
Creating Custom Instruction Datasets For Supervised LLM Fine-tuning
What Are Instruction Datasets?
Instruction datasets are collections of input-output pairs used to teach AI models how to respond to specific types of requests. Think of them like flashcards used in learning a new language - one side has a question or task (the instruction), and the other side has the correct response (the desired output). For example, an instruction might be "Explain what photosynthesis is to a 10-year-old," and the paired output would be a simple, child-friendly explanation.
[
{
"instruction": "Explain what photosynthesis is to a 10-year-old",
"answer": "..."
}
// ... the rest of the dataset
]These datasets are crucial for a technique called supervised fine-tuning, which helps LLMs become better at specific tasks. Just like how a general medical doctor might get additional training to become a specialist, a general-purpose AI model can be fine-tuned using instruction datasets to become more skilled at particular tasks like writing code, answering medical questions, or providing customer service responses.
In this article, you'll learn when and why you might need to create your own instruction dataset, the step-by-step process of building one, and see a real-world example of creating a dataset for code documentation. By the end, you'll have the knowledge to create instruction datasets that can help fine-tune AI models for your specific needs.
Table of Contents
- What Are Instruction Datasets?
- When to Create a Custom Instruction Dataset?
- What Formats Do Instruction Datasets Use?
- Real-world Scenario: a Custom Instruction Dataset For Code Documentation
- General Process For Creating Instruction Datasets
- Conclusion
When to Create a Custom Instruction Dataset?
Creating a custom instruction dataset is a significant undertaking that requires careful consideration. While there are many high-quality public datasets available, several compelling reasons might lead you to develop your own. Let's explore the key scenarios where building a custom instruction dataset becomes necessary or advantageous.
1. Domain specificity
Specialized fields like medical diagnostics, legal analysis, and technical documentation often require custom instruction datasets that go beyond general-purpose training data. While models like Claude and GPT are trained on broad knowledge, they lack the depth needed for domain-specific tasks that require expert-level understanding and specialized vocabulary. Public datasets from Anthropic, OpenAI and others primarily focus on common use cases and general knowledge, making them insufficient for specialized applications.
2. Data privacy & security
Organizations dealing with sensitive information face strict regulatory requirements and confidentiality concerns that necessitate creating private instruction datasets. Healthcare providers must ensure HIPAA compliance while working with patient data, while financial institutions need to protect proprietary trading strategies and client information. Companies like Goldman Sachs and UnitedHealth Group have pioneered approaches to create secure instruction datasets that maintain data privacy while implementing strict access controls.
3. Performance optimization
Task-specific performance requirements often drive the need for custom instruction datasets optimized for particular use cases. Databricks demonstrated this by creating specialized datasets for data science and SQL tasks, achieving significantly better results than models trained on general-purpose data. The success of models like CodeLlama shows how carefully curated instruction datasets can dramatically improve performance in specific domains.
4. Language & cultural adaptation
The English-centric nature of many public datasets creates barriers for organizations serving diverse global audiences. Companies operating in different regions need instruction data that reflects local languages, dialects, cultural references, and communication styles. Major technology companies like Baidu and Yandex have invested in creating region-specific instruction datasets that capture the nuances of their target markets.
5. Quality control:
The varying quality of public datasets, which often contain errors, inconsistencies, and outdated information, drives many organizations to create curated instruction sets. Popular resources like Stack Overflow, while valuable, can propagate incorrect solutions and obsolete practices if used directly for training. Leading technology organizations like GitHub have addressed this by developing rigorous quality control processes for their instruction datasets.
6. Scale requirements
While smaller public datasets like Stanford's Alpaca provide good starting points, many applications require instruction datasets of much greater scale and diversity. The limited size of available datasets can constrain model performance and generalization ability. Industry leaders like Anthropic and DeepMind have demonstrated the importance of scale, using millions of carefully crafted instructions in their training processes.
These examples show why many companies are putting more resources into creating their own instruction datasets. They see it as an essential tool for building AI systems that work well for their particular goals and requirements.
What Formats Do Instruction Datasets Use?
Instruction datasets typically follow standardized formats to ensure compatibility with training pipelines and model architectures. The most common format is JSON, where each example is a dictionary containing fields like "instruction" and "response". This format was popularized by Stanford's Alpaca dataset and has been adopted by many others. Some datasets include additional fields like "context" or "category" to provide more structure.
{
"instruction": "Write a function that calculates the factorial of a number",
"context": "Python programming, basic algorithms",
"response": "def factorial(n):\n if n == 0:\n return 1\n return n * factorial(n-1)",
"category": "programming"
}JSONL (JSON Lines) format is preferred for large-scale datasets due to its streaming-friendly nature. Each line contains a complete instruction-response pair, making it efficient for processing massive datasets. This format is used by OpenAI's GPT training data and Anthropic's Constitutional AI datasets. HuggingFace's Datasets library provides native support for JSONL, making it a popular choice for dataset distribution.
Some datasets use more structured formats for specific applications. For example, Microsoft's CodeParrot dataset uses a YAML-based format that preserves code indentation and includes metadata like programming language and documentation standards. Similarly, Google's FLAN collection uses a custom protobuf format that efficiently handles multiple languages and includes provenance information for each example.
Quality control metadata is often incorporated into the format. The Dolly dataset includes fields for validation status, source attribution, and version tracking. Anthropic's dataset format includes fields for safety classifications and bias assessments. These additional fields help in filtering and selecting examples during training:
{
"instruction": "Explain how to invest in stocks",
"response": "...",
"metadata": {
"safety_rating": "approved",
"bias_check": "passed",
"source": "financial_experts",
"validation_status": "peer_reviewed",
"last_updated": "2024-01-15"
}
}For multilingual datasets, formats must handle different character encodings and writing systems. Meta's NLLB dataset uses Unicode normalization and includes language codes and script information for each example. The format also preserves bidirectional text formatting for languages like Arabic and Hebrew:
{
"instruction": {
"text": "Translate this sentence to French",
"lang": "en",
"script": "Latn"
},
"response": {
"text": "Traduisez cette phrase en français",
"lang": "fr",
"script": "Latn"
}
}Version control and dataset evolution are managed through format extensions. Many organizations use dataset formats that track changes over time, similar to git for code. This includes fields for version numbers, change history, and deprecation notices, helping maintain dataset quality as requirements evolve.
Standardized dataset formats with rich metadata and version control capabilities are essential for building high-quality instruction datasets that can evolve over time.
Real-world Scenario: a Custom Instruction Dataset For Code Documentation
Let's explore a practical example of creating a custom instruction dataset for code documentation. This is particularly relevant given how the explosion of LLMs has led to rapid development of new open-source tools and frameworks. Interestingly, even advanced language models like Claude or OpenAI o3 struggle to provide accurate information about these tools, since their training data predates much of the current documentation.
Consider Firecrawl, an API scraping engine that converts webpages into LLM-ready data. When asked about Firecrawl, today's LLMs often provide inaccurate or fabricated information. To address this gap, we'll create a custom instruction dataset to fine-tune a language model for generating technically accurate code examples for Firecrawl and answering questions about it.
Project overview
This project was implemented in four scripts:
-
scrape_raw_data.py: Uses Firecrawl to scrape documentation and blog posts from firecrawl.dev, creating a raw dataset of markdown files.- Scrapes both
docs.firecrawl.devandfirecrawl.dev/blog - Extracts page content, titles, and URLs
- Saves files with frontmatter metadata
- Handles rate limiting and retries
- Scrapes both
-
process_dataset.py: Processes the raw markdown files into clean, chunked training data.- Cleans markdown formatting while preserving code blocks
- Splits content into meaningful chunks using header-based splitting
- Filters chunks based on relevance and information density
- Adds metadata and unique IDs to each chunk
- Outputs a structured JSON dataset
-
generate.py: Creates instruction-answer pairs usinggpt-4o-mini.- Uses a carefully engineered system prompt to generate diverse examples
- Handles rate limiting and parallel processing
- Preserves code blocks and formatting in responses
- Generates multiple instruction types:
- Code examples
- Configuration explanations
- Best practices
- Common use cases
- Troubleshooting scenarios
-
upload_to_hf.py: Prepares and uploads the dataset to HuggingFace Hub.- Converts JSON to HuggingFace Dataset format
- Splits data into training and validation sets
- Handles authentication and repository creation
- Uploads with proper versioning and metadata
The end result is a decent instruction dataset specifically focused on Firecrawl's features and capabilities, ready for fine-tuning language models.
If you want to explore the code straight away, we've pushed all scripts and additional files to our examples repository. You will also find the setup instructions and a list of environment variables you have to configure to run the project locally.
If you want a breakdown of what is happening inside each script, continue reading!
Curating a raw dataset from sources
The first step in creating a fine-tuned model is gathering high-quality training data. The approach to data collection varies significantly depending on whether you're building a task-specific or domain-specific model.
For task-specific models (like code generation or text summarization):
- Data typically comes from existing public datasets or carefully created examples
- Quality matters more than quantity - a few thousand well-crafted examples often outperform millions of noisy ones
- Dataset size usually ranges from 1,000 to 50,000 examples, depending on task complexity
- Examples: GitHub code pairs for code generation, news article summaries for summarization
For domain-specific models (like medical or legal assistants):
- Data collection requires collaboration with subject matter experts
- Sources include technical documentation, research papers, and expert-validated content
- Dataset size typically needs to be larger, often 50,000 to 500,000 examples
- Quality control through expert review is essential
- Examples: Medical papers for healthcare models, legal documents for legal assistants
In our Firecrawl fine-tuning example, we're creating a domain-specific dataset focused on API documentation. We chose to scrape from:
- Official documentation (docs.firecrawl.dev)
- Technical blog posts (firecrawl.dev/blog)
These sources were selected because they:
- Contain accurate, up-to-date information about the API
- Include real-world usage examples and best practices
- Cover common issues and their solutions
- Represent different writing styles and technical depths
- Are publicly accessible and maintained by the core team
The goal is to create a dataset that enables our fine-tuned model to accurately answer questions about Firecrawl's API, provide relevant code examples, and troubleshoot common issues.
At this point, we refer to src/scrape_raw_data.py script which handles scraping these two sources. The script uses Firecrawl itself to scrape Firecrawl blog and documentation. Let's break it down.
First, let's look at the imports and configuration:
import logging
import os
from pathlib import Path
from typing import List
from dotenv import load_dotenv
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
logger = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
BLOG_URL = "https://www.firecrawl.dev/blog"
DOCS_URL = "https://docs.firecrawl.dev"This setup establishes logging (crucial for monitoring long-running scraping jobs) and defines our target URLs. When adapting this for your own use:
- Replace the URLs with your documentation sources
- Consider adding more logging handlers (e.g., file output)
- Use environment variables for sensitive URLs
- Add as many URLs as you need to scrape
Next, we define our data model:
class Page(BaseModel):
title: str = Field(description="Page title")
content: str = Field(description="Main content of the page")
url: str = Field(description="Page URL")Using Pydantic ensures our scraped data is properly structured and validated.
The core scraping logic is encapsulated in the Scraper class:
class Scraper:
def __init__(self, base_url: str = None):
self.app = FirecrawlApp()
self.base_url = base_url
def get_sublinks(self, base_url: str) -> list[str]:
"""Get all sublinks from a given base URL."""
initial_crawl = self.app.crawl_url(
base_url,
params={
"scrapeOptions": {"formats": ["links"]},
},
)
all_links = []
for item in initial_crawl["data"]:
all_links.extend(item["links"])
filtered_links = set(
[link.split("#")[0] for link in all_links if link.startswith(base_url)]
)
return list(filtered_links)The get_sublinks method handles link discovery using Firecrawl's crawl_url method. As you can tell from the name, this method crawls every single subpage of a given URL and returns all sub-links. For example, if the base URL is docs.firecrawl.dev, a found sub-link may look like docs.firecrawl.dev/quickstart.
Once the crawling finishes, the method collects all links into a list. The links are filtered to remove duplicates using a set and to only include links that start with the base URL. Fragment identifiers (the part after #) are also stripped from the URLs to avoid duplicating pages that only differ by their anchor. The filtered list of unique URLs is then returned for further processing.
Key points for adaptation:
- Adjust link filtering based on your site's structure
- Add exclusion patterns for irrelevant sections
- Consider implementing depth limits for large sites
- Read our separate guide on crawling websites with Firecrawl
Next, we have the scrape_sublinks method:
def scrape_sublinks(self, base_url: str, limit: int = None) -> List[Page]:
"""Scrape content from discovered links."""
filtered_links = self.get_sublinks(base_url)
if limit:
filtered_links = filtered_links[:limit]
crawl_results = self.app.batch_scrape_urls(filtered_links)
pages = []
for result in crawl_results["data"]:
if result.get("markdown"):
pages.append(
Page(
title=result.get("metadata", {}).get("title", "Untitled"),
content=result["markdown"],
url=result.get("metadata", {}).get("url", ""),
)
)
return pagesThis method scrapes the pages returned by get_sublinks. It first gets the filtered list of links and optionally limits the number of pages to scrape. Then it uses Firecrawl's batch scraping capability (via batch_scrape_urls) to efficiently fetch the content of all discovered pages in parallel. For each successfully scraped page, it extracts the title, content (in markdown format), and URL from the API response and creates a Page object to store this data. The method returns a list of all successfully scraped pages. Pages that don't contain markdown content are skipped to ensure we only process relevant content.
Next, we have data storage:
def save_pages(self, pages: List[Page], docs_dir: str):
"""Save scraped content as markdown files."""
Path(docs_dir).mkdir(parents=True, exist_ok=True)
for page in pages:
url_path = page.url.replace(self.base_url, "")
safe_filename = url_path.strip("/").replace("/", "-")
filepath = os.path.join(docs_dir, f"{safe_filename}.md")
with open(filepath, "w", encoding="utf-8") as f:
f.write("---\n")
f.write(f"title: {page.title}\n")
f.write(f"url: {page.url}\n")
f.write("---\n\n")
f.write(page.content)The save_pages method handles storing the scraped content to disk as markdown files. It takes a list of Page objects and a target directory path as input. For each page, it:
- Creates the output directory if it doesn't exist
- Extracts a clean filename from the page URL by removing the base URL and replacing slashes
- Constructs the full output filepath
- Writes the content with YAML frontmatter containing metadata like title and URL
- Saves the markdown content of the page
This approach preserves the original content structure while adding useful metadata in a standard format. The markdown files can then be easily processed further or used directly.
When adapting the storage logic:
- Choose an appropriate file format (markdown, JSON, etc.)
- Implement proper error handling for file operations
- Consider compression for large datasets
- Add metadata that's relevant to your use case
Finally, we have a parent method to tie everything together:
def pull(self, base_url: str, docs_dir: str, n_pages: int = None):
self.base_url = base_url
pages = self.scrape_sublinks(base_url, n_pages)
self.save_pages(pages, docs_dir)Now, we can pull all the pages of both the blog and the documentation:
if __name__ == "__main__":
load_dotenv()
scraper = Scraper(base_url=BLOG_URL)
scraper.pull(BLOG_URL, "data/raw/firecrawl/blog")
scraper = Scraper(base_url=DOCS_URL)
scraper.pull(DOCS_URL, "data/raw/firecrawl/docs")Note the use of
load_dotenv()to read environment variables from a.envfile.
Key considerations for your own implementation:
- Data quality: Ensure your scraping captures all necessary content
- Error handling: Implement robust error handling and logging
- Rate limiting: Respect website limits and implement appropriate delays
- Storage: Choose appropriate storage formats and organization
- Validation: Add checks to ensure scraped data meets your requirements
- Documentation: Document any site-specific handling or assumptions
An important point to mention here is how the Firecrawl documentation and blog is structured. The documentation is organized into clear sections with a hierarchical structure - main concepts, guides, API reference, etc. Each page follows a consistent format with a title, description, and content sections. The blog posts are more narrative in style but still maintain good structure with headers, code examples, and explanations. This consistent organization makes it easier to scrape and process the content while preserving the logical flow and relationships between different pieces of information.
Custom data sources often have different structures, making it impractical to use a single scraper for all of them. While implementing multiple scrapers takes some work, Firecrawl significantly reduces the overall effort by eliminating the need for traditional HTML/CSS scraping techniques. You can either convert web pages to markdown for AI (like you've already seen) or extract specific content by describing what you need in natural language.
Cleaning the documents
Now, we come to the dreaded part - cleaning the scraped documents. Whatever your task is, data cleaning is always going to be the most critical and time-consuming part of your project. Instruction dataset generation is no exception.
First of all, our curated dataset must be representative of how the fine-tuned model will be used. Once we have gathered enough raw data, our goal is to filter them to only keep high-quality data. In this context, high-quality data can be described through three main dimensions:
-
Accuracy: The data must be factually correct and relevant to the domain. This means ensuring that technical details, code examples, and explanations are accurate and up-to-date. For documentation data, accuracy also means maintaining consistency with the actual API behavior and implementation details. The samples should avoid any misleading or incorrect information that could negatively impact the model's learning.
-
Diversity: The dataset needs to cover the full spectrum of use cases that represent real-world usage. This includes different types of queries (how-to guides, troubleshooting, conceptual explanations), varying levels of technical depth, and different aspects of the API or product. A diverse dataset helps prevent the model from becoming overly specialized in one area while being weak in others.
-
Complexity: The dataset should incorporate samples that require sophisticated reasoning and multi-step problem solving. This could include debugging scenarios, architectural decisions, performance optimization recommendations, and security considerations. Complex examples help the model develop deeper understanding and better reasoning capabilities, rather than just memorizing simple patterns.
Our aim is to transform the raw markdown files into the following instruction-answer format that also meet the above criteria at the same time:
{
"instruction": "How do I specify which paths to include or exclude during a crawl?",
"answer": "You can use the `includePaths` and `excludePaths` parameters in your request to specify which paths to include or exclude. Here's an example in Python:\n```...```\n\n In this example, the crawler will include only the `/public` path and exclude the `/private` path from the crawl."
}That is exactly what the src/process_dataset.py file does. Since it is over 300 lines long, we won't focus on the implementation details but provide a high-level overview of the functions used to transform the raw files:
def load_config() -> Config:
"""Load configuration from environment or defaults"""
...This function creates a configuration object with settings for the dataset processing. It reads from environment variables or uses default values for:
- Input directory containing markdown files
- Output file path for the processed dataset
- Keywords to filter relevant content
- Processing parameters like chunk size and model settings
def clean_markdown(content: str) -> str:
"""Clean markdown content while preserving important information."""
...Takes raw markdown text and cleans it by:
- Removing empty markdown links
- Fixing escaped characters
- Normalizing whitespace and newlines
- Preserving important formatting
def process_directory(input_dir: Path, output_dir: Path):
"""Process all markdown files in a directory."""
...Processes an entire directory of markdown files by:
- Finding all
.mdfiles recursively - Cleaning each file's content
- Saving cleaned files to output directory with same structure
These three functions combined are responsible for cleaning the raw markdown files and saving them back to a new directory for further processing.
The next set of functions handles filtering file contents to extract relevant text. This filtering step is important for two reasons. Documentation pages already contain focused information about Firecrawl, but blog articles often discuss other topics not directly related to Firecrawl. We need to identify and keep only the paragraphs that specifically discuss Firecrawl functionality, which we accomplish through keyword-based filtering.
Let's look at the first filtering function in process_dataset.py - a simple boolean check that determines if a text contains any specified keywords:
def contains_keywords(text: str, keywords: List[str]) -> bool:
"""Check if text contains any keywords (case-insensitive)."""
...We will use contains_keywords on chunks of markdown files generated by the function below:
def chunk_markdown(content: str, ...) -> List[str]:
"""Split markdown into chunks based on headers."""
...
return chunkschunk_markdown splits a markdown file based on H2, H3 or H4 headings and only keep the chunks that contain certain keywords related to Firecrawl using the contains_keywords method above.
Then, we create another function to standardize these chunks into a list of dictionaries format:
def process_chunks_in_batches(chunks: List[str], ...) -> List[Dict]:
"""Process chunks in batches."""
...
return informative_chunksIn this function, each chunk is represented by a dictionary with the chunk's contents, metadata and a unique ID generated using the uuid library.
Finally, we create a parent function to orchestrate everything:
async def create_dataset(config: Config):
"""Create the final dataset."""
...
# Save dataset
save_json(config.output_file, {"data": dataset})The function retrieves all cleaned markdown files, chunks them based on headers, filters the chunks using Firecrawl-related keywords, standardizes them into a uniform format and saves them to a JSON file. Here is what this JSON file looks like containing over 1300 chunks:
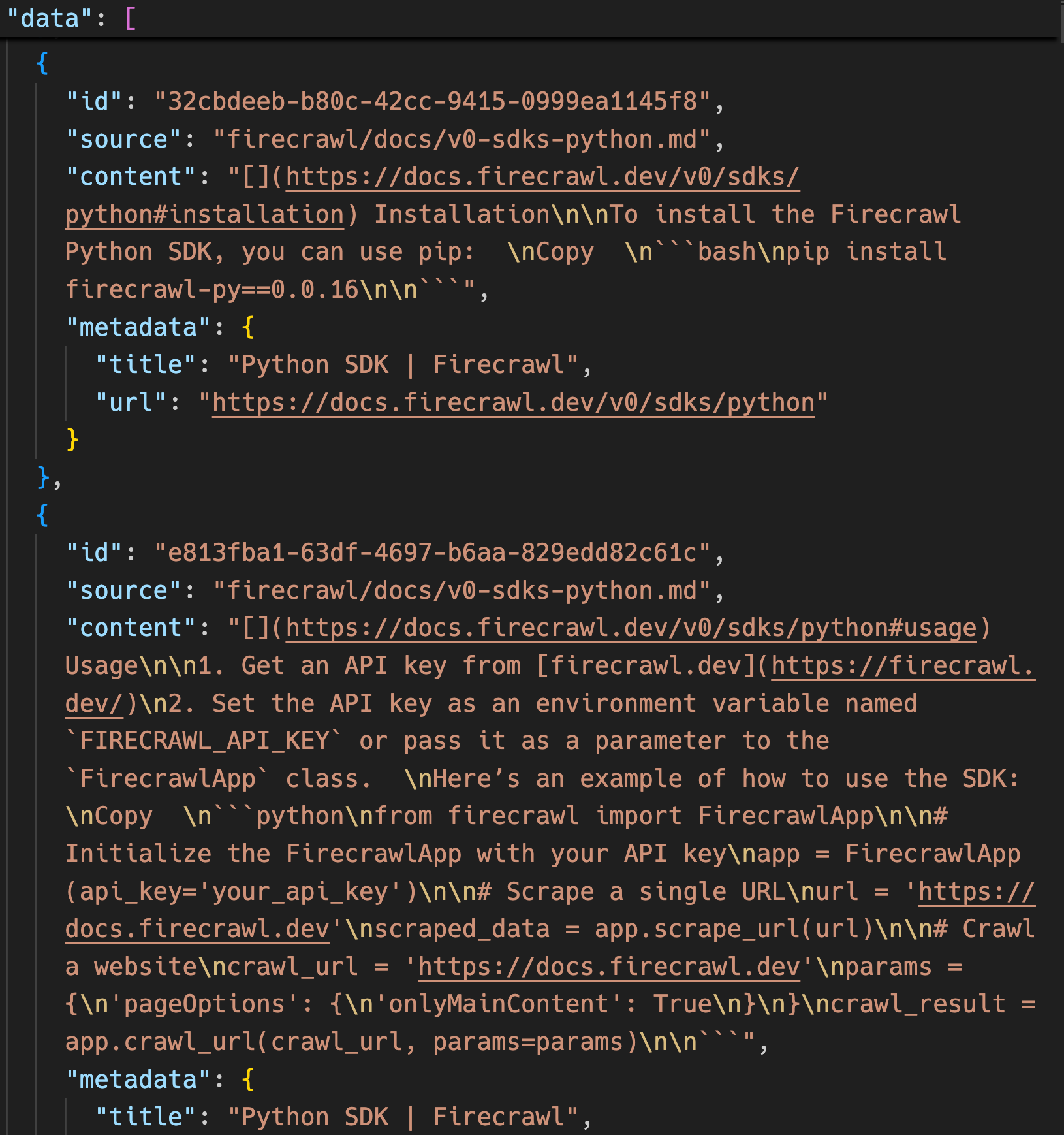
Each chunk contains important information about Firecrawl and how to use its SDKs. As you can see, each chunk dictionary has the following attributes:
- ID
- Source file path
- Content
- Metadata
Here is how you can adapt this script for your own project:
- For different content types:
- Modify
clean_markdown()to handle your specific formatting - Add custom cleaning rules in
process_directory()
- For different chunking strategies:
- Adjust header levels in
chunk_markdown() - Implement custom splitting logic
- Modify chunk filtering criteria
- For different filtering needs:
- Update
blog_keywordsinconfig(see the full script itself to see the keywords) - Add custom filtering functions
- For different output formats:
- Modify the output structure in
process_chunks_in_batches() - Update the save format in
create_dataset() - Add custom serialization methods
- For performance optimization:
- Adjust batch sizes in config
- Implement caching if needed
- Add parallel processing for large datasets
Remember to:
- Test changes with small datasets first
- Monitor memory usage with large files
- Add error handling for your specific cases
- Document any custom logic you add
Generating instruction-answer pairs
At this stage, we have cleaned and chunked our raw curated data into an acceptable format. However, we still need one more step to go from chunks to instruction-answer pairs.
While such data can be generated manually by individuals or through crowdsourcing, these methods often generate significant costs. A much budget-friendly alternative is using LLMs to generate synthetic data. LLMs can function at a much larger scale and cost significantly less than manual data preparation.
That is exactly what we are doing inside src/generate.py of our repository. The script takes our processed chunks as anchors or contexts and generates 5 synthetic instruction-answer pairs off of each. This results in more than 6k pairs, a respectable size for a fine-tuning job.
Let's break down the script, starting with the generate_pairs_for_chunk method:
async def generate_pairs_for_chunk(
chunk: Dict, chat: ChatOpenAI, ...
) -> List[Dict]:
"""Generate instruction-answer pairs with rate limiting."""
# ... the rest of the method
messages = [
SystemMessage(content=SYSTEM_PROMPT),
HumanMessage(
content=f"Generate instruction-answer pairs from this documentation:\n\n{chunk['content']}"
),
]
response = await chat.ainvoke(messages)
# ... the rest of the method
return pairsThis method takes a chunk dictionary as input and generates five instruction-answer pairs using a chat model through LangChain. The method is also responsible for parsing the LLM's output into 5 distinct instruction-answer pair dictionaries.
Next, we have the generate_dataset method:
async def generate_dataset(
input_file: Path, output_file: Path, chunk_limit: int = None
):
"""Generate dataset with parallel processing and rate limiting."""
...This function processes all chunks we have, generates 5 instruction-answer pairs using generate_pairs_for_chunk and combines them all to a single JSON dataset file"
if __name__ == "__main__":
input_file = Path("data/firecrawl_chunked_dataset.json")
output_file = Path("data/firecrawl_instructions.json")
asyncio.run(generate_dataset(input_file, output_file))There are many important points to keep in mind when orchestrating this synthetic data generation process.
First and most important is the system prompt used to guide the model's generation. The system prompt must be well-crafted to guide the language model to produce diverse, relevant, and high-quality instruction-response pairs. The system prompt we've used includes specific instructions, several example pairs and constraints to ensure the generated data aligns with the desired format and content.
Even though our system prompt is over 100 lines, many production synthetic-data generation pipelines include multiple layers to ensure data quality. This may include generating an initial set of pairs, then another system for implementing validation steps where another model checks the generated pairs for accuracy, relevance and adherence to the system prompt instructions (LLM-as-a-judge).
Another key factor is the model itself. Our script used gpt-4o-mini for its low costs and fast token generation (it costs about $1 to generate the entire dataset) but in a real-world setting, you should preferably choose gpt-4o or claude-3-5-sonnet as they offer much higher performance. But they often cost up to 20 times higher than smaller models, so you need to think about balancing cost and accuracy depending on your fine-tuning task. Keep in mind that implementing additional data quality layers incur yet higher costs.
Finally, you must consider the time and rate limiting of the chosen model. Most LLM APIs have strict rate limits. Our script implements rate limiting using semaphores and token counting to stay within these limits while maximizing throughput. We also use concurrent processing with asyncio to parallelize requests efficiently. Without proper rate limiting, your requests will be throttled or rejected, significantly slowing down or breaking the data generation process.
Uploading generated pairs to HuggingFace Datasets
At this stage, you can call it a day since you already have the dataset. But to provide easy access to it to your colleagues or to third parties (if it is a public dataset), you must upload it to HuggingFace Hub. Once uploaded, anyone can use your dataset through the datasets library for fine-tuning tasks.
This is what is happening inside the src/upload_to_hf.py file. The prepare_dataset function transforms the instruction-answer pairs to HuggingFace-compatible format, splits it into training and validation sets and returns them as a DatasetDict object.
This object is then sent to HuggingFace inside the push_to_hub method. A few minutes after uploading, you will be able to explore the dataset on the platform visually:
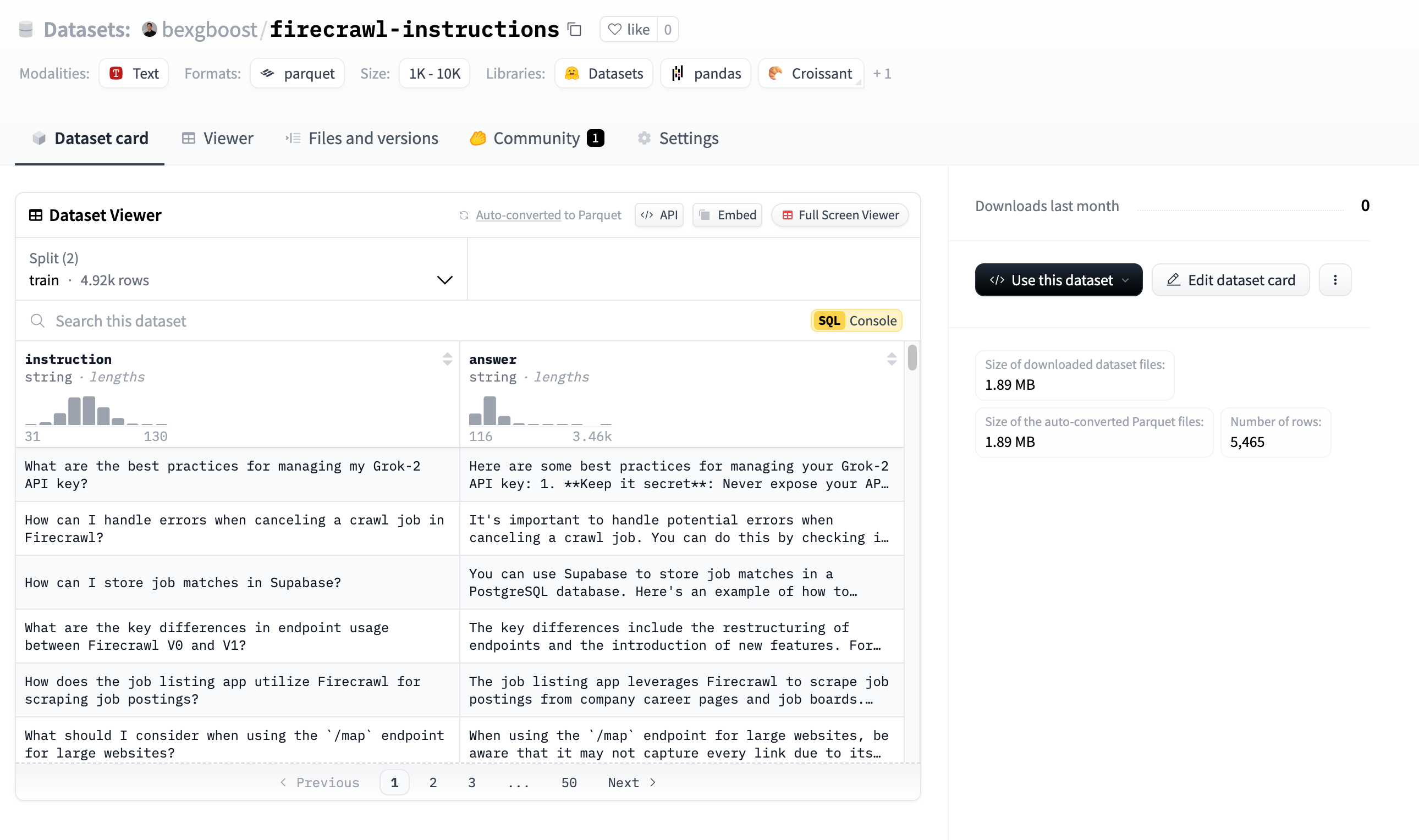
To use the dataset, all you have to do is run these couple lines of code in your environment:
from datasets import load_dataset
ds = load_dataset("bexgboost/firecrawl-instructions")General Process For Creating Instruction Datasets
Let's summarize the key steps we took to create our instruction dataset, which you can follow for your own tasks:
-
Prepare your source data
- Gather documentation, articles, or other text content
- Clean and preprocess the text as needed
- Split into manageable chunks if working with large documents
-
Design your system prompt
- Write clear instructions for the LLM
- Include example instruction-response pairs
- Define constraints and quality requirements
- Test and refine the prompt with sample generations
The majority of your time must be spent implementing steps 1 and 2.
-
Set up the generation pipeline
- Choose an appropriate LLM (consider cost vs quality tradeoffs)
- Implement rate limiting and concurrency controls
- Add error handling and logging
- Consider adding validation steps (LLM-as-judge)
-
Generate the dataset
- Run the generation script
- Monitor the process for errors
- Sample and manually review outputs
- Adjust parameters if needed
-
Process and format the data
- Convert to the desired format (JSON, CSV etc.)
- Split into train/validation sets
- Add metadata if needed
- Validate the final structure
-
Share and distribute
- Upload to a platform like HuggingFace
- Document the dataset creation process
- Provide usage examples
- Set appropriate access permissions
Following these steps will help ensure you create a high-quality instruction dataset suitable for fine-tuning language models.
Conclusion
Creating high-quality instruction datasets is crucial for fine-tuning language models that can perform specialized tasks effectively. Through this guide, we've demonstrated how to build such datasets systematically, using Firecrawl's documentation as a practical example. Let's recap the key takeaways:
Key Learnings
- Data Quality Matters: The success of your fine-tuned model heavily depends on the quality of your instruction dataset. Invest time in proper data cleaning and validation.
- Automation is Essential: Using tools like Firecrawl and LLMs for data generation can significantly reduce the time and cost of dataset creation, while maintaining quality.
- Balance is Critical: When generating synthetic data, balance between quantity, quality, and cost is crucial. While larger models like GPT-4 provide better quality, smaller models can be cost-effective for initial iterations.
- Process Matters: Following a structured process - from data collection through cleaning to generation - helps ensure consistent quality and reproducible results.
Practical Considerations
- A dataset of 5,000-10,000 high-quality instruction-answer pairs is often sufficient for specialized fine-tuning
- Budget approximately $1-20 for synthetic data generation, depending on the chosen LLM
- Plan for 2-3 iterations of data cleaning and validation to achieve optimal quality
- Consider implementing automated quality checks to maintain consistency
Next Steps
If you're ready to create your own instruction dataset:
- Start Small: Begin with a pilot dataset of 100-200 pairs to test your pipeline
- Validate Early: Implement quality checks from the beginning
- Iterate Quickly: Get feedback and refine your process before scaling up
- Monitor Quality: Regularly review generated pairs and adjust your system prompt as needed
Additional Resources
- Firecrawl Documentation - For detailed API reference
- Stanford Alpaca Paper - For insights on instruction tuning
- HuggingFace's Guide to Dataset Creation
- Our Example Repository
Future Improvements
The field of instruction tuning is rapidly evolving. Some promising areas for future exploration include:
- Multi-modal Instructions: Incorporating images and code snippets into instruction datasets
- Automated Validation: Using LLMs to validate and improve generated pairs
- Cross-lingual Datasets: Creating instruction sets that work across multiple languages
- Dynamic Updates: Building systems for continuous dataset improvement based on model performance
By following the approaches outlined in this guide and staying current with these developments, you'll be well-equipped to create effective instruction datasets for your specific use cases. Whether you're building a specialized coding assistant, a domain-specific chatbot, or any other AI application, the quality of your instruction dataset will be a key determinant of your model's success.
