Anthropic recently launched prompt caching and cache control in beta, allowing you to cache large context prompts up to 200k tokens and chat with them faster and cheaper than ever before. This is a game changer for Retrieval Augmented Generation (RAG) applications that analyze large amounts of data. Currently caching is only avialable for Sonnet and Haiku but it is coming soon to Opus.
To showcase the power of prompt caching, let’s walk through an example of crawling a website with Firecrawl, caching the contents with Anthropic, and having an AI assistant analyze the copy to provide suggestions for improvement. See the code on Github.
Setup
First, make sure you have API keys for both Anthropic and Firecrawl. Store them securely in a .env file:
ANTHROPIC_API_KEY=your_anthropic_key
FIRECRAWL_API_KEY=your_firecrawl_key
Install the required Python packages:
pip install python-dotenv anthropic firecrawl requests
Crawling a Website with Firecrawl
Initialize the Firecrawl app with your API key:
app = FirecrawlApp(api_key=firecrawl_api_key)
Crawl a website, limiting the results to 10 pages:
crawl_url = 'https://dify.ai/'
params = {
'crawlOptions': {
'limit': 10
}
}
crawl_result = app.crawl_url(crawl_url, params=params)
Clean up the crawl results by removing the content field from each entry and save it to a file:
cleaned_crawl_result = [{k: v for k, v in entry.items() if k != 'content'} for entry in crawl_result]
with open('crawl_result.txt', 'w') as file:
file.write(json.dumps(cleaned_crawl_result, indent=4))
Caching the Crawl Data with Anthropic
Load the crawl data into a string:
website_dump = open('crawl_result.txt', 'r').read()
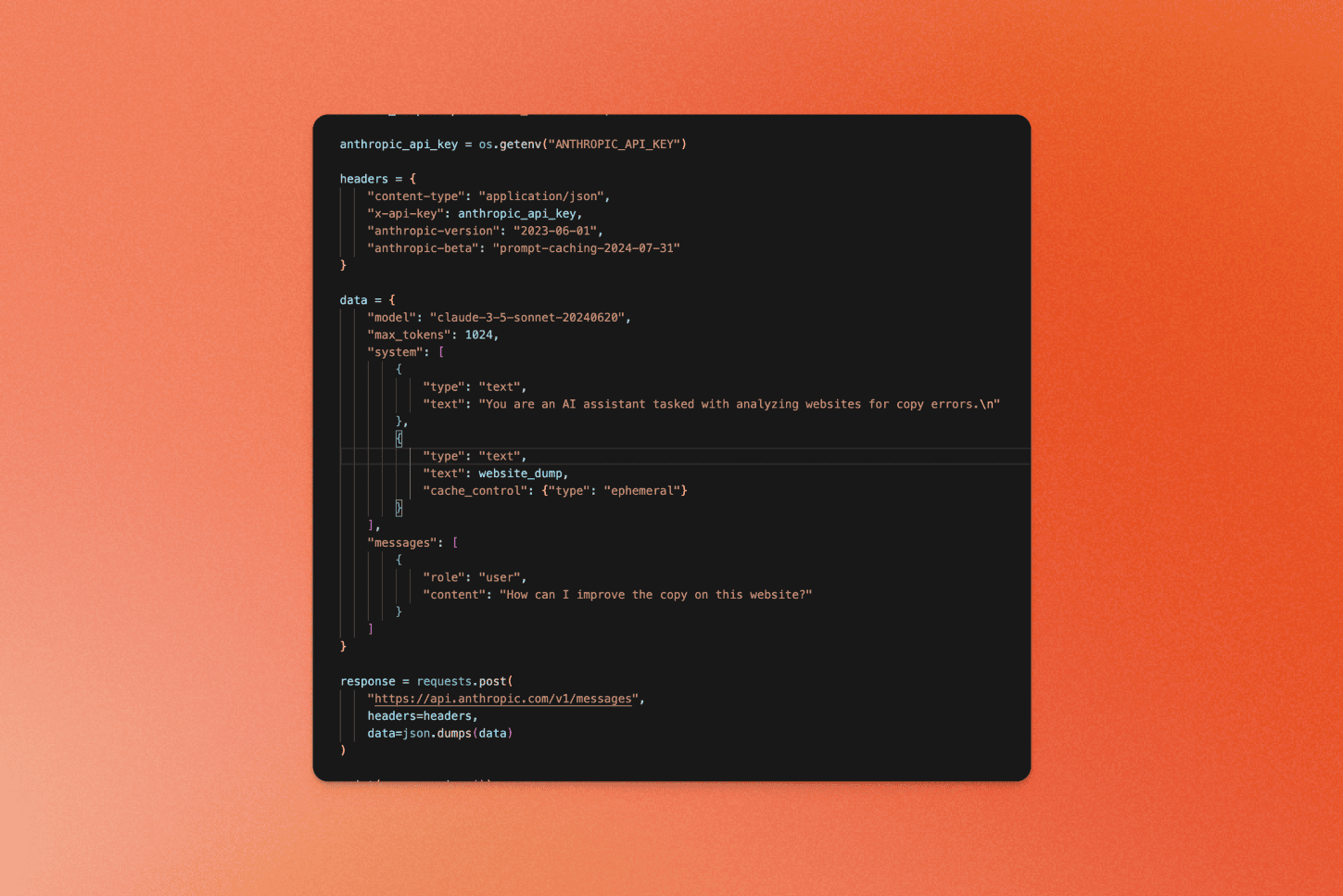
Set up the headers for the Anthropic API request, including the anthropic-beta header to enable prompt caching:
headers = {
"content-type": "application/json",
"x-api-key": anthropic_api_key,
"anthropic-version": "2023-06-01",
"anthropic-beta": "prompt-caching-2024-07-31"
}
Construct the API request data, adding the website_dump as an ephemeral cached text:
data = {
"model": "claude-3-5-sonnet-20240620",
"max_tokens": 1024,
"system": [
{
"type": "text",
"text": "You are an AI assistant tasked with analyzing literary works. Your goal is to provide insightful commentary on themes, characters, and writing style.\n"
},
{
"type": "text",
"text": website_dump,
"cache_control": {"type": "ephemeral"}
}
],
"messages": [
{
"role": "user",
"content": "How can I improve the copy on this website?"
}
]
}
Make the API request and print the response:
response = requests.post(
"https://api.anthropic.com/v1/messages",
headers=headers,
data=json.dumps(data)
)
print(response.json())
The key parts here are:
- Including the
anthropic-betaheader to enable prompt caching - Adding the large
website_dumptext as a cached ephemeral text in thesystemmessages - Asking the assistant to analyze the cached text and provide suggestions
Benefits of Prompt Caching
By caching the large website_dump text, subsequent API calls can reference that data without needing to resend it each time. This makes conversations much faster and cheaper.
Imagine expanding this to cache an entire knowledge base with up to 200k tokens of data. You can then have highly contextual conversations drawing from that knowledge base in a very efficient manner. The possibilities are endless!
Anthropic’s prompt caching is a powerful tool for building AI applications that can process and chat about large datasets. Give it a try and see how it can enhance your projects!

data from the web