy or other e-commerce stores will work.
Then, return to your terminal to commit the latest changes:
git add .
git commit -m "Link the Add competitor button to the database"Step 8: Display competitors for each product
Now that the competitor form is working properly, we need to update the UI again so that existing competitors are shown below each product in our database. Here is our target layout after these changes are implemented:
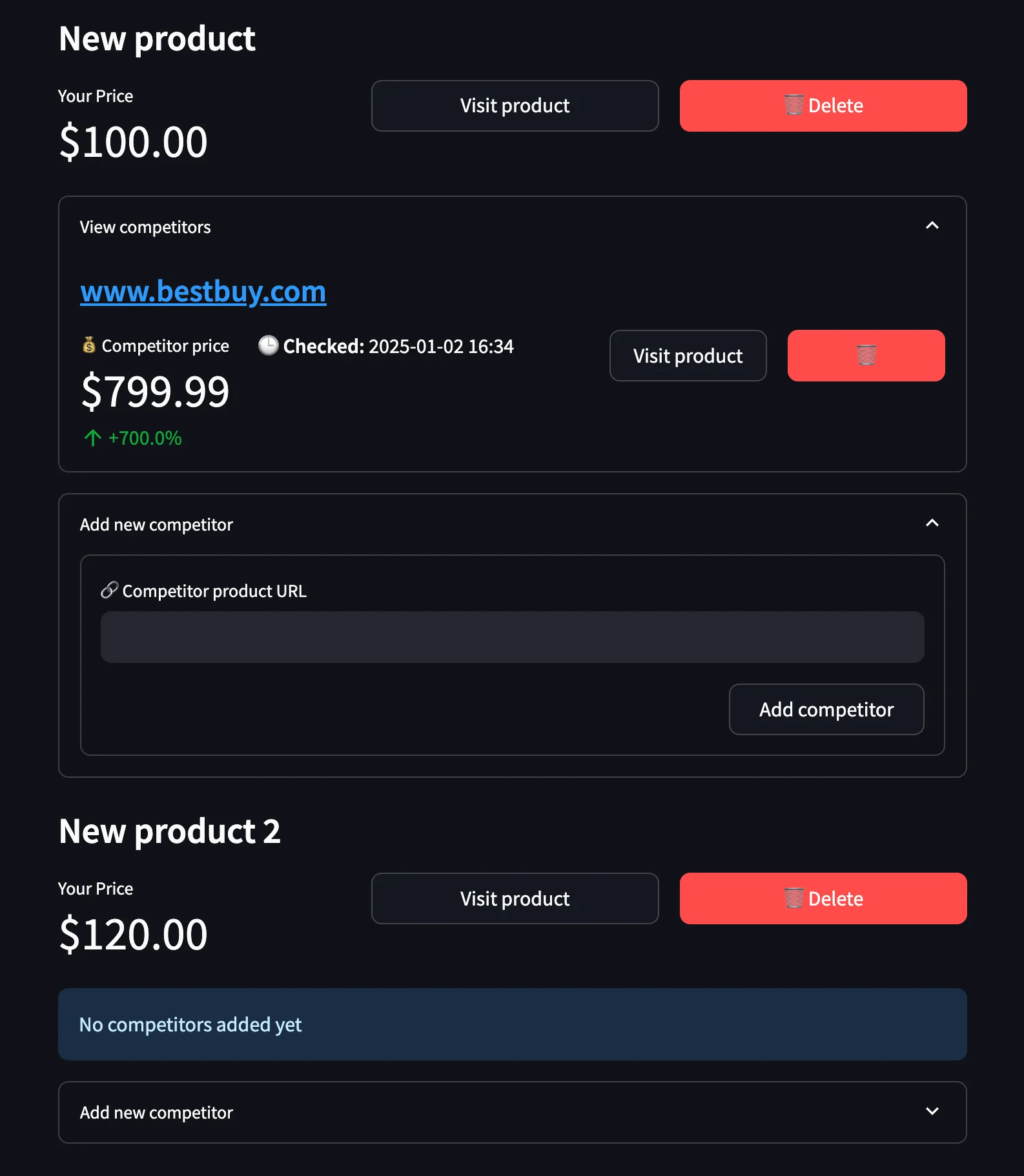
Looking at the screenshot, we can see several key changes to the product layout:
- Each product now has a collapsible "View competitors" section that expands to show all tracked competitors
- For each competitor, we display:
- The competitor's price (e.g. $799.99)
- The price difference percentage compared to our price (e.g. -20.0%)
- When the price was last checked (e.g. 2025-01-02 16:34)
- A "Visit product" link to view the competitor's page
- A delete button to remove the competitor
- The competitor prices are formatted with currency symbols and proper decimal places
- The price difference is color-coded (red for higher prices, green for lower)
- The "Add new competitor" section remains as an expandable form below the competitors list
- Products with no competitors show a "No competitors added yet" message
Let's implement these UI improvements to match this new layout.
First, add this single import statement to src/app.py:
from urllib.parse import urlparseThe urlparse function allows us to extract the domain of a URL.
Next, let's create a function that will later be linked to a button to delete a competitor:
# src/app.py
def delete_competitor(competitor_id: str):
"""Delete a competitor"""
session = Session()
competitor = session.query(Competitor).filter_by(id=competitor_id).first()
if competitor:
session.delete(competitor)
session.commit()
session.close()The delete_competitor function takes a competitor ID as input and removes that competitor from the database. It opens a database session, queries for the competitor with the given ID, deletes it if found, commits the change, and closes the session.
Next, create a function to display competitor details:
def display_competitor_metrics(product, comp):
"""Display competitor price comparison metrics"""
st.markdown(f"#### {urlparse(comp.url).netloc}")
cols = st.columns([1, 2, 1, 1])
diff = ((comp.current_price - product.your_price) / product.your_price) * 100
with cols[0]:
st.metric(
label="💰 Competitor price",
value=f"${comp.current_price:.2f}",
delta=f"{diff:+.1f}%",
delta_color="normal",
)
with cols[1]:
st.markdown(f"**🕒 Checked:** {comp.last_checked.strftime('%Y-%m-%d %H:%M')}")
with cols[2]:
st.button(
"Visit product",
key=f"visit_btn_{comp.id}",
use_container_width=True,
on_click=lambda: webbrowser.open_new_tab(comp.url),
)
with cols[3]:
st.button(
"🗑️",
key=f"delete_comp_btn_{comp.id}",
type="primary",
use_container_width=True,
on_click=lambda: delete_competitor(comp.id),
)The display_competitor_metrics function is responsible for showing competitor price information in a structured layout using Streamlit components. Here's what it does:
-
Takes two parameters:
product: The user's product object containing price and detailscomp: The competitor product object with pricing data
-
Creates a header showing the competitor's domain name (extracted from their URL)
-
Sets up a 4-column layout to display:
- Column 1: Shows the competitor's price with a percentage difference from your price
- Column 2: Shows when the price was last checked/updated
- Column 3: Contains a button to visit the competitor's product page
- Column 4: Contains a delete button to remove this competitor
-
Calculates the price difference percentage between your price and competitor's price
-
Uses Streamlit components:
st.metric: Displays the competitor price with the percentage differencest.markdown: Shows the last checked timestampst.button: Creates interactive buttons for visiting and deleting
-
Integrates with other functions:
- Uses
webbrowser.open_new_tab()for the visit button - Calls
delete_competitor()when delete button is clicked
- Uses
This function creates an interactive and informative UI element that helps users monitor and manage competitor pricing data effectively.
Then, create another function to display all competitors using display_competitor_metrics:
def display_competitors(product):
"""Display all competitors for a product"""
if product.competitors:
with st.expander("View competitors", expanded=False):
for comp in product.competitors:
display_competitor_metrics(product, comp)
else:
st.info("No competitors added yet")The display_competitors function takes a product object as input and displays all competitors associated with that product. If the product has competitors, it creates an expandable section using Streamlit's expander component. Inside this section, it iterates through each competitor and calls the display_competitor_metrics function to show detailed pricing information and controls for that competitor. If no competitors exist for the product, it shows an informational message indicating that no competitors have been added yet.
Finally, let's update the main function to use this last display_competitors function:
def main():
# ... the rest of the function
if not products:
st.info("No products added yet. Use the sidebar to add your first product.")
else:
for product in products:
with st.container():
display_product_details(product)
display_competitors(product) # This line is new
add_competitor_form(product, session)
session.close()Now, the app is almost ready! We just need to implement a feature to update competitor product prices regularly. Let's tackle that in the last two sections.
git add .
git commit -m "Display competitors for each product"Step 9: Write a script to update prices for all items
Currently, once a competing product is added to our database, its details is never updated. Obviously, we have to fix this issue as websites regularly change product prices and run flash sales and discounts. That's where the src/check_prices.py script comes into play.
Once ready, it must rerun the scraper on all existing competing products in the database and fetch their latest details. Let's start by making the following imports and setup:
import os
from database import Base, Product, Competitor
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from scraper import scrape_competitor_product
from dotenv import load_dotenv
load_dotenv()
# Database setup
engine = create_engine(os.getenv("POSTGRES_URL"))
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)Then, we create a single function called update_competitor_prices:
def update_competitor_prices():
"""Update all competitor prices"""
session = Session()
competitors = session.query(Competitor).all()
for competitor in competitors:
try:
# Scrape updated data
data = scrape_competitor_product(competitor.url)
# Update competitor
competitor.current_price = data["price"]
competitor.last_checked = data["last_checked"]
print(f"Updated price for {competitor.name}: ${data['price']}")
except Exception as e:
print(f"Error updating {competitor.name}: {str(e)}")
session.commit()
session.close()The function iterates through all competitor products in the database and fetches their latest prices and details. For each competitor, it:
- Makes a new web request to scrape the current price using
scrape_competitor_productfunction - Updates the competitor record in the database with the new price and timestamp
- Prints success/failure messages for monitoring
- Commits all changes to persist the updates
This allows us to keep our competitor price data fresh and track price changes over time. The function handles errors gracefully by catching and logging exceptions for any competitors that fail to update.
Finally, we add the following code to the end of the script to allow running the script directly:
if __name__ == "__main__":
update_competitor_prices()Try testing the function and refreshing your local Streamlit instance to see the "Last checked" timestamp change for each competitor. Then, you can commit the changes:
git add .
git commit -m "Create a script to check all competitor prices"Step 10: Checking competitor prices regularly with GitHub Actions
Now that we have a script to update competitor prices, we need to run it automatically every few hours. GitHub Actions is perfect for this task since it's free and integrates well with our Git repository.
First, you should create a new GitHub repository to push your code and then, add it as the remote origin:
git add remote origin url-to-your-repo
git pushThen, create a new .github/workflows directory structure in your project root:
mkdir -p .github/workflowsThe .github/workflowsdirectory is where GitHub looks for workflow definition files. These files define automated tasks (called Actions) that GitHub can run for your repository. By creating this directory structure, we're setting up the foundation for automated competitor price checking using GitHub Actions.
Note: if you are unfamiliar with GitHub Actions, check out our deploying web scrapers tutorial to learn more about it.
Next step is exporting our project dependencies to a standard requirements.txt file as GitHub Actions need it to create the correct virtual environment to execute src/check_prices.py:
poetry export -f requirements.txt --output requirements.txtThen, create a new file at .github/workflows/update-prices.yml with the following contents:
name: Check competitor prices
on:
schedule:
# Runs every 6 hours
- cron: "0 0,6,12,18 * * *"
workflow_dispatch: # Allows manual triggering
jobs:
check-prices:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: "3.10"
cache: "pip"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run price checker
env:
FIRECRAWL_API_KEY: ${{ secrets.FIRECRAWL_API_KEY }}
POSTGRES_URL: ${{ secrets.POSTGRES_URL }}
run: python src/check_prices.pyThis workflow does several things:
- Runs automatically every 6 hours using a cron schedule
- Can be triggered manually through GitHub's UI
- Sets up Python and Poetry
- Installs project dependencies
- Runs our price update script with the necessary environment variables
To make this work, you need to add your environment variables as GitHub repository secrets:
- Go to your GitHub repository
- Click Settings → Secrets and variables → Actions
- Click "New repository secret"
- Add both
POSTGRES_URLandFIRECRAWL_API_KEYwith their values
After committing this file, GitHub Actions will start updating your competitor prices automatically every 6 hours UTC time:
git add .
git commit -m "Add GitHub Actions workflow to update prices"
git pushYou can monitor the workflow runs in the "Actions" tab of your GitHub repository. Each run will show you which competitor prices were successfully updated and any errors that occurred.
That's it! You now have a fully automated competitor price monitoring system. The app will keep track of your products, let you add competitors easily, and automatically update their prices every 6 hours using GitHub Actions.
Limitations and Considerations
When implementing this automated competitor price monitoring system, there are several important limitations and considerations to keep in mind:
1. Free Tier Restrictions
-
GitHub Actions Minutes: GitHub provides 2,000 minutes/month of free Actions runtime for public repositories. With our 6-hour schedule (4 runs daily), this averages around 120-240 minutes per month depending on script runtime. Monitor your usage to avoid exceeding limits.
-
Firecrawl API Limits: The free tier of Firecrawl has request limitations. Consider implementing retry logic and error handling for rate limit responses.
2. Legal Considerations
- Always review and respect websites'
robots.txtfiles and Terms of Service - Some e-commerce sites explicitly prohibit automated price monitoring
- Consider implementing delays between requests to avoid overwhelming target servers
- Store only essential data to comply with data protection regulations
3. Data Accuracy
- Price scraping can be affected by:
- Regional pricing differences
- Dynamic pricing systems
- Special offers and discounts
- Currency variations
- Product variants/options
4. Technical Limitations
-
Database Growth: Regular price checks will continuously grow your database. Implement data retention policies or archiving strategies for older price records.
-
Error Handling: The current implementation provides basic error handling. In production, consider adding:
def scrape_competitor_product(url: str) -> dict: retries = 3 while retries > 0: try: # Existing scraping code except Exception as e: retries -= 1 if retries == 0: raise e time.sleep(5) # Wait before retry -
Maintenance Requirements: Regular monitoring is needed to ensure:
- Database connection stability
- API key validity
- Scraping accuracy
- GitHub Actions workflow status
5. Scaling Considerations
- The current architecture may need modifications for scaling:
- Consider implementing a queue system for large numbers of competitors
- Add parallel processing for faster updates
- Implement caching mechanisms
- Consider database indexing and optimization
6. Monitoring and Alerting
- The current implementation lacks comprehensive monitoring
- Consider adding:
- Scraping success/failure metrics
- Database performance monitoring
- API usage tracking
- System health checks
7. Cost Implications for Scaling
As your monitoring needs grow, consider the costs of:
- Upgraded database plans
- Additional GitHub Actions minutes
- Premium API tiers
- Monitoring tools
- Error tracking services
By understanding these limitations and planning accordingly, you can build a more robust and reliable price monitoring system that scales with your needs while staying within technical and legal boundaries.
Handling sites that need a real browser
The scrape_url approach works well for standard product pages where the price is visible in the rendered HTML. But some competitor sites don't cooperate: B2B portals that hide pricing behind a login, pages that require selecting a product variant before the price appears, or sites with aggressive bot detection that blocks API-level requests entirely.
For these cases, Firecrawl Browser Sandbox gives you a full remote browser session. No local Chromium install, no driver setup — Playwright comes pre-installed in the sandbox, and you can execute Python or JavaScript code against a live page.
Here's how you'd modify the scraper to handle a site that requires logging in first:
from firecrawl import FirecrawlApp
app = FirecrawlApp()
# Launch a browser session with a persistent profile
# so login state carries across runs
session = app.browser({
"ttl": 120,
"profile": {
"name": "competitor-monitor",
"saveChanges": True,
},
})
# Log in (only needed on the first run — the persistent
# profile saves cookies for subsequent sessions)
app.browser_execute(session["id"], {
"code": """
await page.goto("https://competitor-portal.com/login");
await page.fill('#email', 'your@email.com');
await page.fill('#password', 'your-password');
await page.click('button[type="submit"]');
await page.waitForNavigation();
""",
"language": "node",
})
# Navigate to a product page and extract the price
result = app.browser_execute(session["id"], {
"code": """
await page.goto("https://competitor-portal.com/product/12345");
await page.waitForSelector('.product-price');
const price = await page.textContent('.product-price');
const name = await page.textContent('.product-title');
console.log(JSON.stringify({ name, price }));
""",
"language": "node",
})
# Close the session (saves profile state for next time)
app.delete_browser(session["id"])The key detail here is the profile parameter. When you create a session with profile.name set and saveChanges set to True, Browser Sandbox saves cookies and localStorage when the session closes. The next time you create a session with the same profile name, the login state is already there — your check_prices.py script can skip the login step on subsequent runs and go straight to scraping.
This approach is useful when:
- Competitor portals require authentication to view pricing (common in B2B, wholesale, or distributor sites)
- Prices appear only after interaction — selecting a size, color, or region before the price renders on the page
- Heavy bot protection blocks API-level scrape requests but allows full browser sessions
For the standard public e-commerce pages covered in this tutorial, scrape_url with a Pydantic schema is the simpler and cheaper option (1 credit per scrape vs. 2 credits per browser minute). Use Browser Sandbox when you hit a wall with pages that won't cooperate with API-level extraction.
See the Browser Sandbox docs for the full reference, including agent-browser shorthand commands and CDP access for connecting your own Playwright instance.
No-code alternative with n8n
You don't have to build a price monitoring system from scratch. If you'd rather skip the Python code and Streamlit UI, no-code workflow tools like n8n can wire together the same pieces — Firecrawl for scraping, Supabase for storage — without writing a single line of code.
n8n is an open-source workflow automation platform that lets you connect APIs and services through a visual drag-and-drop editor. You build workflows by chaining together nodes, where each node handles one step: triggering on a schedule, scraping a URL, transforming data, or writing to a database.
For a competitor price monitoring setup, the workflow would look something like: a cron trigger fires every few hours, a Firecrawl node scrapes each competitor URL, a data transformation node extracts the price fields, and a Supabase node writes the results to your database. n8n handles the orchestration, error retries, and scheduling — the same things we used GitHub Actions and custom Python scripts for in this tutorial.
To see how Firecrawl and Supabase connect in n8n, check out this Firecrawl + Supabase n8n workflow template. It covers scraping web content with Firecrawl and ingesting it into Supabase, which you can adapt for price monitoring by swapping in your competitor URLs and adjusting the data schema. For a deeper look at what's possible with n8n and Firecrawl together, see our guide to web scraping with n8n.
Conclusion
In this tutorial, we've built a complete competitor price monitoring system that automatically tracks product prices across multiple e-commerce websites. Here's what we accomplished:
- Created a user-friendly web interface with Streamlit for managing products and competitors
- Implemented AI-powered web scraping using Firecrawl to handle diverse website layouts
- Set up a PostgreSQL database with SQLAlchemy for reliable data storage
- Automated regular price updates using GitHub Actions
- Added error handling and basic monitoring capabilities
To take this further, you could add email notifications for significant price changes, historical price tracking and trend charts, or deploy the Streamlit app to a cloud platform for broader access. For a more production-ready setup, swapping in a queue system and parallel processing would handle larger sets of competitors more efficiently.
Frequently Asked Questions
How often should I check competitor prices?
It depends on your market. For fast-moving categories like consumer electronics or travel, prices can change multiple times per day — hourly checks make sense. For slower-moving categories like furniture or B2B products, daily or even weekly checks are usually sufficient. The system in this tutorial runs every 6 hours via GitHub Actions, which is a reasonable default for most e-commerce use cases. You can adjust the cron schedule in the workflow file to match your category's volatility.
What happens if a competitor changes their page layout?
Firecrawl's AI-powered extraction is layout-agnostic — it identifies price fields by semantic meaning rather than CSS selectors or DOM paths. This means it's significantly more resilient to page redesigns than traditional scrapers. That said, a major structural change (like moving from a single product page to a dynamically loaded price via API) can still cause extraction to return null. The update_competitor_prices function in check_prices.py catches and logs these failures without stopping the rest of the run, so one failed URL won't break the whole batch.
How much does it cost to run this system?
The infrastructure costs can be near zero on free tiers. GitHub Actions provides 2,000 free minutes per month for public repositories. Supabase's free tier includes a Postgres database with 500MB storage. Firecrawl's free tier covers a limited number of scrape credits per month — enough for testing, but you'll want a paid plan for production use with many competitors checked multiple times a day. At 4 runs per day across 50 competitor URLs, you'd use around 6,000 scrape credits per month, which falls within Firecrawl's Hobby plan.
How do I handle product variants like sizes and colors?
Product variants are one of the trickier parts of price scraping. Many e-commerce sites show a base price on the product listing page and only update it when a specific variant is selected. The simplest approach is to track variant-specific URLs — most platforms generate a unique URL per variant (e.g. ?color=red&size=M). Add those URLs directly as competitor entries instead of the generic product page. If the site doesn't expose variant URLs, you'll need a browser session to interact with the variant selectors before extracting the price.
What should I do when a competitor runs a flash sale?
Flash sales are short-lived and easy to miss with a 6-hour check interval. If your market is prone to aggressive promotions, reduce the cron schedule to every 1–2 hours for key competitors. You can also add a simple alert to check_prices.py: after updating each competitor, compare the new price to the previous one and log or email a notification if the drop exceeds a threshold (e.g. more than 15%). This way you're not just storing prices — you're actively reacting to meaningful changes.
Can I track pricing across multiple currencies?
Yes, but you'll need to normalize prices to a single currency for meaningful comparisons. The CompetitorProduct schema can be extended with a currency field. After scraping, look up the exchange rate via a free API like Open Exchange Rates or Frankfurter and convert to your base currency before storing in the database. Store both the original price and currency alongside the converted value so you can audit the data later. The Competitor model in database.py would need currency and original_price columns added to support this.
How do I know which competitors are worth monitoring?
Start with direct competitors — companies selling the same or near-identical products to the same customer segment. A practical filter: if a customer would consider them as an alternative to you in a purchase decision, they're worth tracking. You can identify these by searching for your top product names and noting which sites appear consistently in results, checking comparison sites and marketplaces where your products are listed, and looking at what sites your customers mention in reviews or support conversations. Start with 5–10 primary competitors and expand from there once the system is running.
