
Introduction
Retrieval Augmented Generation (RAG) is changing how AI systems work, especially when it comes to large language models (LLMs). Unlike regular LLMs that only use what they learned during training, RAG systems actively look up information from sources like company documents, databases, or online references before answering questions. This approach lets companies use their own data alongside the general knowledge built into LLMs, making AI responses more accurate and reliable.
RAG is particularly important for businesses and specialized fields where getting facts right matters. By looking up information instead of just relying on what the AI model already knows, RAG greatly reduces "hallucinations" - those awkward moments when AI confidently makes up incorrect information. This matters because AI hallucinations have caused real problems, like chatbots inventing fake company policies or legal AI citing court cases that don't exist. With RAG, AI systems can give answers that are factually correct and relevant without needing to retrain the entire model.
In this article, we'll break down the technology behind RAG systems, help you decide whether to build one from scratch or use existing solutions, and introduce you to the key tools and platforms for each part of an effective RAG system.
If you want a comprehensive article on building a simple RAG application with DeepSeek R1 model, check out our separate guide.
When You Shouldn't Build a RAG System from Scratch
While RAG systems sound great in theory, the reality is that about 90% of companies' AI projects never make it past the testing phase. Building a RAG system from scratch is complex and resource-intensive. Here are five situations where you're better off using existing platforms instead of building your own:
1. When your team lacks AI expertise
If your team doesn't have specialists who understand vector databases, embedding models, or LLM orchestration, you'll struggle with technical challenges. You might not know how to break documents into the right-sized chunks or how to choose the best embedding model. Advanced search techniques will also be difficult to implement. Pre-built solutions like IBM watsonx Orchestrate or Azure AI Search handle these technical details for you, making implementation much simpler.
2. When you need to launch quickly
Ready-made solutions can save you months of development time. AWS Kendra connects to over 40 different data sources automatically without extra coding. Pinecone offers vector databases that scale with one click, while Cohere Coral provides simple APIs for complex RAG workflows. These tools eliminate infrastructure development while still meeting enterprise security requirements.
3. When you work in highly regulated industries
Healthcare, finance, and other regulated fields benefit from platforms with built-in compliance features. These include pre-configured content filters for your specific industry, built-in tracking for compliance audits, and guaranteed data processing within approved regions. Commercial platforms often have these safeguards built right in, saving you from having to develop them yourself. For example, BloombergGPT is highly specialized for finance sector, while AWS HealthLake is for medicine.
4. When you need consistency across teams
Organizations with multiple AI applications benefit from standardized tools that provide unified monitoring systems, centralized knowledge bases, and reusable components across departments. Without standardization, you risk creating "RAG sprawl" – different departments using different approaches that don't work well together.
It's worth noting that newer models with large context windows (like Gemini 2.0 with 2 million tokens of context window) can now handle a wide range of use cases that required RAG. For most companies, using ready-made enterprise systems can give you 80% of what RAG can do with only 20% of the effort – making custom builds worthwhile only for truly unique requirements.
When You Should Build a RAG System from Scratch
While pre-built solutions work well in many cases, sometimes building your own RAG system makes more sense. If your company works in a highly specialized field with unique data needs, custom RAG development lets you fine-tune each part of the system for your specific use case. For example, a pharmaceutical company might need special document handling for research papers that generic solutions don't provide. Custom systems can often perform better for these specialized tasks.
Security and control are other good reasons for building your own system. If your business has strict rules about where data can be stored or processed, off-the-shelf options might not meet your needs. Similarly, if you're working with extremely large amounts of data or need to handle complex queries that would slow down regular systems, a custom solution might be worth the investment. Companies with existing AI teams find this approach particularly doable.
Custom RAG development can also give your business an edge over competitors. When AI capabilities directly impact your main products or services, having a unique system that others can't easily copy becomes valuable. This works best when your company already has strong AI engineers and sees AI as a key part of your future strategy, not just a nice-to-have tool. Building your own system also makes sense when you need it to work smoothly with other specialized software your company already uses that might not connect easily to commercial platforms.
Modern Tech Stack For RAG Implementation
Building an effective RAG system requires carefully selecting the right tools for each stage of the pipeline. Each component serves a specific purpose in transforming raw data into AI-ready knowledge and generating accurate responses. The following sections explore the essential tools that power modern RAG systems, organized by where they fit in the workflow and what specific challenges they address. Understanding these components will help you build a more effective system or evaluate existing solutions for your specific needs.
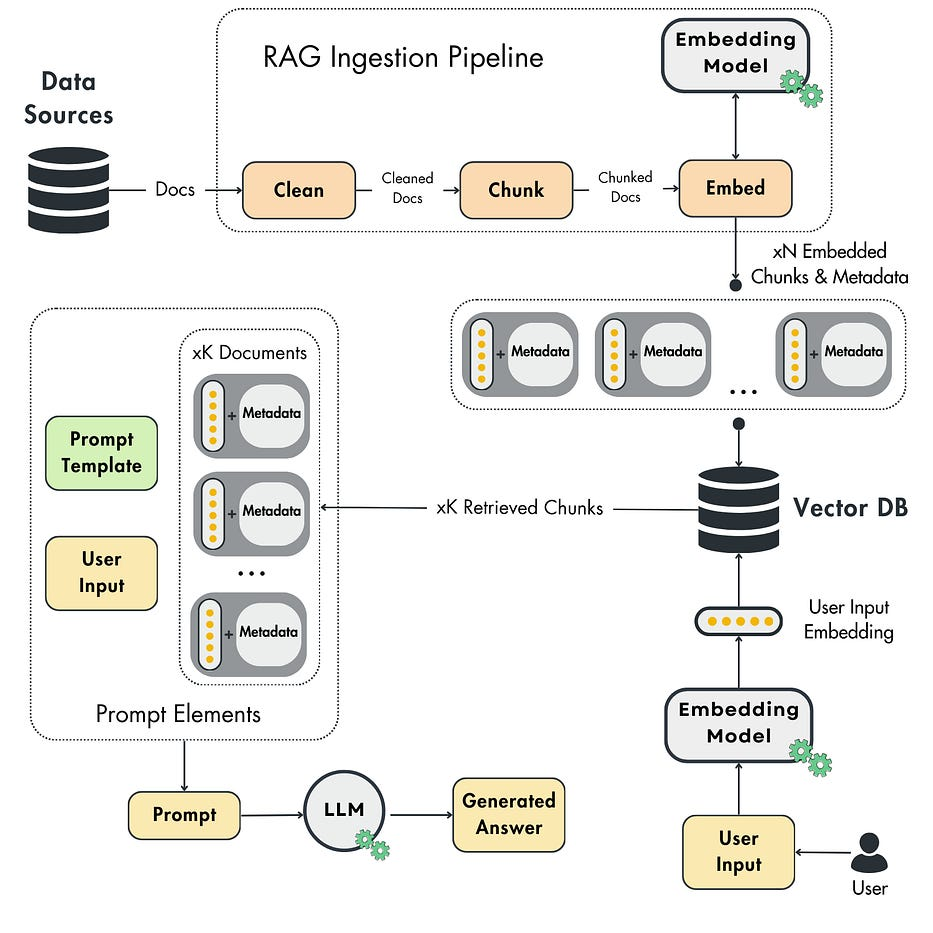
Source: Decoding ML
Ingestion pipeline tools
The ingestion pipeline forms the foundation of any RAG system by transforming raw data into a searchable knowledge base. This critical first stage determines what information your AI can access and how effectively it can be retrieved later. The quality of your ingestion process directly impacts the accuracy and relevance of your RAG system's responses, making it essential to choose the right tools for each step. Let's examine the specialized tools available for each phase of the ingestion process.
Data extraction tools
Effective RAG systems need access to information stored across diverse repositories, from document collections to databases to websites. Data extraction tools solve the challenge of connecting to these varied sources and bringing their content into your processing pipeline. They handle different authentication methods, file formats, and access patterns, allowing you to build a comprehensive knowledge base from scattered information. These connectors serve as the first step in making your organization's knowledge accessible to AI systems:
-
LangChain Document Loaders: Framework offering 80+ connectors to extract data from diverse sources including databases, APIs, and files with a unified interface.
-
LlamaIndex DB Connectors: Utilities specifically optimized for connecting to and extracting data from structured databases while preserving relationships.
-
Unstructured.io: Specialized platform for extracting content from unstructured documents like PDFs and images with layout awareness.
-
ConnectorX: High-performance data connector for efficiently loading large datasets from databases with minimal memory footprint.
-
Apify: Enterprise-grade web scraping and automation platform for extracting data from websites and web applications, handling JavaScript-heavy sites. See the top Apify alternatives if you need more AI-native output or a simpler pricing model.
-
MakeAPI: Low-code integration platform for connecting to and extracting data from various APIs through visual workflow builders. For a comparison of Make alongside n8n, Zapier, Cursor Automations, and Gumloop, see the guide to AI workflow automation tools.
-
Firecrawl: Specialized tool for web scraping that handles challenging websites with JavaScript rendering and dynamic content.
Among these extraction tools, web scraping platforms like Firecrawl deserve special attention as they solve particularly difficult data acquisition challenges for RAG implementations. Web content represents a vast knowledge source, but its dynamic nature makes reliable extraction complex for AI applications. A frequent starting point is ingesting a documentation site for RAG — crawling a Docusaurus or GitBook site and loading every page as clean markdown into a vector database.
When implementing RAG systems, we often encounter challenges extracting data from modern websites due to their dynamic nature and inconsistent formatting. Firecrawl addresses these difficulties through several specialized endpoints: the /scrape endpoint transforms JavaScript-heavy pages into markdown format suitable for embedding, the /extract endpoint converts semi-structured web data into consistent JSON outputs based on our schemas, the /crawl endpoint systematically explores websites to gather interconnected information, and the /llmstxt functionality processes websites into standardized text files that conform to emerging standards for language model consumption. These capabilities prove particularly valuable when incorporating external knowledge sources into our retrieval systems while maintaining consistent data quality across diverse sources. We can explore the scrape endpoint's capabilities, LLMs.txt and other fundamental concepts to better understand how to leverage web content in our retrieval systems.
Document processing tools
Raw data rarely arrives in formats that are immediately suitable for AI processing. Document processing tools solve this critical challenge by cleaning, normalizing, and structuring diverse content types. They can identify important document elements like tables, headers, and lists while filtering out irrelevant content like headers, footers, and formatting artifacts. These tools bridge the gap between human-oriented documents and machine-readable formats, preserving semantic meaning while optimizing for AI consumption:
-
MarkItDown: Microsoft's lightweight utility that converts various file formats to Markdown specifically optimized for LLMs, preserving document structure while minimizing token usage.
-
ExtractThinker: Library using LLMs to extract structured data from documents with ORM-style interactions and Pydantic model integration.
-
MegaParse: Commercial solution for transforming complex documents like contracts and invoices into structured data through AI-powered extraction.
-
LlamaParse: LlamaIndex's document parsing platform built specifically for LLM use cases with state-of-the-art table extraction and natural language instructions.
-
Docling: IBM Research's toolkit specialized in understanding and processing complex document layouts in scientific and technical documents.
-
Fire-PDF: Firecrawl's Rust-based PDF parsing engine that routes each page to the fastest extraction path — native text extraction for searchable pages, GPU-accelerated OCR for scanned pages — averaging under 400ms per page with no configuration required. For local or non-public documents (PDFs, DOCX, XLSX, RTF), the Firecrawl /parse endpoint accepts direct file uploads and returns the same structured Markdown output.
For a hands-on comparison of these and other PDF parsers specifically for AI and RAG pipelines, see the best PDF parsers guide. For a broader evaluation of managed document parsing APIs — covering PDF parsing APIs, document extraction APIs, and AI document processing services — see the best document parsing APIs guide.
Chunking/text splitting tools
Most documents are too long to process as single units, creating the need for intelligent document splitting. Chunking tools divide content into smaller pieces that balance preserving context with creating focused, retrievable segments. How you chunk documents directly impacts retrieval quality - chunks that are too small lose important context, while chunks that are too large contain irrelevant information that dilutes relevance. The best chunking approaches consider document structure, semantic boundaries, and the specific needs of your use case:
-
LangChain Text Splitters: Comprehensive collection of text splitting methods including recursive character splitting, token-aware splitting, and specialized splitters for code, HTML, and Markdown with header preservation.
-
Unstructured.io Chunking: Advanced chunking capabilities that understand document layout and semantics, preserving logical sections like headers and tables.
-
LlamaHub: Repository of specialized data loaders and processing tools with chunking capabilities tailored for specific document types and use cases.
Embedding tools
Converting text into mathematical vector representations is the core technology that enables semantic search in RAG systems. Embedding models analyze words and sentences to produce numerical arrays that capture meaning - similar concepts cluster together in this mathematical space, regardless of the specific words used. The quality of these embeddings directly determines how well your system can match questions to relevant information, with more advanced models better capturing nuanced meanings across different languages and domains:
-
OpenAI Embeddings: High-quality embedding models (
text-embedding-3-smalland-large) with context windows up to 8191 tokens and strong performance on benchmarks. -
BGE-M3: Multilingual embedding model from BAAI supporting over 100 languages for both dense and sparse retrieval with state-of-the-art performance.
-
Cohere Embed: Specialized embedding models optimized for different input types (queries vs. documents) with multilingual support and customization options.
-
Sentence Transformers: Easy-to-use embedding library with pre-trained models for various use cases, requiring just a few lines of code to implement.
-
Voyage AI: Embedding models with extra-long context windows up to 32,000 tokens, ideal for processing longer documents without chunking.
-
Ollama Embeddings: Local embedding models accessible through simple API calls for deployments with data privacy requirements.
Vector database tools
Vector databases provide the specialized infrastructure needed to store and search massive collections of embeddings efficiently. Unlike traditional databases optimized for exact matching, vector databases excel at finding similar items in high-dimensional space through approximate nearest neighbor algorithms. They balance search speed with accuracy through specialized indexing methods, while offering features like metadata filtering and scalability for growing datasets. The choice of vector database impacts both the performance and capabilities of your RAG system. For a full comparison of options including benchmarks, pricing, and trade-offs, see our vector database guide:
-
Milvus: Powerful open-source vector database able to handle billions of vectors with GPU acceleration and advanced indexing methods for enterprise-scale deployments.
-
Qdrant: Vector database with particularly strong filtering capabilities alongside similarity search, ideal for applications requiring complex metadata filtering.
-
Weaviate: Vector database with GraphQL integration for flexible querying and object-based data modeling with cross-references between objects.
-
Chroma: Lightweight vector database that's easy to set up and use for smaller projects or proof-of-concept implementations with minimal configuration.
-
Pinecone: Fully managed vector database service that automatically scales with usage and offers serverless deployment options.
-
FAISS: Facebook's efficient similarity search library for those who need fine-grained control over indexing algorithms and memory-performance tradeoffs.
Retrieval pipeline tools
After building a knowledge base, the retrieval pipeline faces the challenge of finding the most relevant information when users ask questions. This stage determines what context the language model will receive, directly impacting response quality. Effective retrieval goes beyond simple similarity matching to understand questions, expand queries, and precisely rank results. The following tools enhance different aspects of the retrieval process, helping systems find truly relevant information even when questions use different terminology than the source material.
Query understanding tools
Understanding what users are really asking often requires going beyond their exact words to capture their underlying intent. Query understanding tools help bridge the gap between how questions are phrased and how information is stored in your knowledge base. They can expand ambiguous queries, generate alternative phrasings, or even create synthetic documents that represent possible answers to improve retrieval. These techniques significantly boost the recall of relevant information, especially for complex or ambiguous questions:
-
HyDE (Hypothetical Document Embeddings): Technique that generates a hypothetical answer to improve retrieval by using this synthetic document to search rather than just the original query.
-
Multi-query Expansion: Method for automatically creating variations of user questions to improve recall by capturing different phrasings and aspects of the query.
Reranking tools
Initial vector search typically prioritizes recall, finding many potentially relevant documents, but not always ranking the most useful ones first. Reranking tools apply more sophisticated analysis to this initial set of candidates, evaluating how well each truly answers the specific question. They consider factors beyond simple similarity, such as whether the document contains the specific information needed or provides a direct answer to the question. This second-stage precision filtering significantly improves the quality of information provided to the language model:
-
Cohere Rerank: Specialized model for reordering search results based on relevance to the query, with state-of-the-art performance on reranking benchmarks.
-
BGE Rerank: Efficient reranking model for improving retrieval precision by evaluating candidate passages against the original query.
Hybrid search tools
Different search approaches have complementary strengths and weaknesses - semantic search excels at finding conceptually related content while keyword search precisely matches specific terms. Hybrid search tools combine multiple retrieval methods to overcome these limitations and deliver more comprehensive results. They can integrate dense vector retrieval, sparse lexical search, and even knowledge graph relationships to find information through multiple pathways. This multi-modal approach leads to more robust retrieval that works across different types of questions and content:
-
DPR (Dense Passage Retrieval): Framework combining neural and keyword-based search for improved performance over either method alone.
-
ColBERT: Advanced retrieval system using late interaction between queries and documents for more precise matching with manageable computational requirements.
-
Neo4j: Graph database enabling knowledge graph-enhanced retrieval by leveraging relationships between concepts for more sophisticated information findability.
Generation pipeline tools
The generation pipeline transforms retrieved information into coherent, accurate responses tailored to user questions. This stage leverages large language models to synthesize information, format answers appropriately, and ensure factual accuracy. The quality of generation depends not only on the underlying language model but also on how effectively it's prompted, guided, and evaluated. The following tools power different aspects of the generation process, from the core language models to specialized components that enhance response quality.
LLM providers
Large language models form the core reasoning engine of RAG systems, determining the quality, style, and capabilities of generated responses. Different LLM providers offer varying strengths in areas like reasoning, instruction following, multilingual support, and specialized knowledge domains. Model selection involves balancing factors like performance, cost, deployment options, and specific capabilities needed for your application. These providers offer access to state-of-the-art language models through various deployment options:
-
OpenAI GPT: Family of powerful language models (GPT-3.5, GPT-4) accessible through API with varying capabilities and context windows.
-
Anthropic Claude: Models designed with a focus on safety and helpfulness, known for clear explanations and following complex instructions.
-
Cohere Command: Language models specialized for business applications with robust reasoning and safety guardrails.
-
Google Gemini: Multimodal models supporting text, images, and other data types with strong reasoning capabilities.
-
Ollama: Platform for running open-source LLMs locally with simple installation and API compatibility.
-
Groq: High-speed inference platform for fast LLM responses, offering some of the lowest latency in the industry.
-
Together AI: Infrastructure for running and fine-tuning open-source models with cost-effective inference.
-
Hugging Face: Platform providing access to thousands of open AI models with flexible deployment options.
Prompt engineering tools
How you instruct language models directly impacts the quality, format, and accuracy of their responses. Prompt engineering tools help construct effective instructions that guide models in using retrieved information, following response formats, and adhering to business rules. They provide structured ways to combine user questions, retrieved context, and system instructions into coherent prompts that maximize model performance. These frameworks streamline the development of reliable, consistent prompt patterns across different use cases:
-
LangChain: Comprehensive framework for developing LLM applications with specialized components for prompt management, memory, and chains of operations.
-
LlamaIndex: Data framework focused on connecting LLMs with external data sources through flexible indexing and retrieval patterns.
-
Guardrails AI: Library for adding safety guardrails to LLM outputs through validation, sanitization, and policy enforcement.
-
LlamaGuard: Content moderation model specifically designed for ensuring appropriate LLM responses through content filtering.
Fact-checking and post-processing tools
Even with retrieved context, language models can sometimes generate inaccurate or problematic content. Fact-checking and post-processing tools serve as quality control mechanisms for RAG outputs, verifying factual accuracy, ensuring appropriate content, and formatting responses consistently. They can detect when models hallucinate information not found in retrieved documents, flag potential biases or harmful content, and provide citations linking responses back to source documents. These tools are essential for building trustworthy AI systems that users can rely on:
-
TruLens: Library for evaluating and explaining LLM-powered applications with specialized RAG metrics and hallucination detection.
-
Giskard: Open-source testing framework for ML models including LLMs, focused on identifying issues like bias and factual accuracy.
For broader visibility beyond fact-checking — cost tracking, latency monitoring, prompt drift detection — see our guide to LLM observability tools.
Orchestration and evaluation tools
Complex RAG systems involve many interconnected components that must work together smoothly at scale. Orchestration tools coordinate these components into reliable pipelines, while evaluation tools measure system performance and identify improvement opportunities. Together, these tools help bridge the gap between experimental prototypes and production-ready systems that deliver consistent value. The following sections explore key tools for managing and optimizing complete RAG systems.
Orchestration tools
Building RAG systems for production involves coordinating multiple services, managing computational resources, and ensuring reliable performance under varying loads. Orchestration tools solve these challenges by providing frameworks for deploying, scaling, and monitoring complex AI workflows. They handle infrastructure concerns like compute allocation, service coordination, and failure recovery so that developers can focus on improving the core RAG functionality. These platforms bridge the gap between experimental prototypes and production-ready systems:
-
Beam AI: Platform for deploying and scaling AI applications with minimal infrastructure concerns, featuring automatic scaling.
-
Prefect Marvin: Workflow management tool designed specifically for LLM applications with robust scheduling and monitoring.
-
BentoML: Framework for standardizing ML model serving in production with consistent APIs and deployment patterns.
Evaluation tools
Measuring RAG system performance goes beyond simple accuracy metrics to evaluate dimensions like relevance, faithfulness to sources, and answer completeness. Evaluation tools provide specialized frameworks for assessing these multifaceted qualities across different types of queries and domains. They help identify specific weaknesses in retrieval or generation components, track performance over time, and compare different system configurations objectively. Continuous evaluation forms the foundation for systematic improvement of RAG systems:
-
Ragas: Framework with specialized metrics for evaluating RAG systems across dimensions like relevance, faithfulness, and answer correctness.
-
Giskard: Testing tool for identifying issues like hallucinations or bias in AI systems with comprehensive reporting.
-
TruLens: Evaluation tool with features for tracking how retrieved information is used in generating responses and measuring RAG-specific metrics.
Conclusion
Retrieval Augmented Generation represents a significant advancement in how organizations can leverage AI to access and utilize their knowledge. By combining the general capabilities of large language models with specific information retrieved from your own data sources, RAG systems deliver more accurate, reliable, and useful AI interactions. As we've explored in this article, implementing a RAG system involves careful consideration of each component - from data ingestion through retrieval to generation - and selecting the right tools for your specific needs. For organizations looking to incorporate web-based information into their RAG systems, we recommend trying Firecrawl, which excels at handling challenging websites with complex JavaScript and dynamic content, providing clean, structured data ready for AI consumption.
The RAG ecosystem continues to evolve rapidly, with new tools and techniques emerging regularly to address challenges and improve performance. Organizations that successfully implement RAG are finding they can create more trustworthy AI applications that truly reflect their unique knowledge and expertise. While building effective RAG systems requires careful planning and integration of multiple components, the tools and platforms we've discussed make this process increasingly accessible to organizations of all sizes. By understanding the core principles and available resources outlined in this article, and by leveraging specialized tools like Firecrawl for web data extraction, you're well-equipped to begin implementing RAG capabilities that can transform how your organization lever
