Introduction
Conducting thorough web research is a time-consuming process that often involves jumping between multiple websites, cross-referencing information, and trying to synthesize findings into a coherent understanding. Traditional search engines return lists of links rather than comprehensive answers, leaving users to do the heavy lifting of extracting and connecting information. As demonstrated in the video above, our open-source deep research application aims to solve this problem by automating the research process.
The application uses Firecrawl's deep research endpoint to actively explore the web, following relevant links and gathering information across multiple sources. Unlike standard search tools, it doesn't just find information—it synthesizes it into comprehensive, well-structured answers with proper source citations. Built with Streamlit and Python, this tool provides a more affordable alternative to premium AI research services like OpenAI's Advanced Data Analysis ($200/month subscription), while offering similar functionality for complex research tasks. In this article, we'll walk through how to build this application step by step, from integrating the Firecrawl API to creating an intuitive user interface that displays real-time research progress.
Understanding the Deep Research Endpoint
Traditional web research presents numerous challenges as highlighted earlier. To address these limitations, Firecrawl introduces its deep research endpoint - a powerful solution specifically designed for comprehensive information gathering and synthesis. This AI-powered research API fundamentally transforms how applications gather and synthesize web information. Unlike traditional search engines that simply return a list of links, this endpoint actively explores the web to build comprehensive answers to complex queries. The system works through a multi-step process: first analyzing your query to identify key research areas, then iteratively searching and exploring relevant web content, synthesizing information from multiple sources, and finally providing structured findings with proper source attribution.
What makes this endpoint particularly powerful is its ability to autonomously navigate between sources, following contextual threads to build a complete picture of a topic. The research process provides not just final answers but also detailed activity logs showing how the information was gathered, creating transparency that's missing from typical AI responses. All research is returned with source citations, allowing users to verify information and explore topics further. The system is configurable through parameters that control research depth, time limits, and the maximum number of URLs analyzed. Implementing the deep research endpoint in your application is straightforward with the Firecrawl Python library. Here's a simple example that demonstrates the core functionality:
from firecrawl import FirecrawlApp
# Initialize the client
firecrawl = FirecrawlApp(api_key="your-api-key")
# Define research parameters
params = {
"maxDepth": 3, # Number of research iterations
"timeLimit": 180, # Time limit in seconds
"maxUrls": 10 # Maximum URLs to analyze
}
# Set up a callback for real-time updates
def on_activity(activity):
print(f"[{activity['type']}] {activity['message']}")
# Run deep research
results = firecrawl.deep_research(
query="What are the latest developments in programming memes?",
params=params,
on_activity=on_activity
)
# Access research findings
print(f"Final Analysis: {results['data']['finalAnalysis']}")
print(f"Sources: {len(results['data']['sources'])} references")[search] Generating deeper search queries for "What are the latest developments in programming memes?"
[search] Starting 3 parallel searches for "What are the latest developments in programming memes?"
[search] Searching for "popular programming memes and their origins" - Goal: To identify and analyze the most popular programming memes and trace their origins and evolution.
[search] Found 15 new relevant results across 3 parallel queries
[analyze] Analyzing findings and planning next steps
[analyze] Analyzed findings
[synthesis] Preparing final analysis
[synthesis] Research completed
Final Analysis: # Research Report: Latest Developments in Programming Memes
## Introduction
Programming memes have become a significant part of the developer culture, serving as a humorous outlet for the challenges and quirks of coding. As of 2025, the landscape of programming memes has evolved, reflecting changes in technology, programming languages, and the developer community's sentiments. This report explores the latest developments in programming memes, analyzing current trends, popular themes, and their impact on the community...In this example, we initialize the Firecrawl client with an API key, configure research parameters to control the scope and duration of the research, and set up a callback function to receive real-time updates as the research progresses. The deep_research method initiates the research process with our quantum computing query, and the results contain both the synthesized analysis and a list of sources that were consulted. This foundation of research capabilities will be the core of our Streamlit application, which we'll build throughout this article. Next, we'll look at the application structure that makes this application possible.
The Application Structure
deep-research-endpoint/
├── src/
│ ├── app.py # Main Streamlit application
│ ├── firecrawl_client.py # Firecrawl API client wrapper
│ ├── ui.py # UI components
│ └── utils.py # Utility functions
├── requirements.txt # Dependencies
├── run.py # Simple launcher script
└── README.md # DocumentationThe deep research application follows a logical organization pattern with a modular file structure. The main directory contains a run.py script that launches the application, requirements.txt that lists all necessary Python dependencies, and a README.md file with installation and usage instructions. Inside the src directory, four Python files handle different aspects of the application: app.py serves as the main entry point and orchestrates the research process, firecrawl_client.py provides a dedicated wrapper for the Firecrawl API's deep research endpoint, ui.py contains components for the user interface, and utils.py holds utility functions for data formatting and validation.
This modular approach separates concerns and makes the code more maintainable. The app.py file initializes the Streamlit application and manages the main workflow, including processing user inputs and triggering research requests. The firecrawl_client.py module encapsulates all interaction with the Firecrawl API, isolating the complexity of making requests and handling responses. The ui.py file contains functions that generate the visual elements of the application such as the chat interface, activity display, and results formatting. Finally, utils.py provides helper functions that don't fit into the other categories. This organization pattern is common in medium-sized applications as it balances simplicity with the benefits of code separation.
Setting Up the Environment
Before we can build our deep research application, we need to set up a proper development environment with all necessary dependencies. The application requires Python 3.7 or later and access to the Firecrawl API. To get started, first clone the GitHub repository containing the example code:
git clone https://github.com/firecrawl/firecrawl-app-examples.git
cd firecrawl-app-examples/deep-research-endpointOnce you have the code, create a virtual environment to keep the dependencies isolated from your system Python installation. This step prevents potential conflicts between different Python projects on your machine:
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activateNext, install the required dependencies listed in the requirements.txt file:
pip install -r requirements.txtThe requirements file includes three main dependencies: streamlit for the web interface, requests for handling HTTP requests, and firecrawl-py for interacting with the Firecrawl API. The most important configuration step is obtaining a Firecrawl API key, which you'll need to use the deep research endpoint. You can get an API key by signing up at the Firecrawl website (firecrawl.dev). Once you have your API key, you're ready to run the application. We'll use this key in the application's sidebar later, so there's no need to set up environment variables or configuration files for this example.
Implementing the Firecrawl Client Wrapper
The FirecrawlClient wrapper serves as the foundation of our application, acting as the bridge between our Streamlit interface and Firecrawl's powerful research capabilities. This component isolates all API-related code in one place, making the rest of our application cleaner and more maintainable. By centralizing API interactions, we create a single point of contact that can be easily updated if the Firecrawl API changes in the future, without requiring modifications to other parts of our code.
from typing import Dict, Any, Callable, Optional
class FirecrawlClient:
"""Client for interacting with the Firecrawl API."""
def __init__(self, api_key: str):
"""Initialize the Firecrawl client with an API key.
Args:
api_key (str): The Firecrawl API key
"""
from firecrawl import FirecrawlApp
self.client = FirecrawlApp(api_key=api_key)
def deep_research(
self,
query: str,
max_depth: int = 3,
timeout_limit: int = 120,
max_urls: int = 20,
on_activity: Optional[Callable[[Dict[str, Any]], None]] = None,
) -> Dict[str, Any]:The deep_research method in our client wrapper will be called whenever a user submits a query through the chat interface. This method transforms the user's question and configuration settings into an API call, then processes the response into a consistent format for display. The ability to pass an activity callback function is particularly important, as it enables the real-time progress updates that make our application interactive and engaging for users.
Later in our application workflow, we'll integrate this client with Streamlit's UI components. When a user submits a research query, the app.py file will create an instance of FirecrawlClient, call its deep_research method with the appropriate parameters, and use the results to update the chat history. The client's role in formatting research results and extracting sources will be especially important when we implement the results display, as it provides clean, structured data that can be presented to users in a readable format.
Building the Streamlit Interface
Streamlit provides a straightforward way to build web interfaces in Python. Our application's UI consists of three main components: a sidebar for settings, a chat interface for submitting queries and viewing responses, and an activity display for real-time updates. In the ui.py file, we implement functions for each of these components. The setup_sidebar function creates input fields for the API key and research parameters using Streamlit's form elements like st.text_input and st.slider. For example, we create a slider for controlling research depth with st.slider("Maximum Depth", min_value=1, max_value=10, value=3), which lets users adjust how deeply the research process explores a topic.
# src/ui.py
import streamlit as st
from typing import Dict, Any, Tuple
import time
import random
def setup_sidebar() -> Dict[str, Any]:
"""Set up the sidebar with input fields.
Returns:
Dict[str, Any]: Dictionary containing user inputs from the sidebar
"""
st.sidebar.title("Configuration")
api_key = st.sidebar.text_input(
"Enter your Firecrawl API Key",
type="password",
help="Your Firecrawl API key for authentication. You can obtain this from the Firecrawl dashboard.",
)
st.sidebar.markdown("### Research Parameters")The central chat interface relies on Streamlit's chat elements. We use st.chat_input to create a text field where users enter research queries, and st.chat_message to display messages from both the user and assistant. To maintain conversation history across interactions, we implement session state management with st.session_state. This code pattern appears in the init_session_state function in utils.py:
def init_session_state():
"""Initialize session state variables if they don't exist."""
if "messages" not in st.session_state:
st.session_state.messages = []
if "processing" not in st.session_state:
st.session_state.processing = False
if "activity_container" not in st.session_state:
st.session_state.activity_container = None
if "current_sources" not in st.session_state:
st.session_state.current_sources = ""The session state stores messages, research sources, and processing status, allowing the application to maintain context between user interactions without requiring a database.
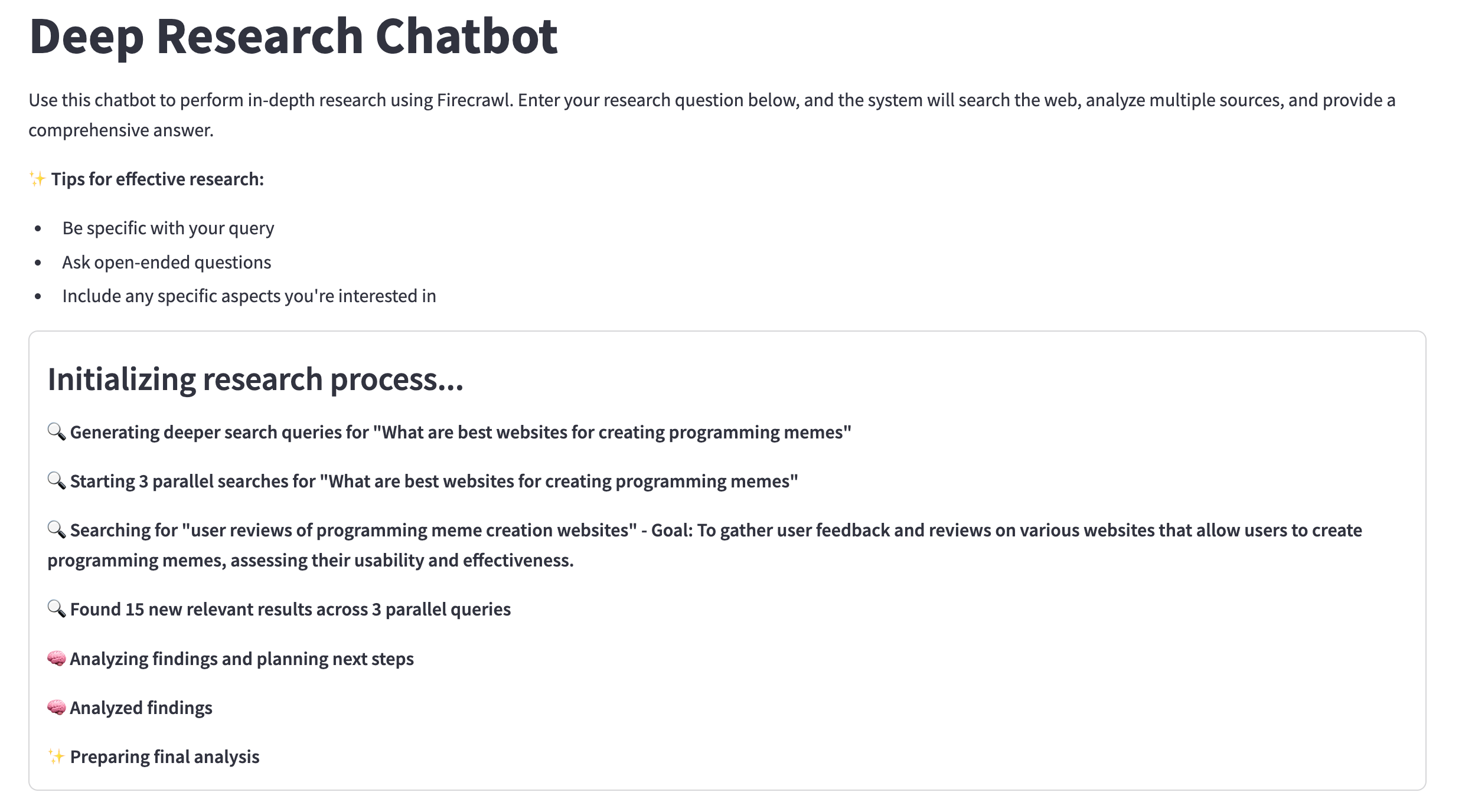
The real-time activity display is one of the most distinctive features of our interface. We create a dedicated container for activity updates using st.container(), which serves as a dynamic area where research progress appears. When an activity update arrives from the Firecrawl API, the show_activity_update function formats it according to its type and displays it in this container. For instance, search activities appear with a magnifying glass emoji, while analysis activities use a brain emoji. This visual differentiation helps users understand the current stage of the research process at a glance.
# src/ui.py
def show_activity_update(activity_data: Dict[str, Any]):
"""Display an activity update based on the activity data.
Args:
activity_data (Dict[str, Any]): Activity data from the API
"""
# Handle activity displays based on Firecrawl API structure
activity_type = activity_data.get("type", "")
message = activity_data.get("message", "")
# Map activity types to appropriate icons
icon_map = {
"search": "🔍",
"extract": "📄",
"analyze": "🧠",
"reasoning": "⚖️",
"synthesis": "✨",
"thought": "💭",
# Default icon for unknown types
"default": "🔄",
}
# Get the appropriate icon
icon = icon_map.get(activity_type, icon_map["default"])
if message:
st.markdown(f"{icon} **{message}**")
The final element of our interface is the results display, which shows both the synthesized research and source citations. We implement an expandable section for sources with st.expander("View Sources", expanded=False), allowing users to see the complete list of references without cluttering the main view.
The interface also simulates typewriter-style text appearance using the simulate_streaming_response function, which creates the impression of the assistant actively typing out the response. This effect is necessary as the Firecrawl API returns the final analysis as a single block of text, which is not ideal for our purposes.
Connecting the Components: The Application Core
The heart of our application is the app.py file, which connects all components into a cohesive system. This file contains the main() function that runs when the application starts and the perform_research() function that handles the research workflow. When a user submits a query, the application first validates the inputs using functions from utils.py, ensuring that the API key is provided and parameters are within acceptable ranges. If validation passes, the application creates an instance of FirecrawlClient and prepares a container for displaying activity updates. The workflow follows a clear sequence: receive user query, initialize research, display real-time updates, and present results.
def main():
"""Main application entry point."""
st.set_page_config(
page_title="Deep Research Chatbot", page_icon="🔍", layout="wide"
)
# Initialize session state
init_session_state()
# Set up sidebar and get configuration
config = setup_sidebar()
# Set up main UI
is_query_submitted, query = setup_main_ui()
# Display chat history
display_chat_history()
# Handle query submission
if is_query_submitted and not st.session_state.processing:
# Validate inputs
errors = validate_inputs(config)
if errors:
for error in errors:
show_error(error)
else:
perform_research(query, config)Real-time updates are implemented through the activity callback system. In the perform_research() function, we define handle_activity_update() which is passed to the Firecrawl client's deep_research() method. Each time the Firecrawl API reports a new activity (such as starting a search or analyzing results), this function receives the activity data and displays it in the dedicated container.
This single line connects the user's query and settings to the Firecrawl API and establishes the update pipeline.
When research completes, the application processes the results using the format_research_results() function from utils.py. This function takes the raw API response and transforms it into a readable format with proper markdown formatting. It separates the main analysis from the sources, allowing the application to display the analysis directly in the chat and place sources in an expandable section. The code extracts these components using string operations. This approach allows users to focus on the research findings while still having access to the supporting references.
The application's state management ties everything together, maintaining the conversation context between interactions. When research completes, the results are added to the message history stored in st.session_state.messages. This allows users to submit multiple queries in a single session. The application also handles errors gracefully, catching exceptions during the research process and displaying appropriate error messages to users. After each research cycle completes or fails, the application resets the processing state flag (st.session_state.processing = False), allowing users to submit new queries. This combination of state management, error handling, and process control creates a robust application that can handle complex research tasks while providing a smooth user experience.
Enhancing and Extending the Application
While our deep research application provides a solid foundation for AI-powered web research, several enhancements could further improve its functionality and user experience. The current implementation prioritizes simplicity and core functionality, but production applications often require additional features to address real-world needs. Adding authentication would allow the application to serve multiple users while tracking API usage per account. Persistent storage of research results would enable users to revisit previous findings without repeating the same queries, potentially using a database like SQLite for smaller deployments or PostgreSQL for larger ones.
Here are some key enhancements to consider:
- User authentication: Implement a login system to manage multiple users and track API usage
- Research history: Store previous queries and results for future reference
- Export functionality: Add options to export research results as PDF, Markdown, or Word documents
- Customizable research templates: Create predefined research configurations for common use cases
- Collaborative features: Enable sharing research sessions with team members
- Advanced visualization: Add charts and graphs to represent connections between sources
- Offline mode: Cache research results for viewing without internet connectivity
Conclusion
In this article, we've built a complete deep research application that transforms how users gather and synthesize information from the web. By leveraging Firecrawl's deep research endpoint, we've created a tool that automatically explores multiple sources, follows contextual threads, and provides comprehensive answers with proper citations. The Streamlit interface makes the research process transparent and interactive, with real-time updates keeping users informed at every step. This open-source implementation demonstrates how AI-powered research capabilities can be made accessible to everyone, providing an alternative to expensive commercial solutions.
To explore more of what Firecrawl offers, visit the Firecrawl Blog for tutorials and use cases. The Mastering Firecrawl Scrape Endpoint guide provides in-depth information on extracting structured data from websites, which can complement your research application. For advanced text processing, check out the LLMs.txt documentation, which enables powerful text analysis capabilities. By combining these tools and approaches, you can build even more sophisticated applications that transform how we interact with and learn from web content.
