
Introduction
Fine-tuning large language models (LLMs) has become an essential skill in the AI toolbox, allowing developers to customize powerful models for specific use cases. As these models continue to evolve, DeepSeek R1 has emerged as a promising open-source alternative that offers impressive capabilities while maintaining accessibility for developers and researchers.
In this comprehensive guide, we'll walk through the process of fine-tuning DeepSeek R1 using custom instruction datasets. Whether you're looking to enhance the model's performance for specialized tasks or adapt it to your domain-specific needs, this tutorial will provide you with the knowledge and practical steps to successfully fine-tune DeepSeek R1.
DeepSeek R1 Distilled Models
The DeepSeek R1 model contains over 600 billion parameters and requires data centers costing more than my house to run and fine-tune. To make the model more accessible, DeepSeek AI offers smaller alternatives through distilled versions.
These distilled versions are created through a process where the full model acts as a "teacher" guiding smaller "student" models. By transferring knowledge from the larger DeepSeek-R1 teacher model, more efficient student models like DeepSeek-R1-Distill-Qwen and DeepSeek-R1-Distill-Llama can be created, ranging from 1.5B to 70B parameters. This allows the smaller models to capture the reasoning capabilities of the full model (to a certain extent) while being much more practical to run and deploy.
In this tutorial, we will focus on its Llama-3.1 version with 8B parameters as it is the most practical version to run on consumer hardware or on free cloud services like Kaggle or Google Colab Pro (we will use Kaggle).
How to Find a Dataset For Fine-tuning DeepSeek?
Finding the right dataset is crucial for successful fine-tuning of any language model, including DeepSeek R1. The dataset should align with your intended use case and contain high-quality examples that demonstrate the behavior you want the model to learn.
Here are key considerations when selecting or creating a dataset for fine-tuning:
- Relevance: The dataset should closely match your target use case
- Quality: Data should be clean, well-formatted, and free of errors
- Size: While bigger isn't always better, aim for at least a few thousand examples
- Diversity: Include various examples covering different aspects of the desired behavior
- Format: Data should follow a consistent instruction-response format
Public datasets
There are already hundreds of high-quality open-source datasets to fine-tune reasoning models like DeepSeek R1. For example, by searching "cot" (chain-of-thought) datasets on HuggingFace Hub, you will get close to 1000 results:
Custom datasets
Despite the high availability of public datasets, there are many scenarios where you might need to create your own datasets to fine-tune models for specific tasks or domains. Here are approaches to build custom datasets:
-
Manual creation:
- Write your own instruction-response pairs
- Most time-consuming but highest quality control
- Ideal for specialized domains
-
Semi-automated generation:
- Use existing LLMs to generate initial examples
- Human review and editing for quality
- Faster than manual creation while maintaining quality
-
Data collection:
- Convert existing documentation or Q&A pairs
- Extract from customer interactions
- Transform domain-specific content into instruction format
Whichever approach you choose, you will need a web scraping solution to curate initial raw data. This is where Firecrawl comes in.
Firecrawl provides web scraping and crawling capabilities through an API interface. Rather than using CSS selectors or XPath expressions which can break when websites change, it uses AI-powered extraction to identify and collect data using natural language descriptions. It can also convert entire websites into collections of markdown documents, which is an ideal format to generate high-quality datasets for LLMs.
In our previous article on creating custom instruction datasets, we showed how to build a training dataset focused on Firecrawl's API. We used Firecrawl itself to crawl its own documentation and blog posts, then processed those pages into structured data. Using GPT-4o-mini, we generated instruction-answer pairs that covered various aspects of the API functionality. Now in this article, we'll use that same dataset to fine-tune DeepSeek R1 8B, teaching it to accurately answer questions about Firecrawl.
Effect of dataset size over model performance
Before we dive into the code for fine-tuning DeepSeek R1, let's briefly discuss the effect of dataset size over model performance, which isn't always linear. Here are key insights:
-
Minimum viable size:
- Start with at least 1,000-2,000 examples
- Quality matters more than quantity
- Smaller, high-quality datasets often outperform larger, noisy ones
-
Diminishing returns:
- Performance improvements tend to plateau
- 10,000-50,000 examples is often sufficient
- Beyond this, focus on diversity and quality
-
Quality vs. quantity:
- A few hundred excellent examples > thousands of mediocre ones
- Balance between coverage and redundancy
- Consider computational costs of larger datasets
Remember: The optimal dataset size depends on your specific use case, available computing resources, and desired model performance.
The Tech Stack For Any Supervised LLM Fine-tuning Task
Let's explore the technical stack needed for implementing fine-tuning. This stack is versatile enough to be used for supervised fine-tuning of any language model.
-
unsloth: A library that optimizes LLM fine-tuning by reducing memory usage and training time. It provides QLoRA and other memory-efficient techniques out of the box. -
huggingface_hub: Enables seamless integration with Hugging Face's model hub for downloading pre-trained models and uploading fine-tuned ones. Essential for model sharing and versioning. -
datasets: Provides efficient data loading and preprocessing utilities. Handles large datasets through memory mapping and streaming, with built-in support for common ML dataset formats. -
transformers: The core library for working with transformer models. Offers model architectures, tokenizers, and training utilities with a unified API across different model types. -
trl: (Transformer Reinforcement Learning) Specializes in fine-tuning language models through techniques like supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF). -
torch: The deep learning framework that powers the training process. Provides tensor operations, automatic differentiation, and GPU acceleration essential for model training. -
wandb: (Weights & Biases) A powerful experiment tracking tool that monitors training metrics, visualizes results, and helps compare different training runs. Invaluable for debugging and optimization. -
accelerate: A library that simplifies distributed training across multiple GPUs and machines. It handles device placement, mixed precision training, and gradient synchronization automatically. -
bitsandbytes: Provides 8-bit optimizers and quantization methods to reduce model memory usage. Essential for training large models on consumer hardware through techniques like Int8 and FP8 quantization. -
peft: (Parameter-Efficient Fine-Tuning) Implements memory-efficient fine-tuning methods like LoRA, Prefix Tuning, and P-Tuning. Allows fine-tuning billion-parameter models on consumer GPUs by training only a small subset of parameters.
Let's examine how these libraries work together to enable LLM fine-tuning:
The process starts with PyTorch (torch) as the foundation - it provides the core tensor operations and automatic differentiation needed for neural network training. On top of this, the transformers library implements the actual model architectures and training logic specific to transformer models like DeepSeek.
When loading a pre-trained model, huggingface_hub handles downloading the weights and configuration files from Hugging Face's model repository. The model is then loaded into memory through transformers, while bitsandbytes applies quantization to reduce the memory footprint.
For efficient fine-tuning, peft implements parameter-efficient methods like LoRA that modify only a small subset of model weights. This works in conjunction with unsloth, which further optimizes memory usage and training speed through techniques like QLoRA.
The datasets library manages the training data, using memory mapping to efficiently handle large datasets without loading everything into RAM. It feeds batches of data to the training loop, where trl implements the supervised fine-tuning logic.
accelerate coordinates the training process across available hardware resources, managing device placement and mixed precision training. It works with PyTorch's built-in distributed training capabilities to enable multi-GPU training when available.
Throughout training, wandb tracks and visualizes metrics like loss and accuracy in real-time, storing this data for later analysis and comparison between different training runs.
This integrated stack allows you to fine-tune billion-parameter models on consumer hardware by:
- Loading and quantizing the base model efficiently
- Applying parameter-efficient fine-tuning techniques
- Managing training data and hardware resources
- Tracking training progress and results
Each component handles a specific aspect of the fine-tuning process while working seamlessly with the others through standardized APIs and data formats. As you continue with the tutorial, you will see most of these libraries used to fine-tune our own DeepSeek R1 model
Step-by-step Guide to Fine-tuning DeepSeek R1
Now that we have a high-level understanding of the tools we are going to use, let's see them in action to fine-tune DeepSeek.
1. Environment setup
Since our fine-tuning stack is popular, most of it is already installed inside Kaggle notebooks, which will be our choice of IDE since they provide 30 hours of access to high-quality P100 GPUs.
We only need to install unsloth:
!pip install -q unsloth
!pip install -q --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.gitThe first command installs the stable version from PyPI, while the second command force-installs the latest development version directly from GitHub to ensure we have the most up-to-date optimizations.
Next, add your HuggingFace and Weights & Biases tokens as environment secrets. These tokens allow you to authenticate with both services - HuggingFace for accessing and uploading models, and Weights & Biases for experiment tracking. You can find your HuggingFace token in your account settings under "Access Tokens", and your W&B token in your user settings under "API keys". Add these as environment variables named HF_TOKEN and WANDB_TOKEN respectively by going to "Add-ons" > "Secrets" inside your notebook.
Afterward, you can setup both services:
import wandb
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HF_TOKEN")
wb_token = user_secrets.get_secret("WANDB_TOKEN")
# Login to both services
login(hf_token)
wandb.login(key=wb_token)run = wandb.init(
project='fine-tune-deepseek-firecrawl',
job_type="training",
anonymous="allow"
)The run object represents our Weights & Biases experiment run. It will track metrics, hyperparameters, and artifacts throughout the training process. We set the project name to 'fine-tune-deepseek-firecrawl' to organize our experiments, specify this is a training job, and allow anonymous access so others can view our results. That is all the setup we need.
2. Loading the model and the tokenizer
import torch
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length=2048,
dtype=torch.bfloat16,
load_in_4bit=True,
token=hf_token
)This code loads a pre-trained DeepSeek model and tokenizer using FastLanguageModel. Let's break down the parameters:
The maximum sequence length of 2048 tokens defines how much context the model can process in a single forward pass, directly impacting both training and inference - longer sequences allow the model to learn from and generate more coherent text by considering more context, but also increase memory usage and training time, while shorter sequences may limit the model's ability to capture long-range dependencies but train faster and use less memory.
dtype=torch.bfloat16 uses bfloat16 precision, which reduces memory usage while maintaining numerical stability compared to full float32.
load_in_4bit=True enables 4-bit quantization, dramatically reducing the model's memory footprint with minimal performance impact. This is crucial for training on limited hardware.
token=hf_token passes our Hugging Face authentication token to access the model. This is required since we're using a gated model.
The model and tokenizer are returned as a tuple and stored in the respective variables for use in subsequent training steps. Let's quickly test the model by asking it a question about Firecrawl:
from transformers import TextStreamer
FastLanguageModel.for_inference(model)
prompt = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{}
### Response:
{}
"""
instruction = "How do I extract repo name, number of stars, repo link from the https://github.com/trending page using Firecrawl?"
message = prompt.format(instruction, "")
inputs = tokenizer([message], return_tensors="pt").to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer=text_streamer, max_new_tokens=512, use_cache=True)We first import TextStreamer for streaming the model's output token by token. FastLanguageModel.for_inference() prepares the model for inference mode.
A prompt template is defined that formats instructions and responses in a specific structure. The instruction asks about using Firecrawl with GitHub's trending page.
The prompt is formatted with the instruction and an empty response string. The tokenizer converts this text into model-readable tokens and moves them to the GPU. A TextStreamer instance is created to handle streaming output.
Finally, model.generate() is called with the tokenized input to produce the response. max_new_tokens=512 limits the response length, and use_cache=True enables caching for faster generation. Here is the output
To extract the repository name, star count, and GitHub link from the GitHub Trends page using Firecrawl, you can follow these steps:
1. **Open Firecrawl**: Start by launching the Firecrawl browser extension.
2. **Navigate to GitHub Trends**: Go to the URL https://github.com/trending.
3. **Inspect Element**: Once the page loads, click the Firecrawl icon (the small orange and white火火火 icon) located in your web browser's toolbar. This will open the Firecrawl interface...As you can see, the model generated a totally fabricated response (it thinks Firecrawl is a browser extension), which effectively proves that it doesn't have prior knowledge of the tool.
Let's switch the model back to training mode before moving on:
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length=2048,
dtype=torch.bfloat16,
load_in_4bit=True,
token=hf_token
)3. Preprocessing a dataset
Now, let's load and preprocess our custom Firecrawl dataset uploaded to HuggingFace in our previous article:
from datasets import load_dataset
dataset_name = "bexgboost/firecrawl-instructions"
dataset = load_dataset(
dataset_name, split = "train[0:500]", trust_remote_code=True
)The custom firecrawl-instructions dataset contains over 6k examples, which would be too large a size to process in a Kaggle session. That's why we are only loading the first 500 examples.
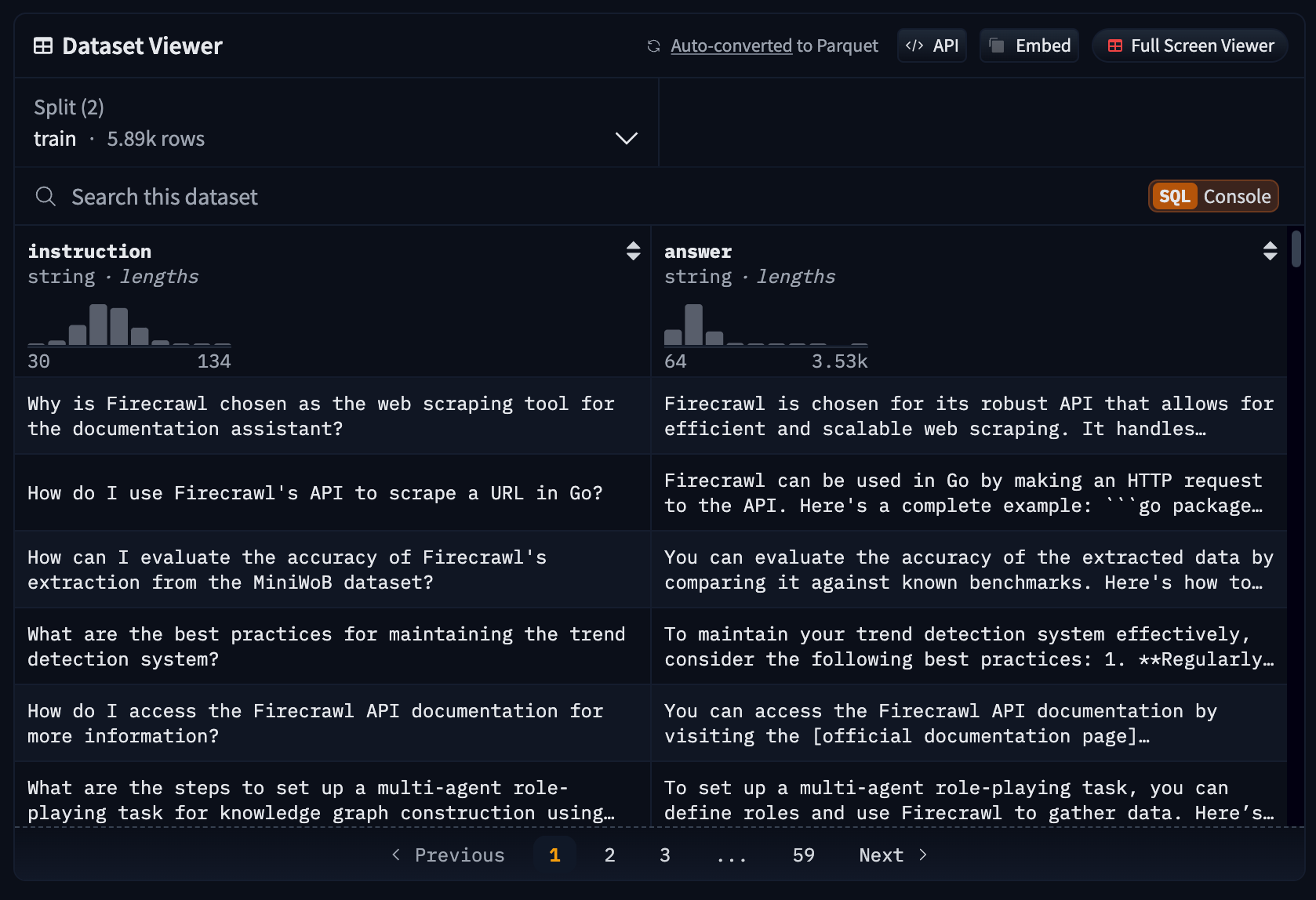
Caption: Screenshot of the data card of the custom Firecrawl instructions dataset.
Notice how the dataset only contains two columns for the instruction and the answer. To fine-tune reasoning models like DeepSeek R1 (distilled versions as well), the datasets should have one more column for the chain-of-thought:
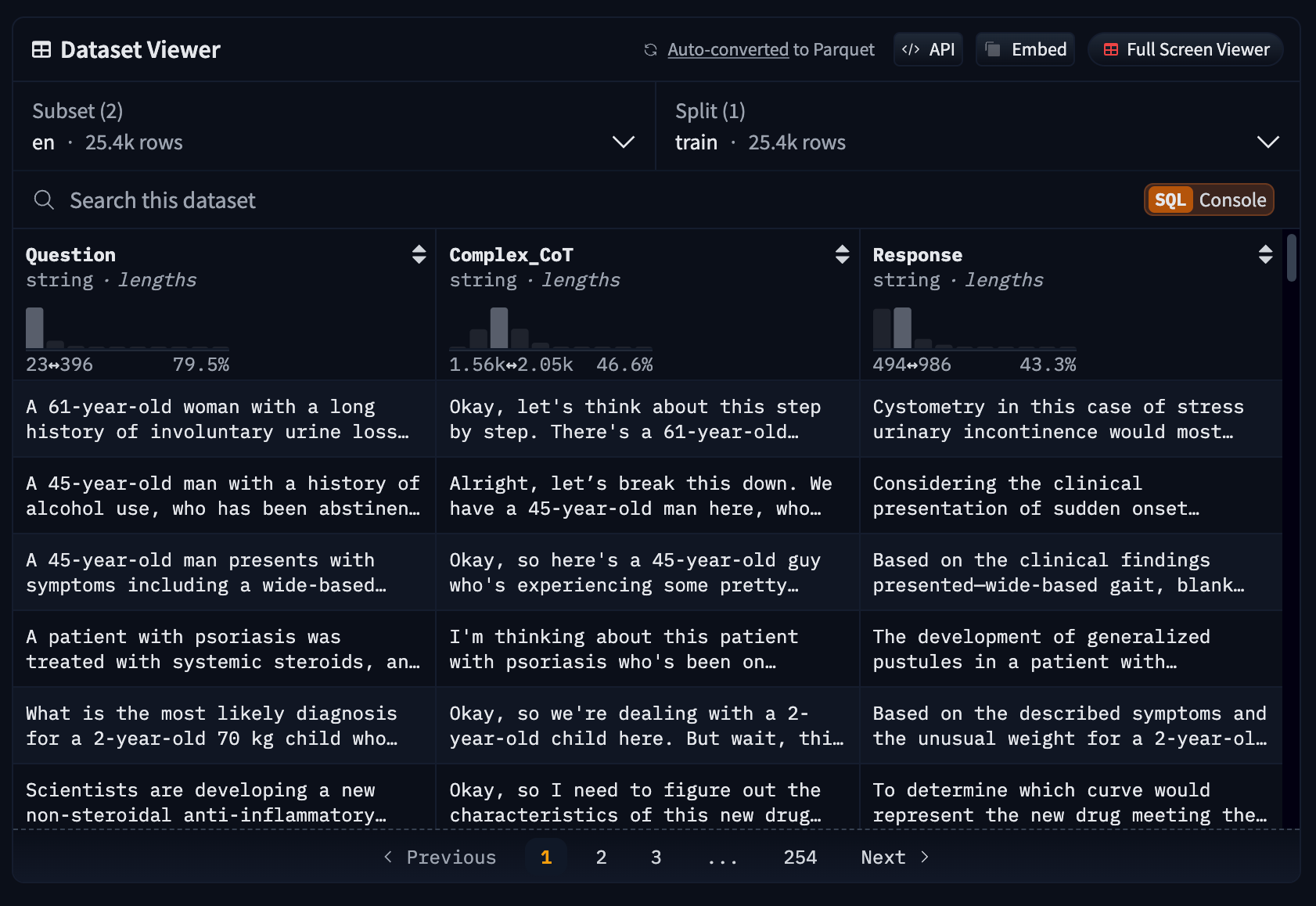
Chain-of-thought reasoning is a critical component for training models to develop better reasoning capabilities. However, since we're focusing on demonstrating the fine-tuning process in this example, we'll proceed with our simplified dataset that only contains instructions and answers. In a production environment, you would want to generate the chain-of-thought part and include it to achieve optimal model performance (this requires even more preparation, effort and training resources).
After loading the dataset, we need to convert its every sample into a suitable training prompt:
EOS_TOKEN = tokenizer.eos_token
def format_instruction(example):
prompt = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a web scraping expert with advanced knowledge in Firecrawl, which is an AI-based web-scraping engine.
Please answer the following question about Firecrawl.
### Question:
{}
### Response:
{}"""
return {
"text": prompt.format(example['instruction'], example['answer']) + EOS_TOKEN
}
dataset = dataset.map(format_instruction)The code demonstrates our dataset formatting process for training. We define an EOS_TOKEN from our tokenizer to mark sequence endings, then create a format_instruction() function that transforms each example into a structured prompt. The prompt template includes clear sections for question, and responses, with specific context about Firecrawl. Using dataset.map(), we apply this formatting across our entire dataset, preparing it for the fine-tuning process. Our dataset is now ready for fine-tuning.
4. Setting up the SFFTrainer
Now that we have our dataset prepared, let's set up the SFFTrainer for fine-tuning. The SFFTrainer is a specialized trainer that implements efficient fine-tuning techniques. We'll configure it with optimal parameters for our use case.
First, we configure the PEFT model with LoRA parameters, specifying target modules and hyperparameters for efficient fine-tuning.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=1000,
use_rslora=False,
loftq_config=None,
)The code above configures Parameter Efficient Fine-Tuning (PEFT) with Low-Rank Adaptation (LoRA) for training our AI model. This method allows us to efficiently update only specific parts of the model while preserving its existing knowledge. LoRA achieves this by introducing small trainable matrices into key model components. This approach significantly reduces memory usage and accelerates the training process compared to traditional fine-tuning methods.
Key parameters explained:
-
r=16: The rank of the LoRA decomposition matrices. Higher values (e.g. 32, 64) increase model capacity and expressiveness but require more memory and compute. Lower values (e.g. 4, 8) are more memory efficient but may limit learning. 16 provides a good balance for most use cases. -
target_modules: The list of transformer layer components that LoRA will be applied to. This includes attention mechanism components (query, key, value, and output projections) and feed-forward network components (gate, up, and down projections). By targeting these specific modules, we can efficiently update the most important parts of the model while keeping other parameters frozen. The attention components control how the model processes relationships between different parts of the input, while the feed-forward components handle intermediate representations. -
lora_alpha=16: Scaling factor for LoRA updates, controlling their impact on the model -
lora_dropout=0: No dropout applied to LoRA layers to maximize learning
lora_alpha controls how strongly LoRA updates affect the model's behavior. Setting it equal to the rank provides balanced scaling of the modifications during training.
lora_dropout=0 disables dropout regularization on LoRA layers, allowing full use of all parameters during training to maximize learning capacity from the training data.
bias="none": No bias parameters are trained, focusing on weight updatesuse_gradient_checkpointing="unsloth": Enables memory-efficient training for long sequencesuse_rslora=False: Disables rank-stabilized LoRA variantloftq_config=None: No low-rank fine-tuning with quantization configuration
This configuration optimizes for efficient training while maintaining model quality, reducing memory usage and training time compared to full fine-tuning.
Next, we configure the training arguments that control the training process. These settings determine important aspects like batch size, learning rate, and optimization parameters.
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
model_name = "firecrawl-assistant"
local_path = f"./models/{model_name}"
training_arguments = TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=100,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=1000,
output_dir=local_path,
push_to_hub=True,
hub_model_id=f"bexgboost/{model_name}",
report_to="wandb",
)The training arguments configure key training parameters:
- A batch size of 2 samples per device is used, with gradient accumulation over 4 steps to simulate larger batches
- The learning rate starts at 2e-4 and follows a linear schedule with 5 warmup steps
- Training runs for 100 steps total
- Mixed precision training is enabled using either FP16 or BF16 depending on hardware support
- The AdamW 8-bit optimizer is used with 0.01 weight decay for regularization
- Progress is logged every 10 steps and outputs are saved to the
local_pathdirectory - The model is pushed to HuggingFace hub after training
- The training process is tracked with W & B
Note that for this demonstration, we are training for a fixed number of steps rather than full epochs to save time. In production, you should use num_train_epochs to train for complete passes through the dataset, along with warmup_ratio instead of warmup_steps and max_steps to scale the warmup period proportionally. This ensures proper model convergence and generalization on your full dataset.
Next, we set up the Supervised Fine-Tuning (SFT) trainer that will handle the training process.
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=2048,
dataset_num_proc=2,
args=training_arguments,
)The SFTTrainer brings together all the components needed for training:
- It takes our configured model and tokenizer
- The training dataset is provided, with "text" specified as the field containing the training examples
- The maximum sequence length limits input size
- 2 processes are used for dataset preprocessing
- The training arguments we configured earlier control the training process
5. Model training and testing
Now, all we have to do is call the train method of the trainer:
trainer.train()The training process may take up to an hour to finish. Once it is done, you can see the training loss on W & B dashboard. Note that since we used very few training steps (instead of full epochs), our model performance won't be optimal and may hallucinate. With that said, let's test it quickly on the first prompt we tried, which the model hallucinated badly:
FastLanguageModel.for_inference(model)
inputs = tokenizer([message], return_tensors="pt").to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer=text_streamer, max_new_tokens=512, use_cache=True)Here is the answer generated by our fine-tuned model:
You can extract the repo name, number of stars, and repo link from the GitHub trending page by using Firecrawl's `scrape_url` method with the appropriate selectors. Here’s an example:
```python
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key='your_api_key')
# Scrape GitHub's trending page for repo details
response = app.scrape_url('https://github.com/trending', {
'formats': ['html'],
'selectors': {
'repo_name': '.repo-name',
'stars': '.stars',
'repo_link': '.repo-link'
}
})
# Print the extracted data
print("Repo Name:", response['repo_name'])
print("Stars:", response['stars'])
print("Repo Link:", response['repo_link'])This response is actually better than I expected given how we only trained for 100 steps. The model now correctly recognizes Firecrawl as a scraping engine and it correctly determined the right scraping method - scrape_url. However, after the part about formats, it hallucinated and generated incorrect code.
But this is promising since the training loss has been rapidly decreasing, suggesting that there is much room for improvement:
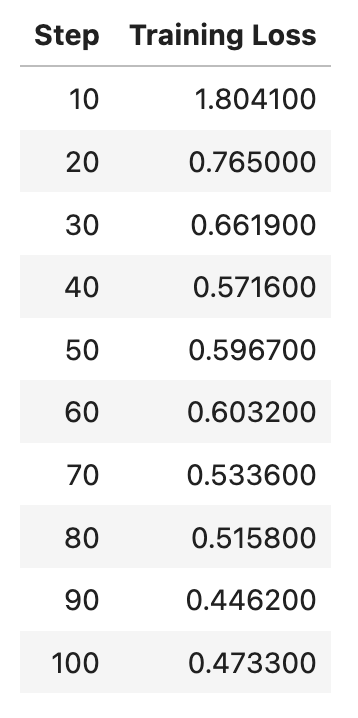
Just a note that here is the correct code for scraping the GitHub trending pages:
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key='your_api_key')
# Scrape GitHub trending page
response = app.scrape_url('https://github.com/trending', {
'formats': ['extract'],
'extract': {
'prompt': """Extract all trending repositories with their:
- Repository name (in owner/repo format)
- Number of stars
- Repository URL
Return as a list of objects."""
}
})
# The extracted data will be in response['extract']
trending_repos = response['extract']As you can see, you only have to provide a natural language prompt to scrape the necessary fields from a webpage using Firecrawl. For more information, check out our complete scraping guide.
6. Saving and uploading the model
Finally, we can save the model locally and upload it to HuggingFace with a couple lines of code:
trainer.save_model(local_path)
trainer.push_to_hub()
# Close W&B run
wandb.finish()Building a Chat UI For the Fine-tuned Model
Conclusion
In this guide, we've walked through the complete process of fine-tuning a language model for a specific domain using modern tools and techniques. We used Firecrawl's documentation dataset to demonstrate how to efficiently train a model that can accurately answer questions about API functionality, endpoints, and best practices. The combination of Unsloth's optimizations, HuggingFace's ecosystem, and Weights & Biases tracking made it possible to fine-tune a large language model on consumer hardware while monitoring the training process.
The resulting chatbot application showcases how fine-tuned models can be deployed locally to solve real-world problems. By loading the model directly from HuggingFace Hub and creating a user-friendly interface with Streamlit, we've demonstrated that running custom language models doesn't have to be complex. This same approach can be adapted for any domain-specific application where you need an AI assistant trained on your own documentation or knowledge base.
