Scraping Company Data and Funding Information in Bulk With Firecrawl and Claude

Introduction
In today's data-driven business world, having access to accurate information about companies and their funding history is incredibly valuable. There are several online databases that track startups, investments, and company growth, containing details about millions of businesses, their funding rounds, and investors. While many of these platforms offer APIs, they can be expensive and out of reach for many users. This tutorial will show you how to build a web scraper that can gather company and funding data from public sources using Python, Firecrawl, and Claude.
This guide is designed for developers who want to collect company data efficiently and ethically. By the end of this tutorial, you'll have a working tool that can extract company details, funding rounds, and investor information from company profiles across the web.
Here is the preview of the app:
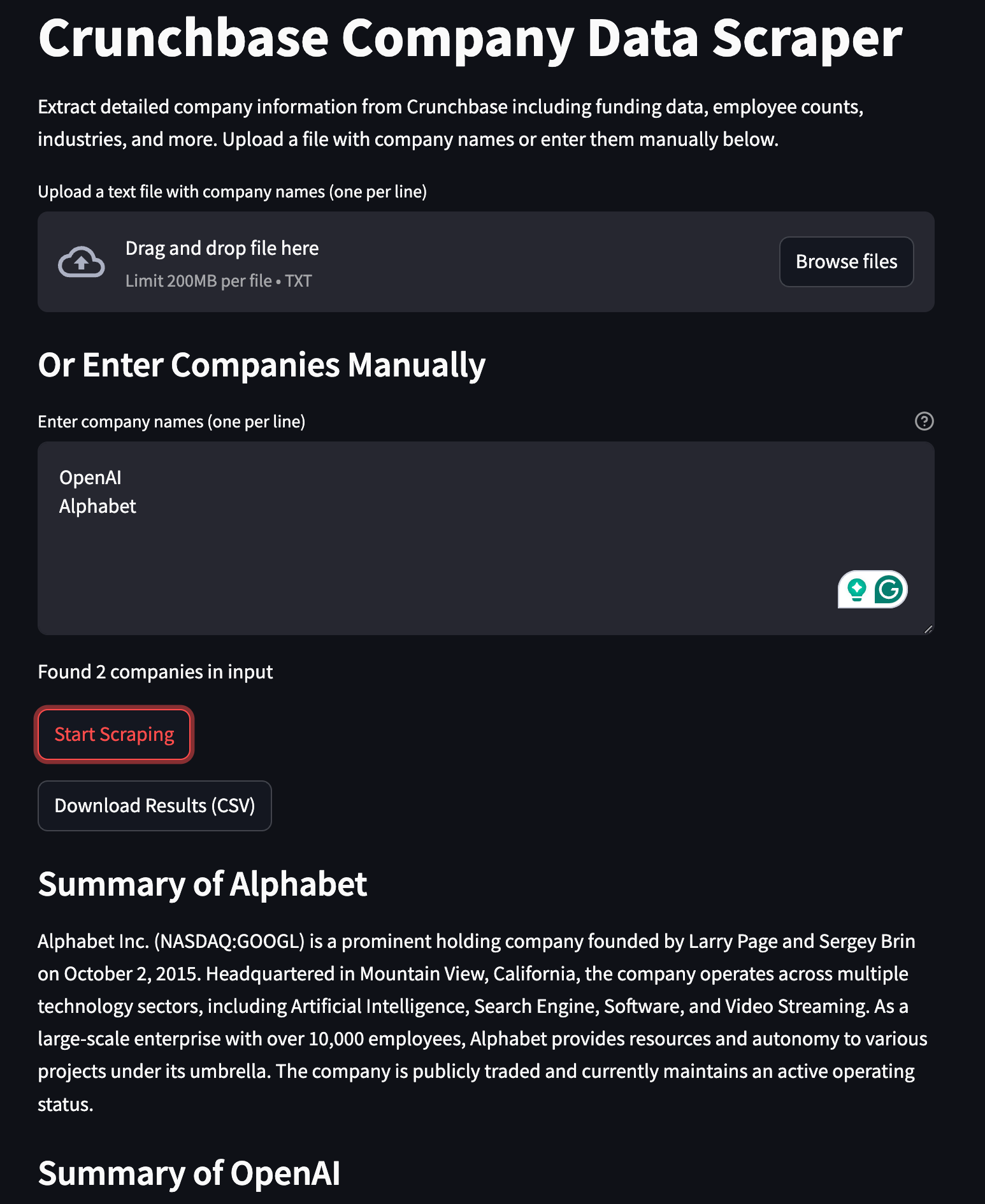
The application provides two input methods for users - they can either upload a file containing company names or enter them directly as text. Behind the scenes, Firecrawl automatically scrapes relevant company information from public databases like Crunchbase. This scraped data is then processed by Claude, an AI assistant that generates concise company summaries. The results are displayed in a clean Streamlit interface, complete with a download option that exports all findings to a CSV file for further analysis.
Table of Contents
- Introduction
- Setting up the Development Environment
- Prerequisite: Scraping with Firecrawl
- Building the Funding Data Scraper
- Step 1: Adding brief app information
- Step 2: Adding components for company name input
- Step 3: Building a scraping class
- Step 4: Adding a scraping button
- Step 5: Creating a download button
- Step 6: Generating summaries
- Step 7: Deployment
- Conclusion
Time to Complete: ~60 minutes Prerequisites:
- Python 3.10+
- Basic Python knowledge
- API keys for Firecrawl and Claude
Important Note: This tutorial demonstrates web scraping for educational purposes. Always review and comply with websites' terms of service and implement appropriate rate limiting in production environments.
Setting up the Development Environment
Let's start by setting up our development environment and installing the necessary dependencies.
- Create a working directory
First, create a working directory:
mkdir company-data-scraper
cd company-data-scraper- Install dependencies
We'll use Poetry for dependency management. If you haven't installed Poetry yet:
curl -sSL https://install.python-poetry.org | python3 -Then, initialize it inside the current working directory:
poetry initType "^3.10" when asked for the Python version but, don't specify the dependencies interactively.
Next, install the project dependencies with the add command:
poetry add streamlit firecrawl-py pandas pydantic openpyxl python-dotenv anthropic- Build the project structure
mkdir data src
touch .gitignore README.md .env src/{app.py,models.py,scraper.py}The created files serve the following purposes:
data/- Directory to store input files and scraped resultssrc/- Source code directory containing the main application files.gitignore- Specifies which files Git should ignoreREADME.md- Project documentation and setup instructions.env- Stores sensitive configuration like API keyssrc/app.py- Main Streamlit application and UI codesrc/models.py- Data models and validation logicsrc/scraper.py- Web scraping and data collection functionality
- Configure environment variables
This project requires two accounts of third-party services:
- Firecrawl for AI-powered web scraping
- Anthropic (Claude) for summarizing scraped data
Click on the hyperlinks above to create your accounts and copy/generate your API keys. Then, Inside the .env file in the root directory, add your API keys:
FIRECRAWL_API_KEY=your_api_key_here
ANTHROPIC_API_KEY=your_api_key_hereThe .env file is used to store sensitive configuration like API keys securely.The python-dotenv package will automatically load these environment variables when the app starts. It should never be committed to version control so add the following line to your .gitignore file:
.env- Start the app UI
Run the Streamlit app (which is blank just now) to ensure everything is working:
poetry run streamlit run src/app.pyYou should see the Streamlit development server start up and your default browser open to the app's interface. Keep this tab open to see the changes we make to the app in the next steps.
Now that we have our development environment set up, let's cover how Firecrawl works, which is a prerequisite to building our app.
Prerequisite: Scraping with Firecrawl
The biggest challenge with any application that scrapes websites is maintenance. Since websites regularly update their layout and underlying HTML/CSS code, traditional scrapers break easily, making the entire app useless. Firecrawl solves this exact problem by allowing you to scrape websites using natural language.
Instead of writing complex CSS selectors and XPath expressions that need constant maintenance, you can simply describe what data you want to extract in plain English. Firecrawl's AI will figure out how to get that data from the page, even if the website's structure changes. This makes our scraper much more reliable and easier to maintain over time.
Here is a simple Firecrawl workflow we will later use in the app to scrape company information:
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
from dotenv import load_dotenv
load_dotenv()TrueWe import FirecrawlApp to interact with the Firecrawl API for web scraping. BaseModel and Field from pydantic help us define structured data models with validation. The load_dotenv function loads environment variables from our .env file to securely access API keys.
# Define the data structure we want to extract
class CompanyData(BaseModel):
name: str = Field(description="Company name")
funding_total: str = Field(description="Total funding amount")
employee_count: str = Field(description="Number of employees")
industry: str = Field(description="Primary industry or sector")
founded_year: str = Field(
description="Year the company was founded"
) # Initialize Firecrawl
Next, we define a Pydantic data model specifying the fields we want to extract from a website. Firecrawl will follow this schema to the letter - detecting the relevant HTML/CSS selectors containing this information and returning them in a simple JSON object. Here, the Field descriptions written in plain English are important as they guide the underlying Firecrawl AI to capture the required fields.
app = FirecrawlApp()
# Scrape company data from Crunchbase
data = app.extract(
urls=["https://www.crunchbase.com/organization/openai"],
params={
"schema": CompanyData.model_json_schema(), # Use our schema for extraction
"prompt": "Extract key company information from the page",
},
)We then initialize a FirecrawlApp instance and call its extract method, passing in the URL for OpenAI's Crunchbase page. The params dictionary configures the scraping behavior - we provide our CompanyData schema to guide the structured data extraction. We also include a prompt to help direct the extraction process.
The scraped data is returned in a format matching our schema, which we can then parse into a CompanyData object for easy access to the extracted fields, as shown in the following code block.
# Access the extracted data
company = CompanyData(**data["data"])
print(f"Company: {company.name}")
print(f"Funding: {company.funding_total}")
print(f"Employees: {company.employee_count}")
print(f"Industry: {company.industry}")
print(f"Founded: {company.founded_year}")Company: OpenAI
Funding: null
Employees: 251-500
Industry: Artificial Intelligence (AI)
Founded: 2015In a later step, we will integrate this process into our app but will use the batch_scrape_urls method instead of extract to enable concurrent scraping.
Building the Funding Data Scraper Step-by-Step
We will take a top-down approach to building the app: starting with the high-level UI components and user flows, then implementing the underlying functionality piece by piece. This approach will help us validate the app's usability early and ensure we're building exactly what users need.
Step 1: Adding brief app information
We turn our focus to the src/app.py file and make the following imports:
import streamlit as st
import pandas as pd
import anthropic
from typing import List
from dotenv import load_dotenv
# from scraper import CrunchbaseScraper
load_dotenv()The imports above serve the following purposes:
streamlit: Provides the web interface components and app frameworkpandas: Used for data manipulation and CSV file handlinganthropic: Client library for accessing Claude AI capabilitiestyping.List: Type hint for lists to improve code readabilitydotenv: Loads environment variables from.envfile for configuration
Currently, the CrunchbaseScraper class is commented out since we are yet to write it.
Next, we create a main function that holds the core UI components:
def main():
st.title("Crunchbase Company Data Scraper")
st.write(
"""
Extract detailed company information from Crunchbase including funding data,
employee counts, industries, and more. Upload a file with company names or
enter them manually below.
"""
)Right now, the function gives brief info about the app's purpose. To run the app, add the following main block to the end of src/app.py:
if __name__ == "__main__":
main()You should see the change in the Streamlit development server.
Step 2: Adding components for company name input
In this step, we add a new function to src/app.py:
def load_companies(file) -> List[str]:
"""Load company names from uploaded file"""
companies = []
for line in file:
company = line.decode("utf-8").strip()
if company: # Skip empty lines
companies.append(company)
return companiesThe load_companies function takes a file object as input and parses it line by line, extracting company names. It decodes each line from bytes to UTF-8 text, strips whitespace, and skips any empty lines. The function returns a list of company names that can be used for scraping Crunchbase data.
Now, make the following changes to the main function:
def main():
st.title("Crunchbase Company Data Scraper")
st.write(
"""
Extract detailed company information from Crunchbase including funding data,
employee counts, industries, and more. Upload a file with company names or
enter them manually below.
"""
)
# File upload option
uploaded_file = st.file_uploader(
"Upload a text file with company names (one per line)", type=["txt"]
)
# Manual input option
st.write("### Or Enter Companies Manually")
manual_input = st.text_area(
"Enter company names (one per line)",
height=150,
help="Enter each company name on a new line",
)In this version, we've added two main ways for users to input company names: file upload and manual text entry. The file upload component accepts .txt files and for manual entry, users can type or paste company names directly into a text area, with each name on a new line. This provides flexibility for users whether they have a prepared list or want to enter names ad-hoc.
Furthermore, add these two blocks of code after the input components:
def main():
...
companies = []
if uploaded_file:
companies = load_companies(uploaded_file)
st.write(f"Loaded {len(companies)} companies from file")
elif manual_input:
companies = [line.strip() for line in manual_input.split("\n") if line.strip()]
st.write(f"Found {len(companies)} companies in input")This code block processes the user input to create a list of company names. When a file is uploaded, it uses the load_companies() function to read and parse the file contents. For manual text input, it splits the input text by newlines and strips whitespace to extract company names. In both cases, it displays a message showing how many companies were found. The companies list will be used later for scraping data from funding data sources.
Step 3: Building a scraping class with Firecrawl
Let's take a look at the snapshot of the final UI once again:
In this step, we implement the backend process that happens when a user clicks on "Start scraping" button. To do so, we use Firecrawl like we outlined in the prerequisites section. First, go to src/models.py script to write the data model we are going to use to scrape company and funding information:
from pydantic import BaseModel
from typing import List, Optional
class CompanyData(BaseModel):
name: str
about: Optional[str]
employee_count: Optional[str]
financing_type: Optional[str]
industries: List[str] = []
headquarters: List[str] = []
founders: List[str] = []
founded_date: Optional[str]
operating_status: Optional[str]
legal_name: Optional[str]
stock_symbol: Optional[str]
acquisitions: List[str] = []
investments: List[str] = []
exits: List[str] = []
total_funding: Optional[str]
contacts: List[str] = []This data model is more detailed and tries to extract as much information as possible from given sources. Now, switch to src/scraper.py where we implement a class called CrunchbaseScraper:
from firecrawl import FirecrawlApp
from models import CompanyData
from typing import List, Dict
class CrunchbaseScraper:
def __init__(self):
self.app = FirecrawlApp()
def scrape_companies(self, urls: List[str]) -> List[Dict]:
"""Scrape multiple Crunchbase company profiles"""
schema = CompanyData.model_json_schema()
try:
data = self.app.batch_scrape_urls(
urls,
params={
"formats": ["extract"],
"extract": {
"prompt": """Extract information from given pages based on the schema provided.""",
"schema": schema,
},
},
)
return [res["extract"] for res in data["data"]]
except Exception as e:
print(f"Error while scraping companies: {str(e)}")
return []Let's break down how the class works.
When the class is initialized, it creates an instance of FirecrawlApp. The main method scrape_companies takes a list of URLs and returns a list of dictionaries containing the scraped data. It works by:
- Getting the JSON schema from our
CompanyDatamodel to define the structure - Using
batch_scrape_urlsto process multiple URLs at once - Configuring the scraper to use the "extract" format with our schema
- Providing a prompt that instructs the scraper how to extract the data
- Handling any errors that occur during scraping
Error handling ensures the script continues running even if individual URLs fail, returning an empty list in case of errors rather than crashing.
Now, the only thing left to do to finalize the scraping feature is to add the "Start Scraping" button to the UI.
Step 4: Adding a button to start scraping
In this step, return to src/app.py and add the following code block to the very end of the main() function:
def main():
...
if companies and st.button("Start Scraping"):
scraper = CrunchbaseScraper()
with st.spinner("Scraping company data from Crunchbase..."):
try:
# Convert company names to Crunchbase URLs
urls = [
f"https://www.crunchbase.com/organization/{name.lower().replace(' ', '-')}"
for name in companies
]
results = scraper.scrape_companies(urls)
except Exception as e:
st.error(f"An error occurred: {str(e)}")This code block builds on the previous functionality by adding the core scraping logic. When the "Start Scraping" button is clicked (and companies have been provided), it:
- Creates a new instance of our
CrunchbaseScraperclass - Shows a loading spinner to indicate scraping is in progress
- Converts the company names into proper Crunchbase URLs by:
- Converting to lowercase
- Replacing spaces with hyphens
- Adding the base Crunchbase URL prefix
- Calls the
scrape_companiesmethod we created earlier to fetch the data
The try-except block ensures any scraping errors are handled gracefully rather than crashing the application. This is important since web scraping can be unpredictable due to network issues, rate limiting, and so on.
To finish this step, uncomment the single import at the top of src/app.py so that they look like this:
import streamlit as st
import pandas as pd
import anthropic
from typing import List
from scraper import CrunchbaseScraper
from dotenv import load_dotenv
load_dotenv()Step 5: Creating a download button for the scraped results
Now, we must create a button to download the scraped results as a CSV file. To do so, add the following code block after the scraping part:
def main():
...
if companies and st.button("Start Scraping"):
scraper = CrunchbaseScraper()
with st.spinner("Scraping company data from Crunchbase..."):
try:
...
results = scraper.scrape_companies(urls)
# THIS PART IS NEW
df = pd.DataFrame(results)
csv = df.to_csv(index=False)
# Create download button
st.download_button(
"Download Results (CSV)",
csv,
"crunchbase_data.csv",
"text/csv",
key="download-csv",
)
except Exception as e:
st.error(f"An error occurred: {str(e)}")In the new lines of code, we convert the results to a Pandas dataframe and use its to_csv() function to save the dataframe as a CSV file. The method returns a filename, which we pass to the st.download_button method along with other details.
Step 6: Generating a summary of scraped results
After scraping the raw company data, we can use Claude to generate concise summaries that highlight key insights. Let's add this functionality to our app. First, create a new function in src/app.py to handle the summarization:
def generate_company_summary(company_data: dict) -> str:
"""Generate a summary of the company data"""
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1000,
system="You are a company & funding data expert. Summarize the given company data by the user in a few sentences.",
messages=[
{"role": "user", "content": [{"type": "text", "text": str(company_data)}]}
],
)
return message.content[0].textNow, update the scraping section in the main() function to include the summary generation after the download button:
def main():
...
if companies and st.button("Start Scraping"):
scraper = CrunchbaseScraper()
with st.spinner("Scraping company data from Crunchbase..."):
try:
...
# Give summary of each company
for company in results:
summary = generate_company_summary(company)
st.write(f"### Summary of {company['name']}")
st.write(summary)
except Exception as e:
st.error(f"An error occurred: {str(e)}")
This implementation:
- Creates a new
generate_company_summary()function that:
- Formats the scraped company data into readable text
- Uses Claude to analyze the data and generate insights
- Returns a structured summary highlighting key patterns.
- Updates the main scraping workflow to:
- Generate the summary after scraping is complete
- Display the insights for each company after the download button
The summary can provide context about the scraped data, helping users get the gist of the scraped data.
Step 7: Deploying the app to Streamlit Cloud
Now that our app is working locally, let's deploy it to Streamlit Cloud so others can use it. First, we need to prepare our project for deployment.
- Create a requirements.txt
Since Streamlit Cloud doesn't support Poetry directly, we need to convert our dependencies to a requirements.txt file. Run this command in your terminal:
poetry export -f requirements.txt --output requirements.txt --without-hashes- Create a GitHub repository
Initialize a Git repository and push your code to GitHub:
git init
git add .
git commit -m "Initial commit"
git branch -M main
git remote add origin https://github.com/yourusername/company-data-scraper.git
git push -u origin main- Add secrets to Streamlit Cloud
Visit share.streamlit.io and connect your GitHub account. Then:
- Click "New app"
- Select your repository and branch
- Set the main file path as src/app.py
- Click "Advanced settings" and add your environment variables:
FIRECRAWL_API_KEYANTHROPIC_API_KEY
- Update imports for deployment
Sometimes local imports need adjustment for Streamlit Cloud. Ensure your imports in src/app.py use relative paths:
from .models import CompanyData
from .scraper import CrunchbaseScraper- Add a .streamlit/config.toml file
Create a .streamlit directory and add a config.toml file for custom theme settings:
[theme]
primaryColor = "#FF4B4B"
backgroundColor = "#FFFFFF"
secondaryBackgroundColor = "#F0F2F6"
textColor = "#262730"
font = "sans serif"
[server]
maxUploadSize = 5- Create a README.md file
Add a README.md file to help users understand your app:
# Crunchbase Company Data Scraper
A Streamlit app that scrapes company information and funding data from Crunchbase.
## Features
- Bulk scraping of company profiles
- AI-powered data summarization
- CSV export functionality
- Clean, user-friendly interface
## Setup
1. Clone the repository
2. Install dependencies: `pip install -r requirements.txt`
3. Set up environment variables in `.env`:
- `FIRECRAWL_API_KEY`
- `ANTHROPIC_API_KEY`
4. Run the app: `streamlit run src/app.py`
## Usage
1. Enter company names (one per line) or upload a text file
2. Click "Start Scraping"
3. View AI-generated insights
4. Download results as CSV
## License
MIT- Deploy the app
After pushing all changes to GitHub, go back to Streamlit Cloud and:
-
Click "Deploy"
-
Wait for the build process to complete
-
Your app will be live at
https://share.streamlit.io/yourusername/company-data-scraper/main -
Monitor and maintain
After deployment:
- Check the app logs in Streamlit Cloud for any issues
- Monitor API usage and rate limits
- Update dependencies periodically
- Test the app regularly with different inputs
The deployed app will automatically update whenever you push changes to your GitHub repository. Streamlit Cloud provides free hosting for public repositories, making it an excellent choice for sharing your scraper with others.
Conclusion
In this tutorial, we've built a powerful web application that combines the capabilities of Firecrawl and Claude to extract and analyze company data at scale. By leveraging Firecrawl's AI-powered scraping and Claude's natural language processing, we've created a tool that not only gathers raw data but also provides meaningful insights about companies and their funding landscapes. This kind of bulk company scraping is a core technique in B2B data enrichment pipelines — if you want to understand how it fits into a broader enrichment strategy, our complete guide covers the full picture. The Streamlit interface makes the tool accessible to users of all technical levels, while features like bulk processing and CSV export enable efficient data collection workflows.
Limitations and Considerations
- Rate limiting: Implement appropriate delays between requests
- Data accuracy: Always verify scraped data against official sources
- API costs: Monitor usage to stay within budget
- Maintenance: Website structure changes may require updates
Next Steps
Consider these enhancements for your implementation:
- Add data validation and cleaning
- Implement request caching
- Add data visualizations
- Include historical data tracking
- Implement error retry logic
