
1. Introduction
Web scraping has become an essential tool for gathering data from the internet. Whether you're tracking prices, collecting news articles, or building a research dataset, Python offers several popular libraries to help you extract information from websites. Two of the most widely used tools are BeautifulSoup4 (BS4) and Scrapy, each with its own strengths and ideal use cases.
Choosing between BS4 and Scrapy isn't always straightforward. BS4 is known for its simplicity and ease of use, making it perfect for beginners and small projects. Scrapy, on the other hand, offers powerful features for large-scale scraping but comes with a steeper learning curve. Making the right choice can save you time and prevent headaches down the road.
In this guide, we'll compare BS4 and Scrapy in detail, looking at their features, performance, and best uses. We'll also explore practical examples and discuss modern alternatives that solve common scraping challenges. By the end, you'll have a clear understanding of which tool best fits your needs and how to get started with web scraping in Python.
Prerequisites
Before diving into the comparison, make sure you have:
- Basic knowledge of Python programming
- Understanding of HTML structure and CSS selectors
- Python 3.7+ installed on your system
- Familiarity with command line interface
- A code editor or IDE of your choice
You'll also need to install the required libraries:
pip install beautifulsoup4 scrapy firecrawl-py pydantic python-dotenv2. Understanding BeautifulSoup4
BeautifulSoup4, often called BS4, is a Python library that helps developers extract data from HTML and XML files. Think of it as a tool that can read and understand web pages the same way your browser does, but instead of showing you the content, it helps you collect specific information from it. BS4 works by turning messy HTML code into a well-organized structure that's easy to navigate and search through.
The library shines in its simplicity. With just a few lines of code, you can pull out specific parts of a webpage like headlines, prices, or product descriptions. Here's a quick example:
from bs4 import BeautifulSoup
import requests
# Get a webpage
response = requests.get('https://news.ycombinator.com')
soup = BeautifulSoup(response.text, 'html.parser')
# Find all article titles
titles = soup.find_all('span', class_='titleline')
for idx, title in enumerate(titles):
print(f"{idx + 1}. {title.text.strip()}")
if idx == 4:
breakThis code demonstrates BeautifulSoup4's straightforward approach to web scraping. It fetches the Hacker News homepage using the requests library, then creates a BeautifulSoup object to parse the HTML. The find_all() method searches for <span> elements with the class "titleline", which contain article titles. The code loops through the first 5 titles, printing each one with its index number. The strip() method removes any extra whitespace around the titles.
The output shows real article titles from Hacker News, demonstrating how BS4 can easily extract specific content from a webpage:
1. The GTA III port for the Dreamcast has been released (gitlab.com/skmp)
2. Arnis: Generate Cities in Minecraft from OpenStreetMap (github.com/louis-e)
3. Things we learned about LLMs in 2024 (simonwillison.net)
4. Journey from Entrepreneur to Employee (akshay.co)
5. Systems ideas that sound good but almost never work (learningbyshipping.com)While BS4 excels at handling static websites, it does have limitations. It can't process JavaScript-generated content, which many modern websites use. It also doesn't handle tasks like managing multiple requests or storing data. However, these limitations are often outweighed by its gentle learning curve and excellent documentation, making it an ideal starting point for anyone new to web scraping. Our web scraping tutorial for beginners walks through your first Python scraper using requests and BeautifulSoup step by step.
Key Features:
- Simple, intuitive API for parsing HTML/XML
- Powerful searching and filtering methods
- Forgiving HTML parser that can handle messy code
- Extensive documentation with clear examples
- Small memory footprint
- Compatible with multiple parsers (
lxml,html5lib)
3. Understanding Scrapy
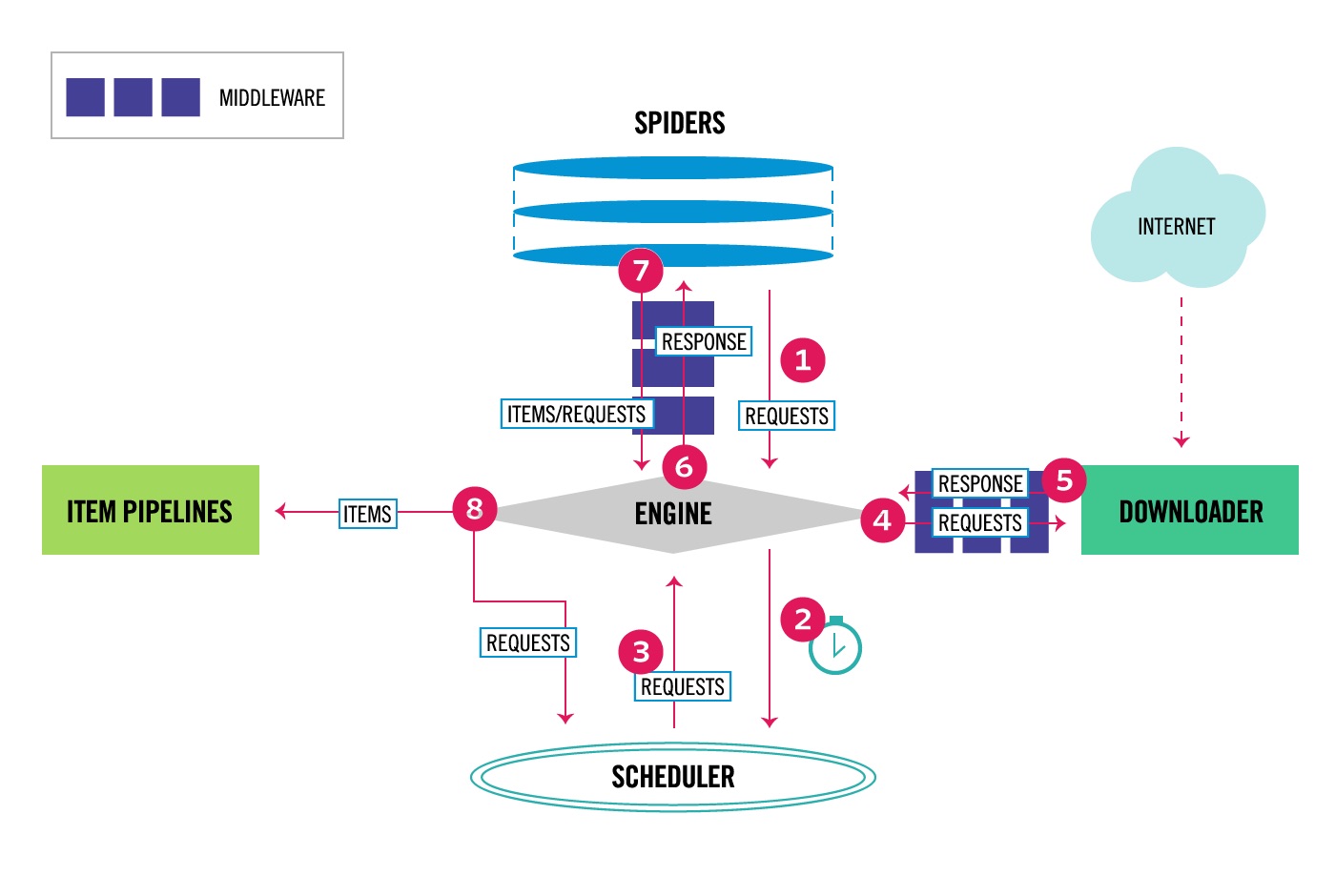
Source: Scrapy documentation.
Scrapy takes a different approach to web scraping by providing a complete framework rather than just a parsing library. Think of it as a Swiss Army knife for web scraping – it includes everything you need to crawl websites, process data, and handle common scraping challenges all in one package. While this makes it more powerful than BS4, it also means there's more to learn before you can get started.
Here's a basic example of how Scrapy works:
# hackernews_spider.py
import scrapy
class HackerNewsSpider(scrapy.Spider):
name = "hackernews"
start_urls = ["https://news.ycombinator.com"]
def parse(self, response):
# Get all stories
for story in response.css("span.titleline"):
# Extract story title
yield {"title": story.css("a::text").get()}
# Go to next page if available
# if next_page := response.css('a.morelink::attr(href)').get():
# yield response.follow(next_page, self.parse)
# To run the spider, we need to use the Scrapy command line
# scrapy runspider hackernews_spider.py -o results.jsonThis code defines a simple Scrapy spider that crawls Hacker News. The spider starts at the homepage, extracts story titles from each page, and could optionally follow pagination links (currently commented out). The spider uses CSS selectors to find and extract content, demonstrating Scrapy's built-in parsing capabilities. The results can be exported to JSON using Scrapy's command line interface.
What sets Scrapy apart is its architecture. Instead of making one request at a time like BS4, Scrapy can handle multiple requests simultaneously, making it much faster for large projects. It also includes built-in features that you'd otherwise need to build yourself.
Scrapy's key components include:
Spider middleware for customizing request/response handling, item pipelines for processing and storing data, and automatic request queuing and scheduling. It provides built-in support for exporting data in formats like JSON, CSV, and XML. The framework also includes robust error handling with retry mechanisms and a command-line interface for project management.
4. Head-to-Head Comparison
Let's break down how BS4 and Scrapy compare in key areas that matter most for web scraping projects.
Performance
When it comes to speed and efficiency, Scrapy has a clear advantage. Its ability to handle multiple requests at once means it can scrape hundreds of pages while BS4 is still working on its first dozen. Think of BS4 as a solo worker, carefully processing one page at a time, while Scrapy is like a team of workers tackling many pages simultaneously. This speed difference becomes especially important for list crawling—extracting data from product grids, job boards, or directories that span dozens of pages.
Memory usage tells a similar story. BS4 is lightweight and uses minimal memory for single pages, making it perfect for small projects. However, Scrapy's smart memory management shines when dealing with large websites, efficiently handling thousands of pages without slowing down your computer.
Ease of Use
BS4 takes the lead in simplicity. You can start scraping with just 4-5 lines of code and basic Python knowledge. Here's a quick comparison:
BS4:
from bs4 import BeautifulSoup
import requests
response = requests.get("https://example.com")
soup = BeautifulSoup(response.text, "html.parser")
titles = soup.find_all("h1")Scrapy:
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['https://example.com']
def parse(self, response):
titles = response.css('h1::text').getall()
yield {'titles': titles}
# Requires additional setup and command-line usage as seen aboveFeatures
Here's a simple breakdown of key features:
| Feature | BeautifulSoup4 | Scrapy |
|---|---|---|
| JavaScript Support | ❌ | ❌ (needs add-ons) |
| Multiple Requests | ❌ (manual) | ✅ (automatic) |
| Data Processing | ❌ (basic) | ✅ (built-in pipelines) |
| Error Handling | ❌ (manual) | ✅ (automatic retries) |
| Proxy Support | ❌ (manual) | ✅ (built-in) |
Use Cases
Choose BS4 when:
- You're new to web scraping
- You need to scrape a few simple pages
- You want to quickly test or prototype
- The website is mostly static HTML
- You're working within a larger project
Choose Scrapy when:
- You need to scrape thousands of pages
- You want built-in data processing
- You need advanced features like proxy rotation
- You're building a production scraper
- Performance is critical
5. Common Challenges and Limitations
Web scraping tools face several hurdles that can make data extraction difficult or unreliable. Understanding these challenges helps you choose the right tool and prepare for potential roadblocks.
Dynamic Content
Modern websites often load content using JavaScript after the initial page load. Neither BS4 nor Scrapy can handle this directly. While you can add tools like Selenium or Playwright to either solution, this makes your scraper more complex and slower. A typical example is an infinite scroll page on social media – the content isn't in the HTML until you scroll down.
Anti-Bot Measures
Websites are getting smarter at detecting and blocking scrapers. Common protection methods include:
- CAPTCHAs and reCAPTCHA challenges
- IP-based rate limiting
- Browser fingerprinting
- Dynamic HTML structure changes
- Hidden honeypot elements
While Scrapy offers some built-in tools like proxy support and request delays, both BS4 and Scrapy users often need to implement additional solutions to handle complex web infrastructure.
Maintenance Burden
Perhaps the biggest challenge is keeping scrapers running over time. Websites frequently change their structure, breaking scrapers that rely on specific HTML patterns. Here's a real-world example:
Before website update:
# Working scraper
soup.find('div', class_='product-price').text # Returns: "$99.99"After website update, same code now returns None because the structure changed:
soup.find('span', class_='price-current').text # Returns: NoneThis constant need for updates creates a significant maintenance overhead, especially when managing multiple scrapers. While Scrapy's more robust architecture helps handle some issues automatically, both tools require regular monitoring and fixes to maintain reliability.
Resource Management
Each tool presents unique resource challenges:
- BS4: High memory usage when parsing large pages
- Scrapy: Complex configuration for optimal performance
- Both: Network bandwidth limitations
- Both: Server response time variations
These limitations often require careful planning and optimization, particularly for large-scale scraping projects where efficiency is crucial.
6. Modern Solutions: Introducing Firecrawl
After exploring the limitations of traditional scraping tools, let's look at how modern AI web scraping solutions like Firecrawl are changing the web scraping landscape. Firecrawl takes a fundamentally different approach by using natural language understanding to identify and extract content, rather than relying on brittle HTML selectors.
AI-Powered Content Extraction

Unlike BS4 and Scrapy which require you to specify exact HTML elements, Firecrawl lets you describe what you want to extract in plain English. This semantic approach means your scrapers keep working even when websites change their structure. Here's a practical example of scraping GitHub's trending repositories:
# Import required libraries
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
from dotenv import load_dotenv
from typing import List
# Load environment variables from .env file
load_dotenv()
# Define Pydantic model for a single GitHub repository
class Repository(BaseModel):
# Each field represents a piece of data we want to extract
name: str = Field(description="The repository name including organization/username")
description: str = Field(description="The repository description")
stars: int = Field(description="Total number of stars")
language: str = Field(description="Primary programming language")
url: str = Field(description="The repository URL")
# Define model for the full response containing list of repositories
class Repositories(BaseModel):
repositories: List[Repository] = Field(description="List of trending repositories")
# Initialize Firecrawl app
app = FirecrawlApp()
# Scrape GitHub trending page using our defined schema
trending_repos = app.scrape_url(
'https://github.com/trending',
params={
# Specify we want to extract structured data
"formats": ["extract"],
"extract": {
# Use our Pydantic model schema for extraction
"schema": Repositories.model_json_schema(),
}
}
)
# Loop through the first 3 repositories and print their details
for idx, repo in enumerate(trending_repos['extract']['repositories']):
print(f"{idx + 1}. {repo['name']}")
print(f"⭐ {repo['stars']} stars")
print(f"💻 {repo['language']}")
print(f"📝 {repo['description']}")
print(f"🔗 {repo['url']}\n")
# Break after showing 3 repositories
if idx == 2:
break1. pathwaycom/pathway
⭐ 11378 stars
💻 Python
📝 Python ETL framework for stream processing, real-time analytics, LLM pipelines, and RAG.
🔗 https://github.com/pathwaycom/pathway
2. EbookFoundation/free-programming-books
⭐ 345107 stars
💻 HTML
📝 📚 Freely available programming books
🔗 https://github.com/EbookFoundation/free-programming-books
3. DrewThomasson/ebook2audiobook
⭐ 3518 stars
💻 Python
📝 Convert ebooks to audiobooks with chapters and metadata using dynamic AI models and voice cloning. Supports 1,107+ languages!
🔗 https://github.com/DrewThomasson/ebook2audiobookFirecrawl addresses the major pain points we discussed earlier:
- JavaScript Rendering: Automatically handles dynamic content without additional tools
- Anti-Bot Measures: Built-in proxy rotation and browser fingerprinting
- Maintenance: AI adapts to site changes without updating selectors
- Rate Limiting: Smart request management with automatic retries
- Multiple Formats: Export data in various formats (JSON, CSV, Markdown)
When to Choose Firecrawl
Firecrawl is particularly valuable when:
- You need reliable, low-maintenance scrapers
- Websites frequently change their structure
- You're dealing with JavaScript-heavy sites
- Anti-bot measures are a concern
- You need clean, structured data for AI/ML
- Time-to-market is critical
While you have to pay for higher usage limits, the reduction in development and maintenance time often makes it more cost-effective than maintaining custom scraping infrastructure with traditional tools.
7. Making the Right Choice
Choosing the right web scraping tool isn't a one-size-fits-all decision. Let's break down a practical framework to help you make the best choice for your specific needs.
Decision Framework
-
Project Scale
- Small (1-10 pages): BeautifulSoup4
- Medium (10-100 pages): BeautifulSoup4 or Scrapy
- Large (100+ pages): Scrapy or Firecrawl
-
Technical Requirements
- Static HTML only: BeautifulSoup4
- Multiple pages & data processing: Scrapy
- Dynamic content & complex sites: Firecrawl
-
Development Resources
- Time available:
- Hours: BeautifulSoup4
- Days: Scrapy
- Minutes: Firecrawl
- Team expertise:
- Beginners: BeautifulSoup4
- Experienced developers: Scrapy
- Production teams: Firecrawl
- Time available:
Cost-Benefit Analysis
| Factor | BeautifulSoup4 | Scrapy | Firecrawl |
|---|---|---|---|
| Initial Cost | Free | Free | Paid |
| Development Time | Low | High | Minimal |
| Maintenance Cost | High | Medium | Low |
| Scalability | Limited | Good | Excellent |
Future-Proofing Your Choice
Consider these factors for long-term success:
-
Maintainability
- Will your team be able to maintain the scraper?
- How often does the target website change?
- What's the cost of scraper downtime?
-
Scalability Requirements
- Do you expect your scraping needs to grow?
- Will you need to add more websites?
- Are there seasonal traffic spikes?
-
Integration Needs
- Does it need to work with existing systems?
- What format do you need the data in?
- Are there specific performance requirements?
Practical Recommendations
Start with BeautifulSoup4 if:
- You're learning web scraping
- You need to scrape simple, static websites
- You have time to handle maintenance
- Budget is your primary constraint
Choose Scrapy when:
- You need to scrape at scale
- You have experienced developers
- You need fine-grained control
- You're building a long-term solution
Consider Firecrawl if:
- Time to market is critical
- You need reliable production scrapers
- Maintenance costs are a concern
- You're dealing with complex websites
- You need AI-ready data formats
8. Conclusion
The web scraping landscape offers distinct tools for different needs. BeautifulSoup4 excels in simplicity, making it ideal for beginners and quick projects. Scrapy provides powerful features for large-scale operations but requires more expertise. Modern solutions like Firecrawl bridge the gap with AI-powered capabilities that address traditional scraping challenges, though at a cost.
Key Takeaways
- BeautifulSoup4: Best for learning and simple, static websites
- Scrapy: Ideal for large-scale projects needing fine control
- Firecrawl: Perfect when reliability and low maintenance are priorities
- Consider long-term costs and scalability in your decision
Choose based on your project's scale, team expertise, and long-term needs. As websites grow more complex and anti-bot measures evolve, picking the right tool becomes crucial for sustainable web scraping success.
Useful links
- BeautifulSoup4 Documentation
- Scrapy Official Website
- Scrapy Documentation
- Web Scraping Best Practices
- Firecrawl Documentation
- Getting Started With Firecrawl
Frequently Asked Questions
1. What's the main difference between BeautifulSoup4 and Scrapy?
BeautifulSoup4 is a parsing library that extracts data from HTML/XML one page at a time, ideal for simple projects. Scrapy is a complete web scraping framework with built-in crawling, concurrent requests, and data pipelines, designed for large-scale operations.
2. Can BeautifulSoup4 or Scrapy handle JavaScript-rendered content?
No, neither tool can natively process JavaScript-rendered content. You'll need to integrate additional tools like Selenium or Playwright to handle dynamic content, which adds complexity and slows down scraping. Firecrawl handles JavaScript automatically without extra configuration.
3. Which tool is better for beginners learning web scraping?
BeautifulSoup4 is significantly better for beginners. You can start scraping with just 4-5 lines of code and basic Python knowledge. Scrapy requires understanding of its framework architecture, class structure, and command-line interface before extracting your first data.
4. How does Scrapy handle multiple pages faster than BeautifulSoup4?
Scrapy processes multiple requests concurrently through its asynchronous architecture, like a team working simultaneously. BeautifulSoup4 handles one request at a time sequentially. This makes Scrapy dramatically faster when scraping hundreds or thousands of pages.
5. What are the biggest maintenance challenges with traditional scraping tools?
Websites frequently change their HTML structure, breaking scrapers that rely on specific selectors. Both BS4 and Scrapy require constant monitoring and updates to maintain reliability. This creates significant overhead, especially when managing scrapers for multiple websites.
6. When should I use Firecrawl instead of BS4 or Scrapy?
Choose Firecrawl when dealing with JavaScript-heavy sites, facing anti-bot measures, needing low-maintenance scrapers, or when time-to-market is critical. Its AI-powered extraction adapts to website changes automatically, eliminating the constant maintenance burden of traditional tools.
7. Can I use BeautifulSoup4 and Scrapy together in one project?
Yes, you can use BeautifulSoup4 within Scrapy for parsing responses. Scrapy handles crawling and request management while BS4 parses HTML. However, Scrapy's built-in CSS and XPath selectors are usually sufficient, making this combination unnecessary for most projects.
8. How do I handle anti-bot measures with BeautifulSoup4 or Scrapy?
Both require manual implementation of solutions like proxy rotation, user-agent spoofing, and request delays. Scrapy offers better built-in support with middleware for proxies and delays. However, neither handles CAPTCHAs or advanced fingerprinting automatically without third-party services.

data from the web