Introduction
It is amazing how times are changing. What used to take hours of tab switching, swearing and frustration can now be done in a few minutes with OpenAI's Deep Research. The caveat is that this pro feature costs $200 a month, which is a deal breaker for most people who want to occasionally deep dive into topics but can't justify the steep price tag.
That's why we've built Open Deep Research, a self-hostable alternative that brings the power of AI-driven research to everyone. By combining real-time web scraping with advanced language models, we've created a tool that matches the capabilities of OpenAI's Deep Research while being much more cost-effective and accessible. While it uses some paid services like Firecrawl and OpenAI's models, the core application code is open source and can be customized to work with different providers.
In this article, we'll explore the core concepts behind the app, walk through the key architectural choices, and demonstrate its practical applications. By following along, you'll learn how to construct an AI-powered research platform, connect it with external data extraction services, and develop performant server-side code for processing large computational workloads.
Running the App Locally
Let's start with instructions on how to run the app locally on your computer since it is the best way to get a feel of the application before you start wondering what makes each part tick. Even though the app's GitHub repo provides brief info on how to set it up with Vercel, it doesn't mention running it fully locally without Vercel.
First, make sure that you have these tools installed:
-
Node.js: You can download it from nodejs.org. The project uses Node.js 20, so ensure your version is compatible.
-
pnpm: This project uses
pnpmas the package manager. You can install it globally using npm:npm install -g pnpm -
Docker: Docker is required to run the necessary services like Postgres and Redis. You can download Docker from docker.com.
-
Vercel CLI: This is highly optional but recommended for managing environment variables and deployments (you only have to use it when you want to deploy the application). Install it globally:
npm install -g vercel
Step-by-Step Instructions
- Clone the Repository
First, clone the repository to your local machine:
git clone https://github.com/nickscamara/open-deep-research.git
cd open-deep-research- Set Up Environment Variables
Copy the example environment file and configure your environment variables:
cp .env.example .envEdit the .env file to include these essential API keys and other necessary configurations:
# Absolutely required keys
OPENAI_API_KEY="sk-proj-..."
FIRECRAWL_API_KEY="fc-..."
AUTH_SECRET="..."
# Keep these as-is
POSTGRES_URL=postgres://postgres:postgres@localhost:5432/open_deep_research
BLOB_READ_WRITE_TOKEN="minioadmin"
UPSTASH_REDIS_REST_URL="http://localhost:6379"
UPSTASH_REDIS_REST_TOKEN="local_development_token"
MAX_DURATION=60
# Optional if you want to use DeepSeek R1
TOGETHER_API_KEY="767fd02e6dcf0aa59ecca457b4b29bd6bdc706a852bb7d3a89e69c47f12a88f2"The .env.example file has instructions on where to get keys for OpenAI, Firecrawl and AUTH_SECRET. You can keep the database-related variables as-is as we are running things locally.
- Install Dependencies
Use pnpm to install the project dependencies:
pnpm install- Run Database Migrations
Execute the database migrations to set up your database schema:
pnpm db:migrate- Start Docker Services
Use Docker Compose to start the necessary services (Postgres, Redis, Minio):
docker-compose up -dThis will start the services in the background. Ensure that Docker is running and the services are healthy.
- Run the Application
Start the application in development mode:
pnpm devYour application should now be running on http://localhost:3000.
- Access the Application
Open your browser and navigate to http://localhost:3000 to access the application.
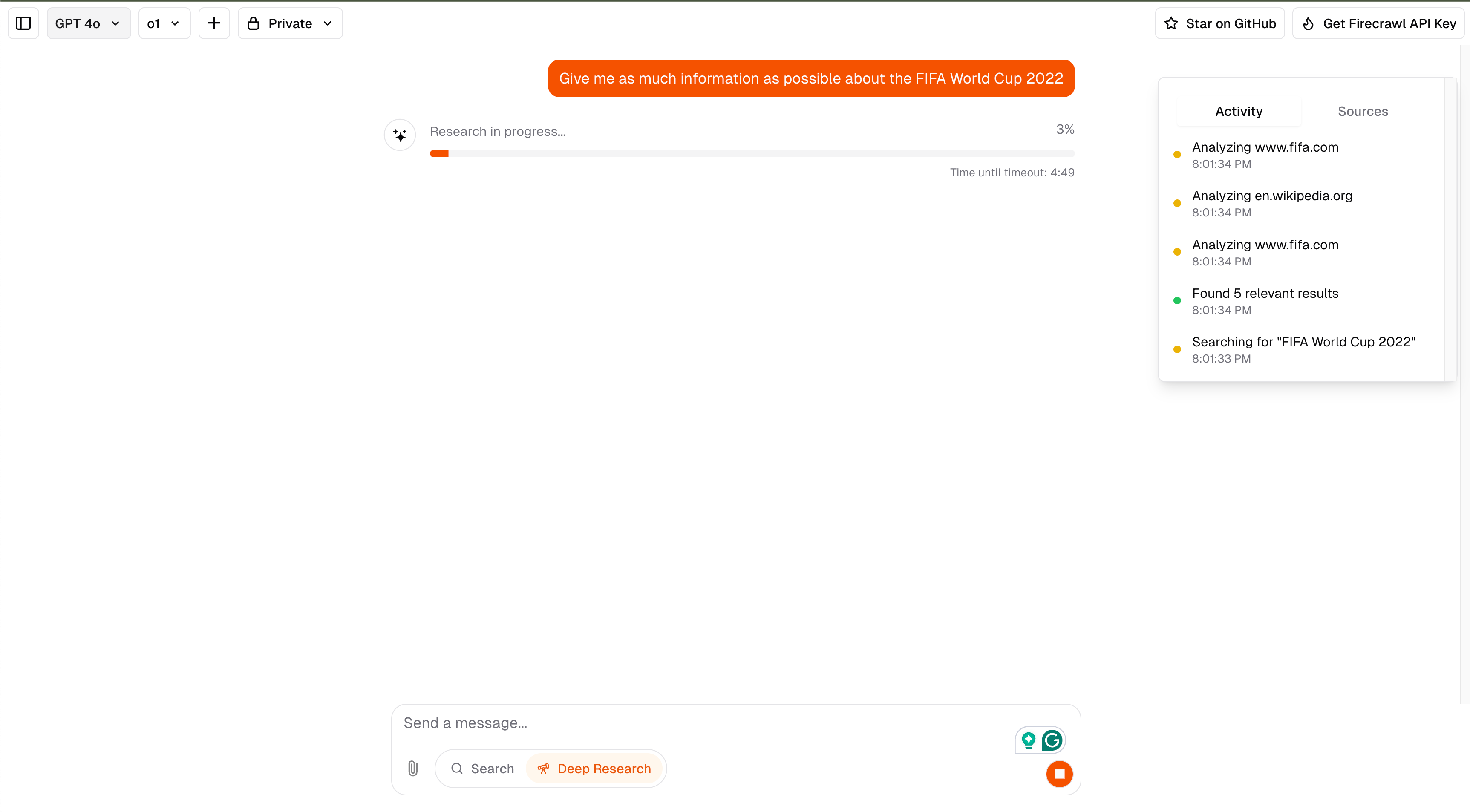
Additional Notes
- Docker Health Checks: Ensure that the Docker services are healthy before running the application. You can check the status with:
docker-compose ps- Troubleshooting: If you encounter any issues, check the logs for each service using:
docker-compose logs <service_name>This should cover all the necessary steps to get the application running locally. If you have any specific questions or run into issues, feel free to open an issue on GitHub.
2. The Tech Stack Used in the App
If you have tried the app with a few queries, it is time to get a general overview of the technologies that power its various components. Let's break them down.
Next.js App Router
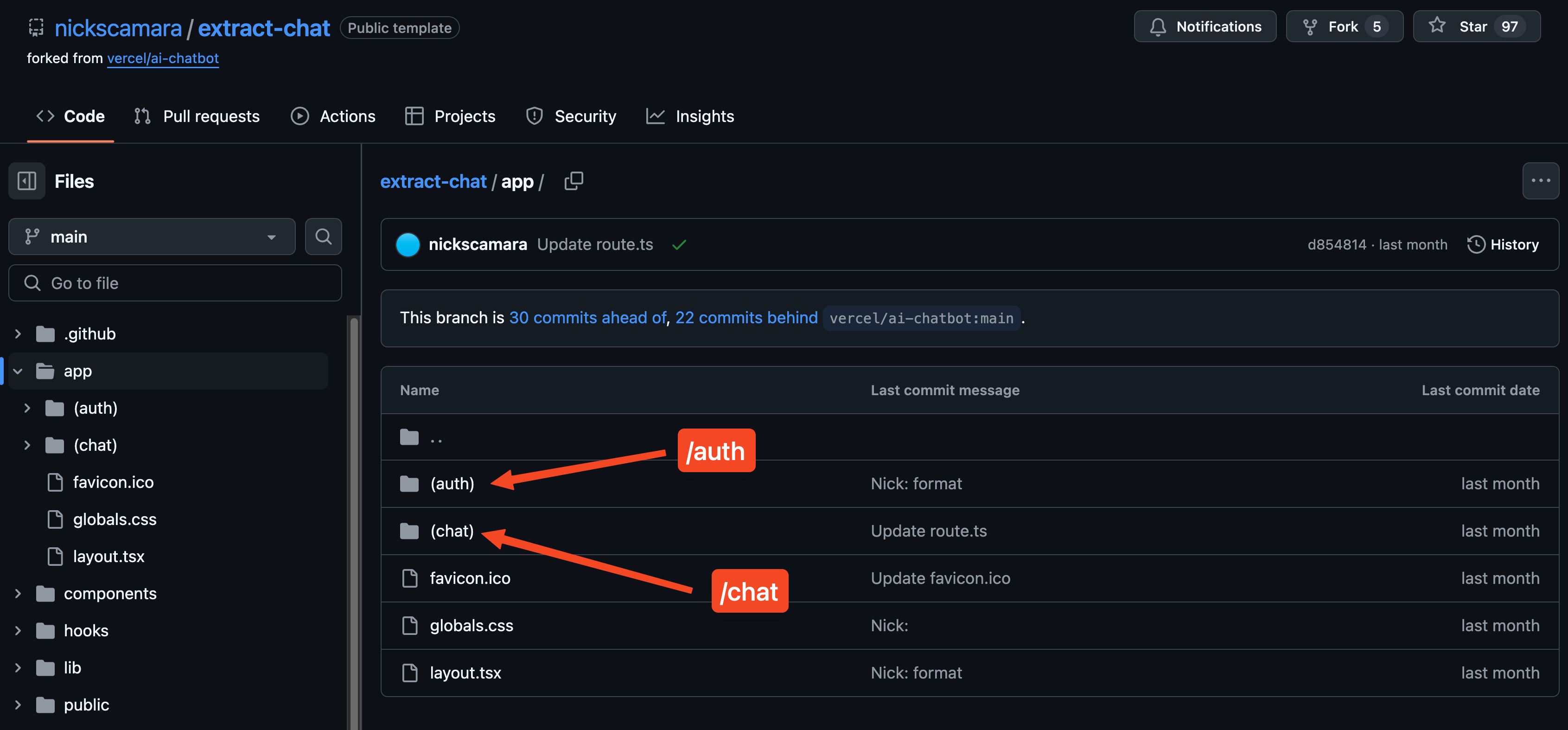
Next.js serves as the core framework powering our application, seamlessly handling both client-side browser interactions and server-side operations. Its App Router feature enables us to organize our code in a way that naturally mirrors the website's structure, with routes like /chat and /auth corresponding directly to their respective folders in our codebase. This intuitive organization makes it easy to manage complex features like real-time messaging, user authentication, and research tools. Additionally, the App Router intelligently splits our code into smaller chunks, delivering only the necessary code to users as they navigate through different pages.
Server-side rendering is one of the most powerful features we use, where Next.js generates web pages on our servers before sending them to users' browsers. This approach makes our application faster because users don't have to wait for JavaScript to load and run before seeing content, while also helping search engines better understand our content - crucial for visibility. We use this feature extensively in our research results pages, where we pre-render complex data visualizations and research findings server-side for immediate viewing.
When evaluating frameworks, we chose Next.js over alternatives like SvelteKit or Remix because it offers the best balance of developer experience, performance, and enterprise-ready features. Its built-in support for React Server Components, automatic code splitting, and image optimization means we can focus on building features rather than configuration. The large ecosystem of compatible tools and extensive documentation also made it the most practical choice for a production application.
Tailwind CSS & UI Components
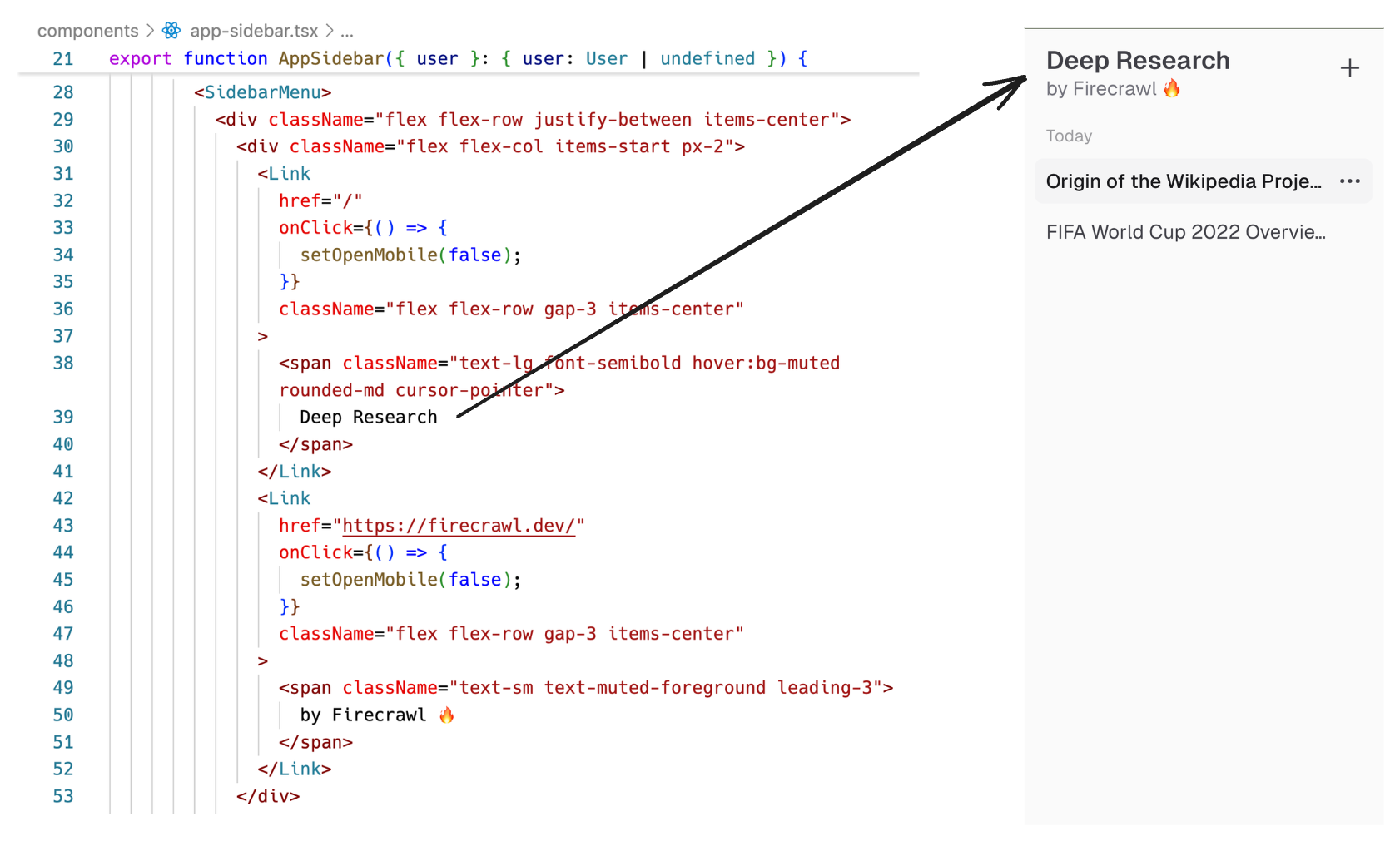
The visual design system leverages Tailwind CSS's utility-first approach, which elegantly styles components throughout the application. Building on this foundation, we integrate shadcn/ui and Radix UI primitives to create accessible components like tooltips, dialogs, and dropdowns. A prime example of this integration is our app sidebar, which features a responsive navigation menu with seamless tooltips and dropdown functionality:
When comparing UI frameworks, this combination stood out against alternatives like Material UI or Chakra UI. Tailwind CSS enables rapid development while maintaining full customization control, and Radix UI delivers production-ready accessibility features that would otherwise require significant development time. Together, they form a cohesive system that maintains consistent design and accessibility standards with minimal complexity. The integrated ThemeProvider makes it effortless to implement the light and dark modes that modern users have come to expect.
AI SDK Integration
The AI SDK serves as the core of our AI functionality through its chat route handler implementation. Through a unified interface, the SDK enables working with different AI models via functions like streamText and generateObject, which power our real-time chat responses and structured data generation. Our route handler seamlessly handles model configuration, authentication, and streaming responses. For frontend components, the SDK provides React hooks such as useChat that elegantly manage chat state and real-time updates.
By simply changing environment variables, the SDK makes it effortless to switch between AI providers like OpenAI and Together AI while maintaining consistent functionality. We initialize different reasoning models using customModel. The SDK's streaming capabilities play a crucial role in our deep research feature, coordinating multiple AI calls to search, extract, and analyze web content in real-time while keeping users informed through interface updates.
For those new to Vercel's AI SDK, the introduction from the documentation provides an excellent overview. When comparing it to alternatives like LangChain or LlamaIndex, we found its streamlined, focused API integrates naturally with Next.js while delivering powerful streaming capabilities and type safety. The SDK's lightweight design results in faster deployments with minimal overhead, and its seamless integration with Vercel's infrastructure makes scaling and monitoring in production environments straightforward.
Database & Storage Architecture
The application's data flows through two complementary storage systems. At its core, Postgres handles structured data through schema definitions and migrations, which are managed by Drizzle ORM. Different types of data follow distinct paths: structured information like user profiles and chat logs resides in Postgres, while Vercel Blob stores binary content such as uploaded files and images.
Within this dual-system approach, database connections, schema definitions, and migrations work together seamlessly. As users upload files, the blob storage component processes them and generates secure URLs, ensuring reliable access. This separation allows each storage type to operate according to its strengths - Postgres handles complex queries for structured data, while Blob storage manages large media files efficiently.
When evaluating alternatives like MongoDB and Firebase, this architecture emerged as the most suitable solution. Postgres provides the necessary ACID compliance and querying capabilities for structured data requirements, while Vercel Blob integrates naturally with Next.js and delivers optimized file storage performance. Together, they offer comprehensive storage solutions without the complexity of managing a monolithic database system.
Authentication System
The authentication system is built on NextAuth.js, which provides essential capabilities like route protection middleware, API handlers for authentication flows, and session management utilities. User data and authentication details are stored securely in our database.
Users can begin exploring the application immediately through an anonymous session feature, without needing to create an account first. While Upstash Redis handles rate limiting to prevent abuse, Vercel Postgres serves as the session persistence layer for storing data. When users decide to create a permanent account, their chat history and preferences seamlessly carry over.
Among authentication solutions like Passport.js and custom implementations, NextAuth.js emerged as a practical choice due to its integration with Next.js and support for multiple authentication providers. Its ability to handle both anonymous sessions and social logins with minimal setup allows for a straightforward implementation while maintaining strong security standards.
Web Scraping & Search with Firecrawl
One of the key pieces of the puzzle was using Firecrawl for web search and scraping. Specifically, we used its search, extract and scrapeUrl methods for distinct purposes:
searchis used to find the initial list of URLs that may contain the information the user is looking for. Think of it like Google search but through Firecrawl. Here is how you can use the endpoint standalone in your projects:
import FirecrawlApp from "@mendable/firecrawl-js";
const app = new FirecrawlApp({ apiKey: "your-fc-api-key" });
const searchResult = app.search("your-query");searchResult will contain pages along with their metadata that matches your query.
scrapeUrlis used to convert a webpage's content into various LLM-friendly formats like HTML or Markdown. Here is how you can try it:
const scrapeResult = await app.scrapeUrl("firecrawl.dev", {
formats: ["markdown", "html"],
});
if (!scrapeResult.success) {
throw new Error(`Failed to scrape: ${scrapeResult.error}`);
}
console.log(scrapeResult);extractis used to scrape structured data from web pages (instead of converting the entire page) by using natural language, which is just what we want for our application. For instance, below you can see the extract endpoint being used to scrape multiple URLs for specific pieces of information defined in a Zod object:
import FirecrawlApp from "@mendable/firecrawl-js";
import { z } from "zod";
const app = new FirecrawlApp({
apiKey: "fc-YOUR_API_KEY",
});
// Define schema to extract contents into
const schema = z.object({
company_mission: z.string(),
supports_sso: z.boolean(),
is_open_source: z.boolean(),
is_in_yc: z.boolean(),
});
const scrapeResult = await app.extract(
[
"https://docs.firecrawl.dev/*",
"https://firecrawl.dev/",
"https://www.ycombinator.com/companies/",
],
{
prompt:
"Extract the company mission, whether it supports SSO, whether it is open source, and whether it is in Y Combinator from the page.",
schema: schema,
},
);
if (!scrapeResult.success) {
throw new Error(`Failed to scrape: ${scrapeResult.error}`);
}
console.log(scrapeResult.data);Without this AI-powered tool, the project would not have been possible as traditional web scraping would require us build a separate scraper for each web page - an impossible feat since we are building a deep research tool. To learn more about Firecrawl and its features, check out our documentation and blog.
Each of these technologies was chosen to solve specific problems while working together as a cohesive system. The Next.js foundation allows all these tools to integrate smoothly, while the AI SDK provides the core functionality that makes the deep research features possible. This tech stack enables the application to handle complex AI operations while providing a smooth, responsive user experience.
3. High-Level Architecture
The architecture of the Open Deep Research application balances complex AI-driven research tasks with a seamless user experience. Through distinct layers handling specific functionalities, the system maintains modularity and scalability while ensuring clear separation of concerns. Modern web technologies and AI capabilities form the foundation of this robust platform for AI-driven research.
Frontend
Built on React components within the Next.js framework, the frontend delivers a highly interactive and accessible user interface. Tailwind CSS and Radix UI primitives maintain consistent design patterns and accessibility standards, while Framer Motion adds smooth animations that provide visual feedback for user interactions. Various components work together to create different parts of the interface, from chat windows to toolbars and research panels.
A modular approach to frontend architecture allows each component to encapsulate its own logic and styling, making updates and maintenance straightforward. The combination of utility-first CSS through Tailwind enables quick development cycles, complemented by Radix UI's pre-built accessible components. Framer Motion's animations integrate naturally to create fluid, responsive interactions throughout the interface.
Backend
API routes form the core of the backend, managing incoming requests, user authentication, and AI responses. Integration with the AI SDK enables real-time chat interactions and data processing, orchestrating the flow between frontend interfaces and AI models. This setup facilitates complex operations while maintaining consistent response delivery.
With scalability and efficiency in mind, the backend architecture handles high request volumes through well-structured API routes. Each route maintains a specific focus, contributing to the application's overall functionality. The AI SDK provides a unified interface for different AI models, allowing seamless provider switching while maintaining consistent behavior across the system.
Real-Time Chat Flow
At the heart of user interaction lies the real-time chat flow, powered by the AI SDK's streaming capabilities. Messages appear token by token, creating an immediate feedback loop through a live type-out effect. Server-side logic works in concert with client-side hooks to process and display messages as they arrive.
The chat system prioritizes low latency and high throughput, efficiently managing large data volumes through streaming responses. Client-side hooks maintain chat state and handle updates in real-time, ensuring responsive performance even during peak usage. This immediate interaction model helps users stay engaged throughout their research sessions.
Deep Research Engine
The deep research engine coordinates with external services like Firecrawl to search, extract, and analyze web content comprehensively. Through automated agent logic, it orchestrates multiple AI calls to perform complex research tasks efficiently. This process involves searching for relevant information, extracting data from promising URLs, analyzing content, and synthesizing detailed reports.
Designed for adaptability, the deep research engine adjusts its approach based on different research scenarios. The automated logic refines search and extraction strategies as it processes data, enabling thorough exploration of diverse research topics. This flexible architecture supports the range of research tasks users need to accomplish, from quick fact-finding to in-depth analytical studies.
The Process Under the Hood
Now that we have a high-level picture of the app's components, let's examine what happens under the hood from the moment a user enters a prompt and selects a tool, to when the AI model's response is streamed back to the user:
-
User Interaction
- Prompt Entry: The user types a message or question into the chat interface.
- Tool Selection: The user selects either "search" or "deep research" as the tool to use for processing their query.
- Submission: The user hits enter, triggering the client-side application to prepare a request.
- Model selection: User has the option to choose the reasoning model as well as the response generation model from the top left of the UI.
-
Client-Side Request Handling
- Data Packaging: The client-side application packages the user's message, selected tool, and any additional settings into a POST request.
- API Call: This request is sent to the
/api/chatendpoint on the server.
-
Server-Side Processing
- Authentication: The server first authenticates the user using session data. If the user is not authenticated, it may create an anonymous session.
- Database Query: The server queries the database to retrieve any relevant user context or previous interactions that might inform the current session.
- Tool Invocation: Based on the selected tool, the server invokes the appropriate process:
- Search: Initiates a simple search operation using Firecrawl to gather relevant web data.
- Deep Research: Engages a more complex process involving multiple steps:
- Search: Uses Firecrawl to perform an initial search for relevant web pages.
- Scrape: Extracts data from the top URLs identified in the search.
- Analyze: Processes the extracted data to generate insights or summaries.
- Iterate: Repeats the search, scrape, and analyze steps as needed, refining the results until the AI model decides it has enough information to answer user's query.
-
AI Model Interaction
- Model Configuration: The server configures the AI model with the necessary parameters, including the user's query and any contextual data.
- Response Generation: The AI model begins generating a response, which is processed in a streaming manner.
-
Response Streaming
- Chunked Data: The AI model's response is streamed back to the client in chunks, allowing for real-time updates.
- Data Handling: The server manages the data stream, ensuring that each chunk is correctly formatted and sent to the client.
-
Client-Side Response Handling
- Real-Time Updates: The client receives the streamed data and updates the UI in real-time, displaying the AI model's response as it arrives.
- UI Rendering: The chat interface dynamically renders each new piece of information, creating a live type-out effect for the user.
-
Storage & Persistence
- Data Persistence: The server persists the chat history and any relevant data in the Postgres database or Vercel Blob storage, depending on the data type.
- Session Management: The client periodically re-fetches the updated conversation history to ensure continuity in the user experience.
- Chat Management: All chats are displayed in the sidebar with controls for deleting or renaming the chats.
This detailed process ensures that the application efficiently handles user queries, uses AI capabilities for deep research, and provides a seamless, interactive experience for the user.
Conclusion
In conclusion, this project showcases how modern web technologies work together seamlessly to create a powerful AI chatbot application. Next.js serves as the foundation by providing robust routing and server components, while Tailwind streamlines UI development through consistent styling. Building on this base, the Vercel AI SDK enables real-time streaming and message management, and Firecrawl enhances the system with advanced web scraping capabilities. The result is a modular architecture that can be readily extended with new features and integrations.
For those interested in contributing to this project, here are some potential areas for improvement:
-
Performance Optimization
- Implement caching strategies for frequently accessed data
- Add request batching for API calls
- Optimize large component re-renders
-
Enhanced Testing
- Expand unit test coverage
- Add integration tests for core workflows
- Implement end-to-end testing with Cypress
-
Additional Features
- Collaborative real-time editing
- Advanced visualization of AI reasoning steps
- Custom plugin system for extensions
-
Documentation
- Add detailed API documentation
- Create contribution guidelines
- Include more code examples and tutorials
-
Security Enhancements
- Implement rate limiting
- Add input sanitization
- Enhanced error handling
Feel free to open issues or submit pull requests for any of these improvements or your own ideas. Thank you for reading!
If you'd like to explore more options, check out our guide on 5 Best Deep Research APIs for Agentic Workflows.

data from the web